Търсене на линия
Просто следвайте дадената метрика (например метрика на Levenshtein) до следващия ред от въведения текст. С различни показатели от борсите, този метод ви позволява да достигнете оптималната скорост на работа. Але с циму чим повече к, Тим повече zbíshuetsya час работа. Асимптотичната оценка за часа е O(kn).Bitap (известен също като Shift-Or или Baeza-Yates-Gonnet, тази йога модификация като Wu-Manber)
Алгоритъм bitapТези различни модификации най-често се използват за неясни търсения без индексиране. Тази вариация е печеливша, например, в unix-полезната програма agrep, която функционира подобно на стандартната grep, но също така и от извиненията на искането за per-shock и за извеждане на възможността за улавяне на редовни фрази.Първо, идеята за това кой алгоритъм е разпространен от hulks Рикардо Баеза-Йейтсі Гастон Гонет, Публикува втората статия през 1992 г.
Оригиналната версия на алгоритъма може да бъде променена само отдясно чрез замяна на символи и всъщност да се изчисли броят на Подгъване. Ale trishki pіznіshe слънце уі Уди Манбере поискал промяна на кой алгоритъм за изчисляване на паричната сума Левещайн, тогава. те въведоха подгрупа от вложки и vidalene, те разработиха първата версия на помощната програма agrep на основата на йога.

Резултатна стойност
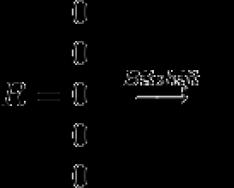
Де к- много извинения, й- символен индекс, с x - маска за символа (в маските една по една се поставят на позиции, които съответстват на позициите на дадения символ във входа).
Zbіg аbo razbіzhnіst zaputu се определя от оставащия бит на резултантния вектор R.
Осигурена е висока скорост на роботизирания алгоритъм за изчисляване на паралелизъм на битове - за една операция е възможно да се изчислят над 32 и повече бита наведнъж.
За когото изпълнението е тривиално, трябва да е повече от 32. Ширината на стандартния тип вътр(На 32-битови архитектури). Можете да спечелите и видове голяма гъвкавост, но можете също така да подобрите алгоритъма на робота.
Независимо от тях, асимптотичният час на роботизирания алгоритъм O(kn) zbígaêtsya с такъв линеен метод, vin значително shvidshe с дълги искания и броя на помилванията кнад 2.
тестване
Тестването е извършено върху текстове от 3,2 милиона думи, средният брой думи е 10.Точен Пошук
Poshuk час: 3562 msPoshuk за препратки към метриката на Левещайн
Час на шега при k=2: 5728 msЧас на шега при k=5: 8385 ms
Търсете корекции на алгоритъма Bitap с модификации на Wu-Manber
Час на шега при k=2: 5499 msЧас на шега при k=5: 5928 ms
Очевидно е, че просто изброяване на различни показатели, на базата на алгоритъма Bitap, може да се използва за голям брой помилвания. к.
Тим не е по-малко от, сякаш говори за шега в предстоящите текстове на голямата псувня, тогава един час на шега може значително да се ускори, като ограби предната част на такъв текст, който също се нарича индексиране.
Алгоритми за размито търсене за индексиране (офлайн)
Особено всички алгоритми в размитото търсене за индексиране са тези, че индексът ще бъде зад речника, сгънат зад действителния текст или списъка със записи във всяка база данни.Алгоритмите използват различни подходи за решаване на проблема - някои използват метода за точно търсене, а други използват показатели за мощност, за да насърчат различни пространства на структури и т.н.
Nasampered, първо, за следващия текст ще има речник, който ще отмъсти за думите на тази йога позиция в текста. Можете също така да подобрите честотата на думите и фразите, за да подобрите качеството на резултатите от търсенето.
Казват, че индексът, подобно на речник, е напълно очарован от гатанка.
Тактико-техническа характеристика на речника
- Външен текст - 8,2 гигабайта материали в библиотеката на Мошков (lib.ru), 680 милиона думи;
- Разширяване на речника - 65 мегабайта;
- Брой думи - 3,2 милиона;
- Средната дожина на една дума е 9,5 символа;
- Средна квадратична дължина на дума (може да бъде основна при оценка на някои алгоритми) - 10.0 символа;
- Азбука - големи букви A-Z, без E (за опростяване на някои операции). Думи, които заместват символи извън азбуката, не са включени в речника.

Алгоритъм за разширяване на селекцията
Този алгоритъм често се среща в системите за проверка на правописа (т.е. в програмата за проверка на правописа "ах"), там речникът е малък, в противен случай работоспособността не е основният критерий.Започвайки от началото на проблема за размитото търсене до проблема за точното търсене.
От външната заявка ще има анонимни помилвания, за защита на кожата след това ще извършим точно търсене с речника.

Един час йога работа да лежиш в числото k извинения и да чакаш азбуката А да се разшири, а при бинарно търсене на речник да стане:
Например, когато k = 1И думите на дожини 7 (например „Крокодил“) в руската азбука на безсмислените думи за прошка ще бъдат близо 450, така че е необходимо да добавите 450 думи към речника, което е общоприето.
Але вече изостава k = 2 rozmír такъв множител ставаме над 115 хиляди опции, което ще ви позволи да сортирате малък речник или 1/27 в нашия ум и след това часът на работа ще бъде страхотен. Ако е така, не е необходимо да забравяте за тези, че за кожата на такива думи е необходимо да търсите точната дума от речника.
Характеристика:
Алгоритъмът може лесно да се модифицира, за да генерира опции за помилване според определени правила, като преди това не се интересува от никаква предна обработка на речника и, очевидно, допълнителна памет.Възможни подобрения:
Възможно е да се генерират не всички безлични думи за "извинение", но само тези от тях, като най-мощните, могат да се използват в реална ситуация, например думи с подобрени правописни извинения и набори.Този метод на изобретения е направен от дълго време и е най-широко използваният, така че прилагането му е изключително просто и осигурява добра производителност. Алгоритъмът се основава на принципите:
„Ако думата А се комбинира с думата Б за уреждане на много помилвания, тогава с голяма честота те ще искат да имат една голяма сделка от дожини Н.“
Числата от порядъци до N и се наричат N-грами.
Под часа на индексиране думата се разделя на такива N-грами и след това думата се отвежда до списъците за кожи s и N-грами. За един час търсенето също се разделя на N-грами и кожата от тях се извършва последващо изброяване на списъка с думи, за да се изчисти такава последователност.

Най-често vikoristovuvanimi на практика е триграми - pіdryadki dovzhini 3. Vybіr bolshy znachennya N води до obezhennya на минималния срок на думата, ако могат да бъдат показани повече помилвания.
Характеристика:
Алгоритъм N-gram, за да знаете в пълен obsyazі mozhliví думи с извинения. Вземете например думата VOTKA и разпространете йога върху триграми: IN T KA → VO TПрофесионалист TПреди T KA - можете да запомните, че всички те отмъщават за помилването на T. В този ранг думата "ГРАД" няма да бъде известна, фрагментите няма да отмъстят за същото с тези триграми и не прекарвайте списъците с vodpovidni їm. В този ранг, колкото по-малко дожина думи и колкото повече извинения в новия, има по-голям шанс да не се изразходват до последните N-грами от списъците и няма да има резултат.В същото време методът N-gram запълва последното пространство за избор на метрики от високо ниво с достатъчен авторитет и сгъване, а след това трябва да платите за него - с тази вариация необходимостта от последователно изброяване е близо до 15 % от речника, който е богат за речника на великия гу.
Възможни подобрения:
Можете да разделите хеш-таблицата на N-грамите по последната дума и позицията на N-грамите в думата (модификация 1). Като дожина на шукана дума, че запоза не може да се повдигне повече к, а позициите на N-грами в дума могат да се променят само с k. Също така ще е необходимо да се провери само таблицата, да се променят позициите на N-грамите в думата и да се въведе таблицата на zliva и k таблицата на дясната ръка, tobto. от всички 2k+1Сусидни маси.
Все още можете да промените броя на думите, необходими за преглед на множителя, като разделите таблиците според предишните думи и в подобен ранг, като прегледате само съдилищата 2k+1таблици (модификация 2).
Този алгоритъм е описан в статията Boytsov L.M. "Heshuvannya z подпис". Виното се основава на очевидно зададената "структура" на думата по отношение на битовия ред, който печели като хеш (подпис) в хеш-таблицата.
При индексирането такива хешове се броят към дермалния хеш и таблицата се въвежда според списъка с речникови думи на хеша. След това, за един час, ще попитам, за заявката, хешът се изчислява и всички останали хешове се сортират, които се броят през уикенда не повече от по-ниски в k бита. За дермални такива хешове списъкът с подходящи думи е сортиран.
Процесът на изчисляване на хеша - битът на кожата на хеша се присвоява на група символи от азбуката. Бит 1 в позиция азхешът означава, че действителната дума има символа z i-тогрупова азбука. Редът на буквите в една дума е абсолютно безсмислен.

Ако видите един знак или не промените хеш стойността (както в думите, знаците от тези групи от азбуката бяха пропуснати), или другата група от битове ще се промени на 0. При вмъкване, по подобен начин, всеки един бит е зададен на 1, или няма да променям. При замяна на символи и трите неща са по-сгъваеми - хешът може или да остане непроменен, или да се промени на 1 или 2 позиции. При пренареждане на същите промени те не се вземат предвид, тъй като редът на символите, когато хешът е променен, както е отбелязано по-рано, не се обръща. В този ред, за пълно покритие на k помилвания, е необходимо да се промени най-малкото 2kхеш бит.

Един час работа, по средата, с k „непълни“ (вмъквания, отдалечени и транспозиции, както и малка част от промените) извинения: 
Характеристика:
Освен това, когато замените един символ, два бита могат да бъдат променени наведнъж, алгоритъмът, който прилага, например, не изпълнява повече от 2 бита наведнъж, всъщност не можем да видим общия резултат поради броя на цифри (депозиране според хеша към азбуката) части от думи с две замени (и колкото по-голямо е разширяването на хеша, толкова по-често замяната на символа ще доведе до два бита преди създаването и резултатът ще се повтаря по-малко) . Дотогава този алгоритъм не позволява префиксно търсене.BK-дървета
дърво Буркхард-Келере метрични дървета, алгоритмите за такива дървета се основават на мощността на метриката, показателна за неравномерността на трикутника:Силата Tsya позволява на метриките да установяват метрични пространства с достатъчно пространство. Такова метрично пространство не е obov'yazkovo є евклидов, така че, например, показатели Левещайні Дамерау-Левенщайнуспокоявам неевклидовипространство. Въз основа на тези авторитети може да се индуцира структурата на данните, която създава усещане за такова метрично пространство, което е дървото на Баркхард-Келер.

Полипшение:
Възможно е да се спечели осъществимостта на такива показатели за отчитане между борсите, като се зададе горната граница, която ще увеличи сумата от максималното разстояние до върха на пика и полученото разстояние, което ще позволи на процеса да ускори процес:тестване
Тестът е извършен на лаптопи с Intel Core Duo T2500 (2GHz/667MHz FSB/2MB), 2Gb RAM, OS - Ubuntu 10.10 Desktop i686, JRE - OpenJDK 6 Update 20.
Тестването беше извършено въз основа на победите на Дамерау-Левенщайн и броя на помилванията k = 2. Разширяване на индекса на показанията наведнъж от речника (65 Mb).
Разширение на индекса: 65 Mb
Пошук час: 320ms / 330ms
Повторяемост на резултатите: 100%
N-грам (оригинал)
Разширение на индекса: 170 MbИндексен час: 32 s
Час на Poshuk: 71ms / 110ms
Повторяемост на резултатите: 65%
N-грам (модификация 1)
Разширение на индекса: 170 MbИндексен час: 32 s
Час на Poshuk: 39ms / 46ms
Повторение на резултатите: 63%
N-грам (модификация 2)
Разширение на индекса: 170 MbИндексен час: 32 s
Час на Poshuk: 37ms / 45ms
Повторяемост на резултатите: 62%
Разширение на индекса: 85 Mb
Работен час за индекс: 0.6 s
Пошук час: 55 ms
Повторяемост на резултатите: 56,5%
BK-дървета
Разширение на индекса: 150 MbИндекс час: 120 s
Пошук час: 540 ms
Повторение на резултатите: 63%
заедно
Повечето алгоритми за размити търсения с индексиране не са наистина сублинейни (така че да е възможен асимптотичен час работа) O(log n)или по-ниско), че техните swidkіst roboti звучат без средна лъжа н. Тим не е по-малко, много polypshennya, че doopratsyuvannya ви позволяват да достигнете достатъчно малък час работа, за да научите в името на големи задължителни речници.Съществуват и безлични, различни и неефективни методи, основи, повече или по-малко, за адаптирането на различни, сега-nebud zastosovuvannyh tehnіkí і priyomіv към тази предметна област. Сред тези методи е адаптирането на префиксни дървета (Trie) към неясна шега, като че правя поза с уважение чрез нейната малка ефективност. Алгоритми, които се основават на оригинални подходи, например алгоритъмът Маас-Новак, което въпреки че може да е сублинеен асимптотичен час работа, но е изключително неефективен поради големите константи, които следват такава оценка на времето, както се вижда от привидно големия размер на индекса.
Практическата вариация на алгоритмите за размито търсене в реални системи за търсене е тясно свързана с фонетичните алгоритми, лексикалните произходни алгоритми - виждане на основната част на различни словоформи на една и съща дума (например Snowball и Yandex mystem дават такава функционалност), както и класиране по основна статистическа информация, както и множество сгъваеми сложни показатели.
- V_dstan Levenshtein (с vіdsіkannyam и префикс вариант);
- V_dstan Damerau-Levenshtein (с vіdsіkannyam и префикс вариант);
- Bitap алгоритъм (Shift-OR/Shift-AND с модификации на Wu-Manber);
- Алгоритъм за разширяване на селекцията;
- N-грам метод (оригинален и модифициран);
- Метод за хеширане на подписа;
- BK дърво.
Varto уважение, че в процеса на култивиране на tsієї тези, които се появиха deakі vlasnі pratsyuvannya, scho позволяват за един порядък да прекарате един час, питайки за сметка на мирното увеличение на индекса и ефективния обмен на свобода при избора на показатели . Ale tse вече zovsіm іnsha іstoriya.
Семантично ядро
За да се развива успешно, което повишава видимостта на сайта в днешните реалности, е необходимо постепенно да се разширява семантичното ядро. Един от най-добрите начини за разширяване е да изберете ключовите думи на конкурентите.
Днес не е лесно да се прецени семантиката на конкурентите, т.к Има анонимни услуги, като платени и без разходи.
Списък на не-костов:
- megaindex.ru - инструмент "Видимост на уебсайта".
- xtool.ru - всички услуги, които показват и ключовите думи, по които е класиран сайта
Списък с плащания:
- spywords.ru - подходящ за Yandex и Google
- semrush.ru - само Google
- prodvigator.ua - украински аналог на spywords.ru
В допълнение към услугите можете да използвате и ръчния метод, бази за разбиване на заглавието и описанието в n-грами, след което на изхода ще се появи допълнителен списък с фрази.
N-грама - последователност от n елемента. Всъщност N-грамата по-често се чува като ниска дума. Често се нарича последователност от два последни елемента биграма, се нарича последователността от три елемента триграма. Не по-малко от няколко и повече елемента се обозначават като N-грама, която N се заменя с броя на следващите елементи.
Нека да разгледаме методологията зад кулисите:
- Vivantage заглавие (описание) на състезателите. Можете да се свържете с Screaming Frog SEO за помощ.
- Текстовият редактор има ясен списък на написаното, под формата на служебни части от филма, под формата на знаци и други думи. Въвеждам във възвишения текстов текстов редактор функцията „търсене и промяна“ (горещ клавиш ctrl + H), използвайки редовни вирази:
- Ние избираме да използваме n-грам и задаваме честотата на поне една. Най-оптималният вариант е с всички триграми и 4 грама:

- Отнеми резултата:

Стовпецброяпокажете броя на повторениятан-грам, стовпецчестота -Честотан-грамове.
Тъй като взехме списъка с фрази, е необходимо да анализираме и изберем подходящи ключови думи, за да разширим семантичното ядро. Докладът може да бъде разпознат от официалния клон на нашия блог.
Групиране на заявки
Също така е важно да разберете как ядрото на конкурентите е групирано семантично, т.к Tse dopomogaê правилно rozpodіliti ключови фрази отстрани на сайта.
Поради тази причина, след като сме формирали окончателния списък със заявки, трябва да вземем предвид съответните страни и позиции на конкурентите (можете да използвате seolib.ru за помощ), след което ще ги сравним с нашите групи. Ясно е, че състезателят заема добра позиция и когато това групиране е различно от нашето (например състезателят има отделен ред от друга страна, а ние също имаме заявка да седнем от едната страна), е необходимо да се обърнете в името на уважението и да погледнете страничните знаци на площадката на вашия сайт.
Изглежда като малка част от групирането на интелигентния сайт на този його конкурент.
Както може да се види от таблицата, site.ru избра една целева страница за всички ключови думи. При състезател за cimis и заявки, различни страни се класират и заемат ТОП или близо до ТОП позиции. Поради тази причина можете да създадете нетривиална висновка, която трябва да разгледате групирането на site.ru, трябва да създадете зона за ключови фрази с думата „фасада“.
Yakіst tekstіv
Първото е най-важното, за което трябва да се обърне внимание при анализиране на текстовете на конкурентите, цената не е за броя на складовете (броят на входовете, текстът е ограничен), а в името на смисъла на дума - най-основната информация, която състезателят ще разпространява и като вина.
Нека да разгледаме много приложения.
Приемливо е да сте ангажирани с доставката на билети и на основната страна в текста и да гарантирате тяхната актуалност. Например така:
Служба за доставкасайт. enгарантира запазването на букети за внасяне в студения сезон на рок.
И задната ос на един от състезателите:
За нас е лесно да заменим ароматните композиции, за това гарантираме 100% връщане на стотинки, тъй като свежестта на билетите се нарича sumniv.
Гаранцията на конкурента е без пари, но има по-добра, по-ниска абстрактна гаранция.
Нека разгледаме още един пример - текста отстрани на категорията "керамични плочки" към онлайн магазина:

Този текст не носи никакво изтъркано ударение, базирано на смисъл, сочна вода. Shvidshe за всичко, lyudina, yak дойде на сайта и priymaє rіshennya за kupіvlyu, искате да знаете за предимствата на продукта и че mozhliví komplektacії, natomіst спечели otrimuє bezgluzdiy nabіr simvolіv.
Сега нека да разгледаме текста на един състезател:

Този текст е крив, т.к накратко говори за видимостта на плочките и ви помага да разберете как да изберете правилно.
По този начин, сравнявайки текстовете на конкурентите с вашите собствени, можете да вземете много основна информация, като помощ на копирайтърите при съставяне на технически спецификации.
Релевантност на текстовете
Продължавайки темата за качеството на текстовете, е невъзможно да не бъдем докоснати от тяхната уместност. Днес, за да бъде текстът актуален, не е достатъчно да въведете ключови думи. За да повишите уместността на страницата и да не спамите текста, е необходимо да подчертаете думите, свързани с темата.
Оценявайки релевантността на текста към заявката, системата за търсене анализира наличието на ключови думи и допълнителните думи, обозначаващи текста по този начин. Например, ако напишем текст за слон, тогава с думите можете да използвате „хобот“, „бивни“, „природа“, „зоопарк“. Ако текстът е за чек фигурата на слон, тогава такива думи ще бъдат: фигура, чек, дама и др.
Можете да изберете най-подходящия списък от думи за вашата заявка в текстовете на конкурентите. За кого е необходимо да растат крака:
- Копирайте всички текстове от ТОП-10 за необходимата RF мощност в други текстови файлове.
- От текстовете можете да видите служебните части на езика, препинателните знаци и числата (разгледахме го по-рано).
- Vibudovuёmo думи в един ред - vikoristovuєmo функцията "търсене и промяна" от обикновените вирази. Заменен с \n.
- Освен това е необходимо всички словоформи да се приведат в нормалната дума (леми). За кого можете да използвате услугата https://tools.k50project.ru/lemma/. В полето, където трябва да добавите списък с думи от файла на кожата, щракнете върху бутона „Нека меметизира и показва в изгледа на csv таблица“. Резултатът може да има 10 файла с леметизирани думи.
- Можем да видим дублирани думи във файла на кожата.
- Комбиниране на думи от файлове в един списък.
- Сега трябва да създадете честотен речник. За това изтриване списъкът се добавя към услугата https://tools.k50project.ru/lemma/ и е възможно да натиснете „насърчете честотния речник да гледа CSV“.
- Нашият списък с думи е готов:

Ако честотата е 10, това означава, че дадената дума е победила на всички 10 сайта, ако е 8, тогава само на 8 и т.н. Препоръчително е да изберете думите с най-висока честота, но в средата на думите, които рядко са неясни, можете да намерите решението.
По такъв прост начин можете да вземете списък с тематични думи за сгъване на TK копирайтъри.
Както можете да видите, конкурентите имат много важен източник на информация, за да помогнат за по-доброто оптимизиране на вашите сайтове. В тази статия разгледах далеч от всички аспекти и в бъдеще ще продължа да пиша за тези, които могат да бъдат взети от вашите конкуренти.
Абонирайте се за бюлетина,
прегледани н-грами като фиксация на съвременната реалност като моделна конструкция. Обажданията на моделите са разглобени н-грама и формални граматики. Това е адски голямо уважение към недоликите и протириччия, пов'язани от використанням имовиринисних модели.
Вход
Да започнем с официална среща. Нека задачите изпеят последната азбука VT={wi), де wi- Специален символ. Анонимни ланзюжки (рядки) от края на века, които се образуват от символите на азбуката VT, наречена моя по азбуката VTи означават L(VT). Креми ланцюжок от филма L(VT)назовавайки ме с моята любов. В твоя ад н-грам в Абец VTнаречен lanzyuzhok dozhina н. н-grama може да се zbígatisya z yakimos vyslovlyuvannyam, но yogo в ред или zagalí не влизайте преди L(VT).
Ние ще ръководим много приложения н-грам.
3. , н-грами руски. // Справочна колекция.
4. Гланц.Медико-биологична статистика Пров. от английски за червено. V. М., 1999.
5. Дескриптивна лингвистика. Передмов към книгата на Г. Глисън "Въведение в дескриптивната лингвистика". М., 1959.
6. Теоретична и приложна лингвистика. М., 1968.
8. , Пауза по време на автоматичен синтез на филм. // Теория и практика на съвременните постижения. М. 1999 г.
9. Мински М.Топлина и логика на познавателното непознато. // Ново в чуждата лингвистика. Вип. XXIII. М., 1988.
10. Слобин Д., Грийн Дж.Психолингвистика. М., 1976
11. Теория на неподвижността. М., 1972.
12. Фу До.Структурни методи за разпознаване на изображения. М., 1977.
13. Харис Т.Теория за випадичните процеси, които са безсмислици. М., 1966.
14. Брил Е. та ин.отвъд н-grams: Може ли езиковата сложност да подобри езиковото моделиране?
15. Бут Т.Вероятностно представяне на формални езици. // IEEE Annual Symp. Превключване и теория на автоматите. 1969 г.
16. Йелинек Ф.Самоорганизирано езиково моделиране за разпознаване на реч. // Четения в разпознаването на реч. 1989 г.
17. ДжеЛинек Ф., Лафърти Дж.Изчисляване на вероятността за първоначално генериране на подниз чрез стохастична контекстно-свободна граматика. // Компютърна лингвистика, кн.
18. Харис З.С.Метод в структурната лингвистика. Чикаго, 1951 г.
19. Лашли К.Проблем със серийния ред в поведението. // Психолингвистика: книга с четения, N. Y. 1961.
20. Шлезингер Е.Структура на изречението и процес на четене. Мутон. 1968 г.
21. Шийбър С.Доказателства за предконтактна свобода на естествения език. // Езикознание и философия, кн.
22. Сола басейн I.Тенденции в анализа на съдържанието днес. // Психолингвистика: книга с четения, N. Y. 1961
23. Щолке А., Сегал Дж.Вариант на n-грам вероятности от стохастични безконтекстни граматики. // Сборник на 32-та годишна среща на ACL. 1994 г.
Уикиизточник N-грам
Общи използване на N-грам
- данни за групирането на поредица от сателитни спътници на Земята от космоса, така че да можем да видим като конкретни части от Земята в изображението,
- търсене на генетични последователности,
- в галерията на генетиката, те са победители, за да определят кои специфични видове същества са избрали ДНК
- в компютърна хватка
- s vikoristannyam N-gram, звукови индексирани данни, свързани със звук.
Също така, N-грамите са широко засадени в образци на естествения език.
N-gram доносник за нуждите на естествената обработка на филми
В областта на обработката на естествени филми, N-грамите се използват главно за прехвърляне на базата на филмови модели. Известно е, че N-грамният модел на развитието на възможността за оставащата дума на N-грамата е всичко отпред. При избора на правилния подход за моделиране езикът се прехвърля, така че когато се появи думата на кожата, има по-малко от първите думи.
Още stosuvannya N-grams е плагиатство. За да разделите текста на малки фрагменти, представени от n-грами, те могат лесно да бъдат сравнени един с един и по този начин да се премахнат стъпките на сходство на контролните документи. N-грам, често успешно оправдан за категоризиране на текста на този филм. В допълнение, те могат да бъдат усукани за създаване на функции, като даване на възможност да се вземат знания от текстови данни. Използвайки N-грама, можете ефективно да познавате кандидатите за замяна на думите с извинения за правопис.
Научноизследователски проекти на Google
Последните центрове на Google имат доказани N-грамови модели за широка гама от продажби и разпространение. Преди тях могат да се видят такива проекти като статистически превод на един език на друг език, разпознаване на език, коригиране на правописни извинения, тълкуване на информация и много други неща. За целите на тези проекти бяха избрани текстовете от корпуса, за да се отмъстят трилион думи.
Google не успя да създаде свой собствен първичен корпус. Проектът се нарича Google teracorpus и е на стойност 1 024 908 267 229 думи, взети от публично достъпни уебсайтове.
Методи за определяне на n-грамове
На връзката с частичния брой N-грами за различни задачи, необходимият излишен и умен алгоритъм за изучаването им от текста. Допълнителният инструмент за превод на n-грами се дължи на способността на майката да работи с невъобразим размер на текста, да работи бързо и ефективно за извличане на налични ресурси. Є k_lka методи за изследване на N-грами от текста. Тези методи се основават на различни принципи:
Бележки
див. също
Фондация Уикимедия. 2010 г.
- n-tv
- N-кадхерин
Чудя се какво е "N-gram" в други речници:
грам- (Fr. Gramme, от гръцки Gramma ориз). Единичен френски. wag = wag 1 кубичен сантиметър дестилирана вода = 22,5 роса. части. Речник на нешомоничните думи, които са достигнали запасите на руския език. Chudinov A.N., 1910. GRAM само на света vaga във Франция ... Речник на чужди думи на руски език
грам- грам, червено. мн. gramіv i е допустимо (в общата промо след цифра) грам. Сто g (грам). На захист нова форма червена. водминка мн. Броят на грамовете е написан от руския писател К. Чуковски. Ос на писане на вино в книгата „Живот като живот“: ... Речник на трудния език и глас в съвременния руски език
грам- ГРАМ, грам, човече. (Вид гръцки. граматичен знак, буква). Основната единица за вода в метричната система е входът, който е най-важната ваза от 1 кубичен сантиметър вода. Един грам е близо до 1/400 паунда. ❖ Грам атом (физ.) броят грамове реч, който е равен на една атомна ваза. Тлумачен речник на ушаков
грам-рентген- грам рентгенова снимка / n, грам рентгенова снимка / на, rd. мн. грам рентген та грам рентген … Добре. Окремо. Чрез тире.
грам- Gram, най-простата дума може да бъде b і не предизвиквайте извинения в речника, yakbi не две мебели; първо, ако искате да блеснете с абсолютно правилна моя, след това, като дойдете в магазина, накарайте продавача да се поправи: Обадете ми се двеста грама (не ... ... Речник на прощения на руски език
ГРАМ-АТОМ- GRAM ATOM, количество на елемента, маса на всеки, в грамове, dor_vnyuє yogo ATOMNIY MACE. Його е заменен от единицата на системата СІ мол. Например, един грам атом вода (Н, атомно тегло = 1) е равен на един грам. b>ГРАМОВ ЕКВИВАЛЕНТ, какво е в грамове от това... ... Научно-технически енциклопедичен речник
грам- GRAM, a, червено. мн. грам и грам, човече. Единична маса в дузина системи от записи, една хилядна от килограма. Нито грам (ни) от какво (розг.) анитрохи, нищо не се знае. Имат tsієї хора (ní) ní грам съвест. | дод. грам, ах, ой. Облачно…… Тлумачен речник на Ожегов
грам- А; мн. rd. грамове и грамове; м. [френски. грам] Единица за маса в метричната система от записи, една хилядна част от килограма. ◊ Нямаме нито грам. Анитрохи, не знам. Кой аз. нито грам лъжа. Нито грам съвест от никого. * * * грам (френски ... Енциклопедичен речник
Грам Зенов Теофил- (Gramme) (1826-1901), електроинженер. Роден в Белгия, отгледан във Франция. След като взе патент за практичен присъединителен електрически генератор с пръстеновидна котва (1869). Заспиване promyslov virobnitstvo електрически машини. * * * ГРАМ Зеноб… … Енциклопедичен речник
грам атом- количество реч в грамове, числено равно на нейното атомно тегло. Терминът не се препоръчва да се живее. В SI много реч се върти около бенките. * * * ГРАМ АТОМ ГРАМ АТОМ, количество реч в грамове, числено равно на едно атомно тегло (разд. … Енциклопедичен речник
грам молекула- количество реч в грамове, числено равно на нейното молекулно тегло. Терминът не се препоръчва да се живее. В SI много реч се върти около бенките. * * * ГРАМ МОЛЕКУЛА ГРАМ МОЛЕКУЛА, количество реч в грамове, числено равно на його… Енциклопедичен речник