Роботами.
Recommendations on the content of the file
Yandex supports the following directives:
| Directive | What it does |
|---|---|
| User-agent * | |
| Disallow | |
| Sitemap | |
| Clean-param | |
| Allow | |
| Crawl-delay | We recommend using the crawl speed setting |
| Directive | What it does |
|---|---|
| User-agent * | Indicates the robot до яких правила зберігаються в robots.txt apply. |
| Disallow | Prohibits indexing site sections або окремі pages. |
| Sitemap | Відомості про cestу до сторінки mapmap, що є зареєстрованим на сайті. |
| Clean-param | Указує на роботу, що на сторінці URL містить параметри (відповідні UTM tags), які повинні бути ignored, коли indexing it. |
| Allow | Можливі indexing site sections or individual pages. |
| Crawl-delay | Відображають мінімальний термін (в секундах) для пошуку робітника для того, щоб почати після завантаження однієї сторінки, перед початком роботи з іншою. We recommend using the crawl speed setting в Yandex.Webmaster instead of the directive. |
* Mandatory directive.
Ви знайдете потребу в Disallow, Sitemap, і Clean-param directives.
User-agent: * #specify the robots що directives є set для Disallow: /bin/ # disables links from Shopping Cart. Disallow: /search/ # disable page links of search embedded on the site Disallow: /admin/ # disables links from the admin panel Sitemap: http://example.com/sitemap # specify for the robot Clean-param: ref /some_dir/get_book.pl
Роботи з інших пошукових інструментів і послуг можуть interpretovat directives in a different way.
Note. Роботи вказують на випадок з substrings (file name або path, robot name) і не вказують на case in names of directives.
Using Cyrillic characters
Використовуючи Cyrillic alfabet не може бути зроблено в robots.txt файл і HTTP headers server.
Для домашніх Name, використовуйте Punycode . Для сторінок адреси, використовуйте той самий позначення як те, що поточний сайт структури.
Вітаю Вас друзі та передплатники мого блогу. Сьогодні на порядку денному Robots.txt, все, що Ви хотіли про нього знати, коротко, без зайвої води.
Що таке Robots.txt і навіщо він потрібний
Robots.txt потрібен для того, щоб вказати пошуковику (Яндексу, Google та ін.) як правильно (на Ваш погляд) потрібно індексувати сайт. Які сторінки, розділи, товари, статті потрібно індексувати, а які, навпаки, не потрібно.
Robots.txt це звичайний текстовий файл (з роздільною здатністю.txt), який був прийнятий консорціумом W3C 30 січня 1994 року, і який використовують більшість пошукових систем, і виглядає він зазвичай так:

Як він впливає на просування вашого сайту?
Для успішного просування сайту необхідно, щоб в індексі (базі) Яндекса та Google були лише потрібні сторінки сайту. Під потрібними сторінками я розумію такі:
- Головна;
- сторінки розділів, категорій;
- товари;
- Статті;
- Сторінки “Про компанію”, “Контакти” тощо.
Під НЕ потрібними сторінками я маю на увазі наступні:
- Сторінки-дублікати;
- Сторінки друку;
- Сторінки результатів пошуку;
- Системні сторінки, сторінки реєстрації, входу, виходу;
- Сторінки передплати (feed);
Наприклад, якщо в індексі пошуковика будуть знаходитися дублікати основних сторінки, що просуваються, то це викличе проблеми з унікальністю контенту всередині сайту, а також негативно вплине на позиції.
Де він знаходиться?
Файл зазвичай лежить в корені папки public_htmlна Вашому хостингу, ось тут:

Що Ви повинні знати про файл Robots.txt
- Інструкції robots.txt мають рекомендаційний характер. Це означає, що параметри є вказівками, а не прямими командами. Але як правило, і Яндекс і Google дотримуються вказівок без жодних проблем;
- Файл може розміщуватись лише на сервері;
- Він повинен лежати в корені сайту;
- Порушення синтаксису веде до некоректності файлу, який може негативно позначитися на індексації;
- Обов'язково перевіряйте правильність синтаксису на панелі Яндекс Вебмайстер!
Як закрити від індексації сторінку, розділ, файл?
Наприклад, я хочу закрити від індексації в Яндексі сторінку: http://сайт/page-for-robots/
Для цього мені необхідно використовувати директиву “Disallow” та URL сторінки (розділу, файлу). Виглядає це так:
User-agent: Yandex
Disallow: /page-for-robots/
Host: сайт
Якщо я захочу закрити категорію
User-agent: Yandex
Disallow: /category/case/
Host: сайт
Якщо я захочу закрити весь сайт від індексації, крім розділу http://сайт/category/case/, то необхідно буде зробити так:
User-agent: Yandex
Disallow: /
Allow: /category/case/
Host: сайт
Директива "Allow", навпаки, говорить про те, яку сторінку, розділ, файл потрібно індексувати.
Думаю, логіка побудови Вам стала зрозумілою. Зверніть увагу, що правила діятимуть лише для Яндекса, оскільки вказано User-agent: Yandex. Google же, ігноруватиме цю конструкцію і індексуватиме весь сайт.
Якщо ви хочете написати універсальні правила для всіх пошукових систем, використовуйте: User-agent: *. Приклад:
User-agent: *
Disallow: /
Allow: /category/case/
Host: сайт
User-agent- Це ім'я робота, для якого призначено інструкцію. За замовчуванням стоїть * (зірочка) - це означає, що інструкція призначена для всіх пошукових роботів.
Найбільш поширені імена роботів:
- Yandex – всі роботи пошукової системи Яндекса
- YandexImages – індексатор зображень
- Googlebot – робот Гугла
- BingBot – робот системи Bing
- YaDirectBot – робота системи контекстної реклами Яндекса.
Посилання на детальний огляд усіх директив Яндекса та Google.
Що обов'язково має бути у вищому файлі Роботс.тхт
- Налаштовано Директиву Host. У ній має бути прописано основне дзеркалоВаш сайт. Основні дзеркала: site.ruабо www.site.ru. Якщо Ваш сайт з http s, то це також обов'язково має бути вказано. Основне дзеркало в host і Яндекс.Вебмайстер має збігатися.
- Повинні бути закриті від індексації (директивою Disallow:) розділи та сторінки сайту, які не несуть корисного навантаження, а також сторінки з дублями контенту, сторінки друку, результатів пошуку та системні сторінки.
- Вкажіть посилання на sitemap.xml (мапа Вашого сайту у форматі xml).
Sitemap: http://site.ru/sitemap.xml
Вказівка головне дзеркала
Спочатку необхідно дізнатися, яке дзеркало у Вас головне за умовчанням. Для цього введіть URL вашого сайту в Яндексі, наведіть на URL у видачі та зліва внизу у вікні браузера буде вказано, з www домен або без. У цьому випадку без WWW.

Якщо домен вказано з https, то і в Robots і в Яндекс.Вебмайстер необхідно вказати https! Виглядає це так:

Послідовно заповнюйте всі потрібні поля. У міру ваших вказівок, Ви будете бачити заповнення Robots.txt директивами. Нижче описано всі директиви файлу Robots.txt.
Позначте, скопіюйтета вставте текст у текстовий редактор. Збережіть файл як "robots.txt" у кореневій директорії Вашого сайту.
Опис формату файлу robots.txt
Файл robots.txt складається з записів, кожен з яких складається з двох полів: рядки з назвою клієнтської програми (user-agent), і одного або декількох рядків, що починаються з директиви Disallow:
Директива ":" значення
Robots.txt повинен створюватись у текстовому форматі Unix. Більшість хороших текстових редакторів вже вміють перетворювати символи перекладу рядка Windows на Unix. Або ваш FTP-клієнт має вміти це робити. Для редагування не намагайтеся користуватися HTML-редактором, особливо таким, що не має текстового режиму відображення коду.
Директива User-agent:
Для Рамблера: User-agent: StackRambler Для Яндекса: User-agent: Yandex Для Гугла: User-Agent: googlebotВи можете створити інструкцію для всіх роботів:
User-agent: *
Директива Disallow:
Друга частина запису складається з рядків Disallow. Ці рядки – директиви (вказівки, команди) для даного робота. У кожній групі, що вводиться рядком User-agent, має бути хоча б одна інструкція Disallow. Кількість інструкцій Disallow не обмежена. Вони повідомляють роботу які файли та/або каталоги роботу не дозволено індексувати. Ви можете заборонити індексацію файлу чи каталогу.
Наступна директива забороняє індексацію каталогу /cgi-bin/:
Disallow: /cgi-bin/ Зверніть увагу на / наприкінці назви директорії! Щоб забороняти відвідування саме каталогу "/dir", інструкція повинна мати вигляд: "Disallow: /dir/". А рядок "Disallow: /dir" забороняє відвідування всіх сторінок сервера, повне ім'я яких (від кореня сервера) починається з "/dir". Наприклад: "/dir.html", "/dir/index.html", "/directory.html".
Записана таким чином директива забороняє індексацію файлу index.htm, що знаходиться в корені:
Disallow: /index.htm
Директиву Allowрозуміє лише Яндекс.
User-agent: Yandex Allow: /cgi-bin Disallow: / # забороняє скачувати все, крім сторінок, що починаються з "/cgi-bin" Для інших пошукових систем вам доведеться перераховувати всі закриті документи. Продумайте структуру сайту, щоб документи, що були закриті для індексування, були зібрані по можливості в одному місці.
Якщо директива Disallow буде порожньою, це означає, що робот може індексувати ВСІ файли. Як мінімум одна директива Disallow повинна бути присутня для кожного поля User-agent , щоб robots.txt вважався вірним. Повністю порожній robots.txt означає те саме, як би його не було взагалі.
Робот Рамблера розуміє * як будь-який символ, тому інструкція Disallow: означає заборону індексації всього сайту.
Директиви Allow, Disallow без параметрів. Відсутність параметрів у директив Allow , Disallow трактується так: User-agent: Yandex Disallow: # теж що і Allow: / User-agent: Yandex Allow: # теж що і Disallow: /
Використання спецсимволів "*" та "$".
При вказівці шляхів директив Allow-Disallow можна використовувати спецсимволи "*" і "$", задаючи таким чином певні регулярні вирази. Спецсимвол "*" означає будь-яку (у тому числі порожню) послідовність символів. Приклади:
User-agent: Yandex Disallow: /cgi-bin/*.aspx # забороняє "/cgi-bin/example.aspx" та "/cgi-bin/private/test.aspx" Disallow: /*private # забороняє не тільки " /private", але і "/cgi-bin/private" Спецсимвол "$".
За промовчанням до кінця кожного правила, описаного в robots.txt, приписується "*", наприклад: User-agent: Yandex Disallow: /cgi-bin* # блокує доступ до сторінок, що починаються з "/cgi-bin" Disallow: /cgi- bin # те ж саме, щоб скасувати "*" на кінці правила, можна використовувати спецсимвол "$", наприклад: User-agent: Yandex Disallow: /example$ # забороняє "/example", але не забороняє "/example.html" User -agent: Yandex Disallow: /example # забороняє і "/example", і "/example.html" User-agent: Yandex Disallow: /example$ # забороняє тільки "/example" Disallow: /example*$ # так само, як "Disallow: /example" забороняє і /example.html та /example
Директива Host.
Якщо ваш сайт має дзеркала, спеціальний робот дзеркальник визначить їх та сформує групу дзеркал вашого сайту. У пошуку братиме участь лише головне дзеркало. Ви можете вказати його за допомогою robots.txt, використовуючи директиву "Host", визначивши як її параметр ім'я головного дзеркала. Директива "Host" не гарантує вибір зазначеного головного дзеркала, проте алгоритм при прийнятті рішення враховує її з високим пріоритетом. Приклад: Якщо www.glavnoye-zerkalo.ru головне дзеркало сайту, то robots.txt для #www.neglavnoye-zerkalo.ru виглядає так User-Agent: * Disallow: /forum Disallow: /cgi-bin Host: www.glavnoye -zerkalo.ru З метою сумісності з роботами, які не повністю дотримуються стандарту при обробці robots.txt, директиву "Host" необхідно додавати в групі, що починається із запису "User-Agent", безпосередньо після директив "Disallow"("Allow") . Аргументом директиви "Host" є доменне ім'я з номером порту (80 за замовчуванням), відокремленим двокрапкою. Параметр директиви Host повинен складатися з одного коректного імені хоста (тобто відповідного RFC 952 і IP-адресою, що не є) і допустимого номера порту. Неправильно складені рядки "Host:" ігноруються.Приклади ігнорованих директив Host:
Host: www.myhost-.ru Host: www.-myhost.ru Host: www.myhost.ru: 100000 Host: www.my_host.ru Host: .my-host.ru: 8000 Host: my-host.ru. Host: my..host.ru Host: www.myhost.ru/ Host: www.myhost.ru:8080/ Host: 213.180.194.129 Host: www.firsthost.ru, www.secondhost.ru # в одному рядку - один домен! Host: www.firsthost.ru www.secondhost.ru # в одному рядку - один домен!! Host: екіпаж-зв'язок.рф # потрібно використовувати punycodeДиректива Crawl-delay
Задає тайм-аут у секундах, з яким пошуковий робот закачує сторінки з вашого сервера (Crawl-delay).
Якщо сервер навантажений і не встигає відпрацьовувати запити на завантаження, скористайтеся директивою "Crawl-delay". Вона дозволяє задати пошуковому роботу мінімальний період часу (у секундах) між кінцем завантаження однієї сторінки та початком завантаження наступної. З метою сумісності з роботами, які не повністю дотримуються стандарту при обробці robots.txt, директиву Crawl-delay необхідно додавати в групі, що починається з запису User-Agent, безпосередньо після директив Disallow (Allow).
Пошуковий робот Яндекса підтримує дробові значення Crawl-Delay, наприклад, 0.5. Це не гарантує, що пошуковий робот заходитиме на ваш сайт кожні півсекунди, але дає роботу більше свободи та дозволяє прискорити обхід сайту.
User-agent: Yandex Crawl-delay: 2 # задає тайм в 2 секунди User-agent: * Disallow: /search Crawl-delay: 4.5 # задає тайм в 4.5 секунд
Директива Clean-param
Директива виключає параметри з адресного рядка. тобто. запити, що містять такий параметр і не містять, будуть вважатися ідентичними.
Порожні рядки та коментарі
Порожні рядки допускаються між групами інструкцій User-agent .
Інструкція Disallow враховується, тільки якщо вона підпорядкована будь-якому рядку User-agent - тобто якщо вище за неї є рядок User-agent .
Будь-який текст від знака решітки "#" до кінця рядка вважається коментарем та ігнорується.
Приклад:
Наступний простий файл robots.txtзабороняє індексацію всіх сторінок сайту всім роботам, крім робота Рамблера, якому, навпаки, дозволено індексацію всіх сторінок сайту.
# Інструкції для всіх роботів User-agent: * Disallow: / # Інструкції для робота Рамблера User-agent: StackRambler Disallow:
Поширені помилки:
Перегорнутий синтаксис: User-agent: / Disallow: StackRambler А має бути так: User-agent: StackRambler Disallow: / Декілька директив Disallow в одному рядку: Disallow: /css/ /cgi-bin/ /images/ Правильно так: Disallow: / css/ Disallow: /cgi-bin/ Disallow: /images/- Примітки:
- Неприпустима наявність порожніх перекладів рядка між директивами "User-agent" та "Disallow" ("Allow"), а також між самими "Disallow" ("Allow") директивами.
- Відповідно до стандарту перед кожною директивою "User-agent" рекомендується вставляти порожній переклад рядка.
У SEO дрібниць не буває. Іноді на просування сайту може вплинути лише один невеликий файл — Robots.txt.Якщо ви хочете, щоб ваш сайт зайшов в індекс, щоб пошукові роботи обійшли потрібні сторінки, потрібно прописати для них рекомендації.
"Хіба це можливо?", - Запитайте ви.Можливо. Для цього на вашому сайті має бути файл robots.txt.Як правильно скласти файл Роботс, налаштувати та додати на сайт – розуміємось у цій статті.
Що таке robots.txt і для чого потрібний
Robots.txt – це звичайний текстовий файл, який містить рекомендації для пошукових роботів: які сторінки потрібно сканувати, а які ні.
Важливо: файл повинен бути кодований UTF-8, інакше пошукові роботи можуть його не сприйняти.
Чи зайде до індексу сайт, на якому не буде цього файлу?Зайде, але роботи можуть «вихопити» ті сторінки, наявність яких у результатах пошуку небажана: наприклад, сторінки входу, адмінпанель, особисті сторінки користувачів, сайти-дзеркала тощо. Все це вважається «пошуковим сміттям»:
Якщо результати пошуку потрапить особиста інформація, можете постраждати і ви, і сайт. Ще один момент – без цього файлу індексація сайту проходитиме довше.
У файлі Robots.txt можна задати три типи команд для пошукових павуків:
- сканування заборонено;
- сканування дозволено;
- сканування дозволено частково.
Усе це прописується з допомогою директив.
Як створити правильний файл Robots.txt для сайту
Файл Robots.txt можна створити просто в програмі Блокнот, яка за замовчуванням є на будь-якому комп'ютері. Прописування файлу займе навіть у новачка максимум півгодини (якщо знати команди).
Також можна використовувати інші програми – Notepad, наприклад. Є й онлайн-сервіси, які можуть згенерувати файл автоматично. Наприклад, такі якCY-PR.comабо Mediasova.
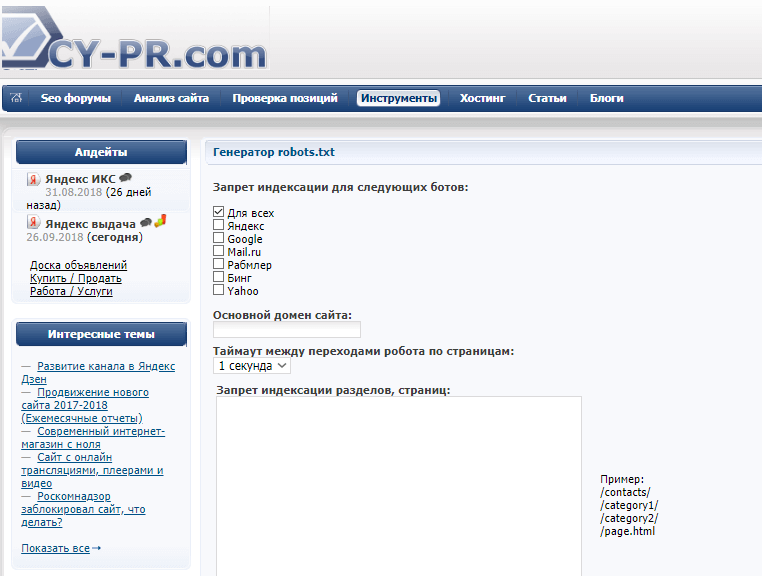
Вам просто потрібно вказати адресу свого сайту, для яких пошукових систем потрібно встановити правила, головне дзеркало (з www або без). Далі сервіс все зробить сам.
Особисто я віддаю перевагу старому «дідівському» способу – прописати файл вручну в блокноті. Є ще й «лінивий спосіб» - спантеличити цим свого розробника 🙂 Але навіть у такому разі ви повинні перевірити, чи правильно там все прописано. Тому давайте розберемося, як скласти цей файл, і де він повинен знаходитися.
Готовий файл Robots.txt повинен знаходитись у кореневій папці сайту. Просто файл без папки:

Бажаєте перевірити, чи є він на вашому сайті? Вбийте в адресний рядок адресу: site.ru/robots.txt. Вам відкриється ось така сторінка (якщо файл є):

Файл складається з кількох блоків, відокремлених відступом. У кожному блоці – рекомендації для пошукових роботів різних пошукових систем (плюс блок із загальними правилами для всіх), та окремий блок із посиланнями на карту сайту – Sitemap.
Усередині блоку з правилами одного пошукового робота відступи робити не потрібно.
Кожен блок починається директивою User-agent.
Після кожної директиви ставиться знак ":" (двокрапка), пробіл, після якого вказується значення (наприклад, яку сторінку закрити від індексації).
Потрібно вказувати відносні адреси сторінок, а чи не абсолютні. Відносні – це без www.site.ru. Наприклад, вам потрібно заборонити до індексації сторінкуwww.site.ru/shop. Значить після двокрапки ставимо прогалину, слеш і «shop»:
Disallow: /shop.
Зірочка (*) означає будь-який набір символів.
Знак долара ($) – кінець рядка.
Ви можете вирішити – навіщо писати файл із нуля, якщо його можна відкрити на будь-якому сайті та просто скопіювати собі?
Для кожного сайту необхідно прописувати унікальні правила. Потрібно врахувати особливості CMS. Наприклад, та сама адмінпанель знаходиться за адресою /wp-admin на движку WordPress, на іншу адресу буде відрізнятися. Те саме з адресами окремих сторінок, з картою сайту та іншим.
Налаштування файлу Robots.txt: індексація, головне дзеркало, директиви
Як ви вже бачили на скріншоті, першою йде директива User-agent. Вона вказує на те, для якого пошукового робота будуть йти правила нижче.
User-agent: * - правила для всіх пошукових роботів, тобто будь-якої пошукової системи (Google, Yandex, Bing, Рамблер тощо).
User-agent: Googlebot – вказує на правила пошуку павука Google.
User-agent: Yandex - правила для пошукового робота Яндекс.
Для якого пошукового робота прописувати правила першим, немає жодної різниці. Але зазвичай спочатку пишуть поради для всіх роботів.
Disallow: Заборона на індексацію
Щоб заборонити індексацію сайту в цілому або окремих сторінок, використовується директива Disallow.
Наприклад, ви можете повністю закрити сайт від індексації (якщо ресурс знаходиться на доопрацюванні і ви не хочете, щоб він потрапив у видачу в такому стані). Для цього потрібно прописати таке:
User-agent: *
Disallow: /
Таким чином, усім пошуковим роботам заборонено індексувати контент на сайті.
А ось так можна відкрити сайт для індексації:
User-agent: *
Disallow:
Тому перевірте, чи варто сліш після директиви Disallow, якщо хочете закрити сайт. Якщо хочете потім його відкрити – не забудьте зняти правило (а таке часто трапляється).
Щоб закрити від індексації окремі сторінки, потрібно вказати їхню адресу. Я вже писала, як це робиться:
User-agent: *
Disallow: /wp-admin
Таким чином, на сайті закрили від сторонніх поглядів адмінпанель.
Що потрібно закривати від індексації обов'язково:
- адміністративну панель;
- особисті сторінки користувачів;
- кошики;
- результати пошуку на сайті;
- сторінки входу, реєстрації, авторизації.
Можна закрити від індексації та окремі типи файлів. Допустимо, у вас на сайті є деякі.pdf-файли, індексація яких небажана. А пошукові роботи дуже легко сканують залиті на сайт файли. Закрити їх від індексації можна так:
User-agent: *
Disallow: /*. pdf$
Як відкрити сайт для індексації
Навіть при повністю закритому від індексації сайті можна відкрити роботам шлях до певних файлів або сторінок. Припустимо, ви переробляєте сайт, але каталог із послугами залишається недоторканим. Ви можете надіслати пошукові роботи туди, щоб вони продовжували індексувати розділ. Для цього використовується директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Головне дзеркало сайту
До 20 березня 2018 року у файлі robots.txt для пошукового робота Яндекс потрібно було вказувати головне дзеркало сайту через директиву Host. Зараз цього робити не потрібно – достатньо настроїти посторінковий 301-редирект .
Що таке головне дзеркало? Це якась адреса вашого сайту є головною – з www або без. Якщо не налаштувати редирект, то обидва сайти будуть проіндексовані, тобто дублі всіх сторінок.
Карта сайту: robots.txt sitemap
Після того, як прописані всі директиви для роботів, необхідно вказати шлях до Sitemap. Карта сайту показує роботам, що всі URL, які потрібно проіндексувати, знаходяться на певній адресі. Наприклад:
Sitemap: site.ru/sitemap.xml
Коли робот обходитиме сайт, він бачитиме, які зміни вносилися до цього файлу. У результаті нові сторінки індексуватимуться швидше.
Директива Clean-param
2009 року Яндекс ввів нову директиву – Clean-param. З її допомогою можна описати динамічні параметри, які впливають зміст сторінок. Найчастіше ця директива використовується на форумах. Тут з'являється багато сміття, наприклад id сесії, параметри сортування. Якщо прописати цю директиву, пошуковий робот Яндекса не багато разів завантажуватиме інформацію, яка дублюється.
Прописати цю директиву можна будь-де файлу robots.txt.
Параметри, які роботу не потрібно враховувати, перераховуються у першій частині значення через знак &:
Clean-param: sid&sort /forum/viewforum.php
Ця директива дозволяє уникнути дублів сторінок із динамічними адресами (які містять знак питання).
Директива Crawl-delay
Ця директива допоможе тим, у кого слабкий сервер.
Прихід пошукового робота – це додаткове навантаження на сервер. Якщо у вас висока відвідуваність сайту, то ресурс може просто не витримати і «лягти». У результаті робота отримає повідомлення про помилку 5хх. Якщо така ситуація повторюватиметься постійно, сайт може бути визнаний пошуковою системою неробочим.
Уявіть, що ви працюєте і паралельно вам доводиться постійно відповідати на дзвінки. Ваша продуктивність у разі падає.
Так само і з сервером.
Повернімося до директиви. Crawl-delay дозволяє встановити затримку сканування сторінок сайту з метою знизити навантаження на сервер. Іншими словами, ви задаєте період, через який завантажуватимуться сторінки сайту. Вказується цей параметр у секундах, цілим числом:
Robots.txt – це текстовий файл, який містить параметри індексування сайту для роботів пошукових систем.
Яндекс підтримує такі директиви:
| Директива | Що робить |
|---|---|
| User-agent * | |
| Disallow | |
| Sitemap | |
| Clean-param | |
| Allow | |
| Crawl-delay |
| Директива | Що робить |
|---|---|
| User-agent * | Вказує на робота, для якого діють перелічені в robots.txt правила. |
| Disallow | Забороняє індексувати розділи або окремі сторінки сайту. |
| Sitemap | Вказує шлях до файлу Sitemap, який розміщено на сайті. |
| Clean-param | Вказує роботу, що URL-адреса сторінки містить параметри (наприклад, UTM-мітки), які не потрібно враховувати при індексуванні. |
| Allow | Дозволяє індексувати розділи або окремі сторінки сайту. |
| Crawl-delay | Задає роботу мінімальний період часу (у секундах) між закінченням завантаження однієї сторінки та початком завантаження наступної. |
* Обов'язкова директива.
Найчастіше вам можуть знадобитися директиви Disallow, Sitemap та Clean-param. Наприклад:
User-agent: * #вказуємо, для яких роботів встановлені директиви\nDisallow: /bin/ # забороняє посилання з "Кошики з товарами". / # забороняє посилання з панелі адміністратора\nSitemap: http://example.com/sitemap # вказуємо роботу на файл sitemap для сайту\nClean-param: ref /some_dir/get_book.pl
Роботи інших пошукових систем та сервісів можуть інакше інтерпретувати директиви.
Примітка. Робот враховує регістр у написанні підрядків (ім'я або шлях до файлу, ім'я робота) та не враховує регістр у назвах директив.
Використання кирилиці
Використання кирилиці заборонено у файлі robots.txt та HTTP-заголовках сервера.
Мережева безпека