Skin blog dává svůj důkaz této snahy. Proto se nováčci v pokey průmyslu často ztrácejí, takže to vypadá takto:
Jaký druh robotického ex ti?
Soubor robots.txt nebo jinak Indexový soubor— primární textový dokument kódovaný v UTF-8 je vhodný pro protokoly http, https a také FTP. Soubor je dán vyhledávacím robotům za účelem: které stránky/soubory jsou skenovány. Pokud soubor obsahuje znaky, které nejsou v UTF-8, ale v jiném kódování, vyhledávací roboti je mohou zpracovat nesprávně. Pravidla uvedená v souboru robots.txt jsou platná v závislosti na hostiteli, protokolu a čísle portu, kde se soubor nachází.
Soubor musí být nainstalován v kořenovém adresáři ve formě primárního textového dokumentu a je přístupný na adrese: https://site.com.ua/robots.txt.
V jiných souborech je obvyklé umístit ikonu BOM (Byte Order Mark). Toto je znak Unicode, který se používá k označení sekvence v bajtech při čtení informací. Symbol kódu je U+FEFF. Značka sekvence bajtů v souboru robots.txt je ignorována.
Google nastavil limity na velikost souboru robots.txt – nejste povinni zadat více než 500 KB.
Garazde, protože potřebujete nějaké technické podrobnosti, soubor robots.txt je popsán ve formě Beckus-Naur (BNF). V tomto případě jsou revidována pravidla RFC 822.
Při analýze pravidel ze souboru robots.txt vydají vyhledávací roboti jednu ze tří instrukcí:
- soukromý přístup: skenování jiných prvků webu není dostupné;
- univerzální přístup: vše lze skenovat;
- plný plot: robot nemůže nic skenovat.
Při skenování souboru robots.txt roboti zjistí následující typy odpovědí:
- 2xx - skenování bylo úspěšné;
- 3xx Zvukový robot sleduje přesměrování dat, ale neodmítá ostatní vstupy. Nejčastěji má robot pět testů k zachycení signálu, odečtením od řádku 3xx, pak je zaregistrována chyba 404;
- 4xx - Vyhledávací robot oceňuje, že můžete skenovat celý web;
- 5xx - je vyhodnoceno jako včasné selhání serveru, skenování je zcela zablokováno. Robot bude pokračovat v procházení souboru, dokud neodmítne další vstup. Vyhledávací robot Google dokáže určit, zda je výstup různých stránek na webu upraven správně nebo nesprávně, takže místo odpovědí 404 stránka vytvoří verzi 5xx, v takovém případě bude stránka Call in s řádkovým kódem 404.
Stále není známo, jak je generován soubor robots.txt, který je nepřístupný kvůli problémům serveru s přístupem k internetu.
Nakonec požadovaný soubor robots.txt
Někdy například roboti nejsou dobří v poskytování:
- stránky se speciálními informacemi o klientech na webu;
- stránky s různými formami sdílení informací;
- zrcadla webových stránek;
- stránky s výsledky vyhledávání.
Důležité: protože se stránka nachází v souboru robots.txt, je jasné, že se objeví, pokud na ní byla nalezena zpráva na webu nebo na externím zdroji.
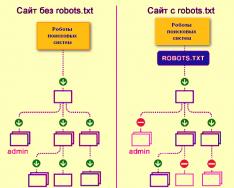
Takto roboti vyhledávačů procházejí web se souborem robots.txt nebo bez něj:

Bez robots.txt mohou být informace zachycené od třetích stran ztraceny ze zobrazení, a tím utrpíte vy i web.
Takto robot vyhledávacích systémů stáhne soubor robots.txt:

Google na webu identifikoval soubor robots.txt a zná pravidla pro procházení stránek na webu
Jak vytvořit soubor robots.txt
Použijte Poznámkový blok, Poznámkový blok, Sublime nebo jakýkoli jiný textový editor.
User-agent - vizitka pro roboty
User-agent – pravidlo o těch robotech, kteří se musí řídit pokyny popsanými v souboru robots.txt. V současné době je viditelných 302 vyhledávacích robotů
Promluvme si o těch, u kterých určujeme pravidla robots.txt pro všechny vyhledávací roboty.
Pro Google je hlavním robotem Googlebot. Pokud chceme chránit něco jiného, bude záznam souboru vypadat takto:
V tomto případě budou všichni ostatní roboti procházet obsah na základě svých pokynů pro zpracování prázdného souboru robots.txt.
Pro Yandex je hlavním robotem... Yandex:
Další speciální roboti:
- Mediální partneři – Google- pro službu AdSense;
- AdsBot-Google- Pro kontrolu rámu celé strany;
- Obrázky Yandex- indexátor Yandex.Images;
- Obrázek prohledávače Googlebot- Pro obrázky;
- YandexMetrika- robot Yandex.Metrica;
- YandexMedia- Robot, který indexuje multimediální data;
- YaDirectFetcher- robot Yandex.Direct;
- Googlebot-Video- Pro video;
- Googlebot-Mobile- pro mobilní verzi;
- YandexDirectDyn- Robotické generování dynamických bannerů;
- YandexBlogs- Robot vyhledává blogy, které indexují příspěvky a komentáře;
- YandexMarket- robot Yandex.Market;
- YandexNews- Robot Yandex.Novin;
- YandexDirect— shromažďuje informace o obsahu partnerských stránek Reklamních médií za účelem objasnění jejich témat pro výběr relevantní reklamy;
- YandexPagechecker- validátor mikroznaček;
- YandexCalendar- Robot Yandex.Calendar.
Disallow – nastavit na cíl
Jsme na to opatrní, protože stránky jsou v procesu finalizace a vy nechcete, aby byly jakkoli odhaleny.
Je důležité znát toto pravidlo, pokud je místo připraveno před tím, než je ošetřeno koristuvachy. Bohužel na to spousta webmasterů zapomíná.
zadek. Jak napsat pravidlo Disallow, aby se roboti místo složky nedívali na datum doporučení /papka/:


Tento řádek blokuje indexování všech souborů s příponami.gif
Povolit - řídit roboty
Povolit vám umožňuje skenovat jakýkoli soubor/směrnici/stranu. Je možné, ale nutné, aby roboti viděli pouze stránky, které začínaly bez /katalogu, a zavřít obsah. Pro který typ je předepsána následující kombinace:

Pravidla Allow a Disallow jsou řazena podle předpony URL (od nejmenší po největší) a uspořádána sekvenčně. Pokud je stránka vhodná pro tucet pravidel, robot vybere zbývající pravidlo ze seřazeného seznamu.
Hostitel - vyberte zrcadlový web
Host je jedním z povinných pravidel pro robots.txt, informuje robota Yandex, že zrcadlový web by měl být použit pro indexování.
Zrcadlo webu – přesná nebo přesná kopie webu, dostupná na různých adresách.
Robot se nebude toulat, pokud jsou na webu nějaká zrcadla a je jasné, že zrcadlo je specifikováno v souboru robots.txt. Adresy stránek musí být zadány bez předpony http://; v opačném případě, pokud web funguje na protokolu HTTPS, musí být uveden předpona https://.
Jak zapsat toto pravidlo:

Příklad souboru robots.txt, protože web funguje na protokolu HTTPS:

Sitemap - lékařská mapa stránek
Sitemap informuje roboty, že všechny adresy URL na webu, které vyžadují indexování, jsou umístěny na http://site.ua/sitemap.xml. Během procházení kůže bude robot vědět, jaké změny byly v tomto souboru provedeny, a rychle aktualizuje informace o webu v databázích vyhledávacího systému.

Crawl-delay - stopky pro slabé servery
Crawl-delay je parametr, který umožňuje určit období, během kterého budou stránky webu procházeny. Toto pravidlo je relevantnější, pokud máte slabý server. V tomto případě mohou nastat velké problémy s nasazením vyhledávacích robotů na straně webu. Tento parametr se mění v sekundách.

Clean-param – péče o obsah, který je duplicitní.
Clean-param pomáhá vypořádat se s parametry get, aby se zabránilo duplicitě obsahu, který může být dostupný na různých dynamických adresách (ze zdrojů). Takové adresy se objevují, protože web má jiné řazení, ID relace atd.
Je možné, že strana je dostupná na následujících adresách:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
V tomto případě vypadá soubor robots.txt takto:

Tady ref označuje, že oznámení bylo odesláno, je napsáno na samotné stránce a poté je uvedena adresa.
Než přejdete k referenčnímu souboru, musíte si být vědomi určitých znaků, které budou platit při psaní souboru robots.txt.
Symboly v souboru robots.txt
Hlavní znaky souboru jsou "/, *, $, #".
Pro další pomoc rozřezat "/" Ukazujeme, co chceme roboty pokrýt. Pokud má například pravidlo Disallow jedno lomítko, zabrání procházení celého webu. Pomocí dvou lomítek můžete zablokovat kontrolu libovolného jiného adresáře, například: /catalog/.
Takový záznam by znamenal, že bychom celou věc naskenovali do adresáře katalogu, a pokud napíšeme /catalog, zablokujeme všechny příspěvky na webu, které začínají /catalog.
Ziročka "*" znamená jakoukoli sekvenci znaků, kterou soubor obsahuje. Mělo by být umístěno po pravidle kůže.
Tento záznam naznačuje, že všichni roboti nenesou vinu za indexování souborů s příponou .gif ve složce /catalog/
znak dolaru «$» obklopený hvězdným znamením. Pokud potřebujete chránit celou složku katalogu, jinak nemůžete chránit adresy URL jako /catalog, bude záznam v souboru indexu vypadat takto:
Zadejte "#" Vikoristovi za komentáře, že se webmaster sám připravuje o ostatní webmastery. Robot není zodpovědný za skenování webu.
Například:
Jak vypadá ideální soubor robots.txt

Soubor je nahrán na web k indexování, hostitel je registrován a je poskytnuta mapa webu, která vyhledávačům umožňuje získat adresy, které mohou být indexovány. Pravidla pro Yandex jsou jasně stanovena, protože ne všichni roboti rozumí pokynům hostitele.
S kopírováním souboru na sebe nespěchejte – každý web může mít jedinečná pravidla v závislosti na typu webu a CMS. Při vyplňování souboru robots.txt byste proto měli pamatovat na všechna pravidla.
Jak ověřit soubor robots.txt
Pokud se chcete ujistit, že jste soubor robots.txt vyplnili správně, zkontrolujte jej v Nástrojích pro webmastery Google a Yandex. Stačí zadat výstupní kód do souboru robots.txt v přihlašovacím formuláři a označit web, který je ověřován.
Jak uložit soubor robots.txt
Často jsou při vyplňování indexového souboru povoleny sekrety, a to kvůli extrémní neúctě nebo spěchu. Několikrát nižší než tabulka prominutí, kterou jsem se naučil v praxi.


2. Nahrávání více složek/adresářů v jedné instrukci Disallow:

Taková nahrávka může zmást zvukové roboty, nemusí si uvědomit, že oni sami by neměli být indexováni: ať už složku spustím, nebo ji nechám, musím pečlivě napsat pravidlo vzhledu.

3. Může být vyvolán samotný soubor pouze robots.txt, a ne Robots.txt, ROBOTS.TXT nebo nějakým jiným způsobem.
4. Pravidlo User-agent nelze zneplatnit - je nutné říci, který robot je zodpovědný za změnu pravidel zapsaných v souboru.
5. Zajištění značek ze souboru (lomítka, hvězdičky).
6. Přidání stránek do souboru, které nemusí být v indexu.
Nestandardní soubor robots.txt
Kromě svých přímých funkcí se indexový soubor může stát zdrojem kreativity a způsobem, jak najít nové dobrovolníky.
Jedná se o web, kde samotný robots.txt je malý web s pracovními prvky a reklamním blokem.




Jako maydanchik pro vyhledávání padělků je soubor vikoristed hlavně SEO agenturami. Kdo další se může o vašem snu dozvědět? :)

A Google ukládá speciální soubor humans.txt Abyste nepřipustili úvahy o diskriminaci fahivtů pro jejich kůži a maso.

Višnovki
S pomocí Robots.txt můžete dávat pokyny k vyhledávání robotů, propagovat sebe, svou značku a specialisty na žerty. Toto je skvělé pole pro experimentování. Golovny, pamatujte na správné plnění pilníku a standardní čištění.
Pravidla, páchnou příkazy, páchnou pokyny k souboru robots.txt:
- User-agent je pravidlo o těch robotech, kteří se musí řídit pokyny popsanými v robots.txt.
- Disallow představuje doporučení, že samotné informace nelze skenovat.
- Sitemap informuje roboty, že všechny adresy URL stránek, které vyžadují indexování, se nacházejí na adrese http://site.ua/sitemap.xml.
- Hostitel informuje robota Yandex, že je třeba najmout zrcadlový web pro indexování.
- Povolit vám umožňuje skenovat jakýkoli soubor/směrnici/stranu.
Příznaky při skládání robots.txt:
- Znak dolaru "$" je obklopen znakem hvězdy.
- Za lomítkem "/" ukazujeme, co chceme skrýt před odhalením roboty.
- Hvězdička "*" znamená libovolnou sekvenci znaků, kterou soubor obsahuje. Mělo by být umístěno po pravidle kůže.
- Hash „#“ se používá k označení komentářů, které webmaster píše pro sebe nebo pro jiné webmastery.
Vycoristujte indexový soubor moudře – a web bude v budoucnu viditelný.
Hodina čtení: 7 hwilin(ů)
Téměř každý projekt, který k nám přichází na audit nebo kontrolu, obsahuje nesprávný soubor robots.txt a často i celý den. Zdá se tedy, že při vytváření souboru se každý řídí svou fantazií, a ne pravidly. Pojďme přijít na to, jak tento soubor správně poskládat, aby s ním vyhledávací roboti mohli efektivně pracovat.
Potřebujete ještě upravit soubor robots.txt?
Robots.txt- tento soubor se nachází na kořenovém webu katalózy, o kterém robot vyhledávače informuje, ke kterým sekcím a stránkám webu jim může být odepřen přístup, ale ke kterým není přístup.
Úprava robots.txt je důležitou součástí pro systémy vyhledávačů, správné nastavení robotů také zvyšuje produktivitu webu. Přítomnost souboru Robots.txt neumožňuje vyhledávačům procházet a indexovat web, ale pokud tento soubor nemáte, můžete narazit na dva problémy:
Vyhledávací robot čte celý web, takže „zamete“ rozpočet na procházení. Rozpočet procházení je tolik stránek, kolik dokáže vyhledávací robot procházet za pouhou hodinu.
Bez souboru robots vyhledávač odepře přístup k černobílým stránkám, až stovkám stránek, které se používají pro správu CMS. Indexuje je, a pokud přejdete na správné stránky vpravo, na kterých prezentacích pro vydavatele nejdůležitějšího obsahu, rozpočet na procházení skončí.
Index může používat přihlašovací stránku webu a další zdroje správce, takže k nim může útočník snadno přistupovat a provést na webu útok DDoS nebo malware.
Jak vyhledat roboty ke stažení webu pomocí souboru robots.txt a bez něj:

Syntaxe souboru robots.txt
Nejprve začněte rozumět syntaxi a upravte soubor robots.txt podle toho, jak vypadá „ideální soubor“:

Ale ne varto razu z yogo zastosovuvati. Pro každý web je nejčastěji potřeba mít vlastní úpravy, protože každý máme jinou strukturu webu, jiný CMS. Vezměme kožní direktivu po pořádku.
User-agent
User-agent – znamená vyhledávacího robota, který se musí řídit pokyny popsanými v souboru. Pokud se potřebujete vrátit ke všem najednou, zobrazí se ikona *. Můžete také eskalovat na zpívajícího zvukového robota. Například Yandex a Google:

Pro další účely robot chápe, že indexování všech souborů a složek je blokováno. Pokud chcete, aby byl celý váš web otevřen pro indexování, ponechte hodnotu Disallow prázdnou. Chcete-li přijmout veškerý obsah na webu po Disallow, vložte „/“.
Můžeme zablokovat přístup ke složce skladby, souboru nebo přípony souboru. Naše aplikace zavírá všechny vyhledávače, blokuje přístup ke složkám bitrix, search a pdf.

Dovolit
Povolit Primus se otevře pro indexování stránek a sekcí webu. V aplikaci se přepneme na vyhledávací roboty Google, blokování přístupu do složky bitrix, vyhledávání a rozšíření pdf. Ve složce Bitrix otevřeme 3 složky pro indexování: komponenty, js, tools.

Host - zrcadlový web
Zrcadlový web je duplikátem hlavního webu. Zrcadla se používají pro různé účely: změna adresy, zabezpečení, snížení provozu na serveru atd.
Hostitel je jedním z nejdůležitějších pravidel. Pokud je toto pravidlo napsáno, pak robot pochopí, že bude přijat k indexování ze zrcadel webu. Tato směrnice je nezbytná pro roboty Yandex a Mail.ru. Ostatní roboti jsou obecně ignorováni. Host musí být registrován pouze jednou!
U protokolů „https://“ a „http://“ bude syntaxe souboru robots.txt odlišná.
Sitemap - mapa stránek
Mapa webu je forma navigace na webu, která se používá k informování vyhledávačů o nových stránkách. V návaznosti na dodatečnou směrnici sitemap „násilně“ ukážeme robotovi, že mapa byla odstraněna.

Symboly v souboru robots.txt
Znaky, které se objevují v souboru, jsou: „/, *, $, #“.

Kontrola efektivity procesu po úpravě robots.txt
Poté, co jste umístili soubor Robots.txt na svůj web, musíte jej přidat a ověřit u správce webu Yandex a Google.
Ověření Yandex:
- Následuj instrukce.
- Vyberte: Upravené indexování – Analýza souboru robots.txt.
Kontrola Google:
- Následuj instrukce.
- Vyberte: Skenovat – nástroj pro kontrolu souboru robots.txt.
Tímto způsobem můžete zkontrolovat změny v souboru robots.txt a podle potřeby provést potřebné úpravy.
- Místo souboru je třeba psát velkými písmeny.
- Direktiva Disallow vyžaduje zadání alespoň jednoho souboru nebo adresáře.
- Řádek „User-agent“ nemusí být prázdný.
- User-agent může vždy přejít před Disallow.
- Pokud potřebujete chránit adresář před indexováním, nezapomeňte zahrnout lomítko.
- Před nahráním souboru na server musíte zkontrolovat, zda neobsahuje syntaktické a pravopisné chyby.
Hodně štěstí!
Videorecenze 3 metod pro vytvoření a úpravu souboru Robots.txt
Vydali jsme novou knihu „Obsahový marketing v sociálních médiích: Jak se dostat do hlav předplatitelů a splést je se svou značkou“.

Direktiva Host je příkaz nebo pravidlo, které informuje vyhledávač o těch (s www nebo bez www), které jsou důležité. Zdá se, že direktiva Host souboru je přiřazena výhradně Yandexu.
Často je potřeba zajistit, aby vyhledávač neindexoval stránky vašeho zrcadlového webu. Zdroj je například umístěn na jednom serveru, ale na internetu je identický s názvem domény, která je zodpovědná za indexování a zobrazování výsledků vyhledávání.
Vyhledávací roboti Yandex obcházejí strany webových stránek a přidávají shromážděné informace do databáze za aktuálním plánem. Během procesu indexování se samy objevují problémy, kterou stranu je třeba zpracovat. Roboti by se například měli vyhýbat různým fórům, vyhledávačům, katalogům a dalším zdrojům, které by indexovaly bez zmatku. Stejný smrad lze nalézt na hlavním webu a zrcadle. První z nich podporují indexování, ostatní nikoli. Proces často trpí problémy. V centru můžete použít direktivu Host v souboru Robots.txt.
Zde je požadovaný soubor Robots.txt
Robots je typický textový soubor. Můžete jej vytvořit pomocí programu Poznámkový blok, můžete s ním pracovat (otvírat a upravovat informace) pomocí textového editoru Notepad++. Potřeba souboru při optimalizaci webových zdrojů je určena několika faktory:
- Pokud je soubor Robots.txt zveřejněn, web bude neustále znovu navštěvován prostřednictvím robotů zvukových strojů.
- Je jasné, že všechny stránky a zrcadlené weby budou indexovány.
Indexace bude mnohem rychlejší a pokud jsou nastavení nainstalována nesprávně, můžete se ztratit ve výsledcích vyhledávání z Google a Yandex.
Jak formátovat direktivu Host v souboru Robots.txt
Soubor Robots obsahuje direktivu Host – pokyny pro vyhledávač jak o hlavním webu, tak o zrcadle.
Směrnice je napsána v následujícím tvaru: Host: [nejazykové vynechání] [význam] [nejazykové vynechání]. Pravidla pro psaní direktiv vyžadují následující kroky:
- Direktiva Host protokolu HTTPS podporuje šifrování. Toto musí být opraveno, protože přístup k zrcadlu je omezen ukradeným kanálem.
- Název domény, který není IP adresou, a také číslo portu webového zdroje.
Direktiva umožňující webmasterovi značit pro zvukové stroje de smut dzerkalo je správně sestavena. Ostatní budou ostatními respektováni, a proto nebudou indexováni. Zrcadla lze zpravidla odlišit přítomností nebo nepřítomností zkratky www. Vzhledem k tomu, že korespondent ani nezrcadlil webový zdroj za pomocí Host, vyhledávací systém Yandex byl nejlepším zdrojem informací od Webmastera. Stejné upozornění bude odesláno, pokud má soubor Robots supercitlivou direktivu Host.
Význam, de golovne dzerkalo stránky je možné prostřednictvím vyhledávacího systému. Musíte zadat adresu zdroje do řádku vyhledávání a podívat se na výsledky: web s www před doménou v řádku adresy a doménou head.
Pokud zdroj není zobrazen na straně pohledu, uživatelé jej mohou nezávisle rozpoznat jako hlavní zrcadlo přechodem do sekundární sekce v Yandex.Webmaster. Vzhledem k tomu, že webmaster musí zajistit, aby název domény webu nezaměnil www, nesmí být určen hostitelem.
Mnoho webmasterů používá domény v azbuce jako další zrcadla pro své stránky. Direktiva Host však nepodporuje cyrilici. Za tímto účelem je nutné duplikovat slova v latině, aby je bylo možné snadno rozpoznat zkopírováním adresy webu z řádku adresy.
Hostitel v souboru Robots
Hlavní účel této směrnice spočívá ve většině problémů z duplicitních stran. Hostitel je nutné zařadit, protože webový zdroj je zaměřen na ruské publikum a třídění stránek lze zjevně provádět systémem Yandex.
Ne všechny zvukové systémy podporují direktivu Host. Funkce je k dispozici pouze v Yandex. Neexistuje však žádná záruka, že doména bude přiřazena jako zrcadlový obraz, ale, jak sám Yandex říká, priorita bude vždy ztracena pro jména uvedená v hostiteli.
Aby vyhledávače správně četly informace při zpracování souboru robots.txt, je nutné přidat direktivu Host do příslušné skupiny, která začíná za User-Agent. Roboti však mohou hostitele vikorizovat bez ohledu na to, že směrnice je sepsána podle pravidel dané země, pokud je průřezová.
Vydali jsme novou knihu „Obsahový marketing v sociálních médiích: Jak se dostat do hlav předplatitelů a splést je se svou značkou“.

Robots.txt je textový soubor, který obsahuje pohledy pro vyhledávací roboty, což pomáhá indexovat stránky portálu.
Více videí na našem kanálu - naučte se internetový marketing od SEMANTICA
![]()
Prozraďte, že jste jeli na ostrov pro své věci. Nakreslíš mapu. Trasa je tam vyznačena: „Jděte k velkému pařezu. Začněte tím, že na výstupu vyděláte 10 kroků, poté přejděte na úroveň. Otoč se doprava, najdeš pechera."
Tse - vkazivki. Jejich následováním sledujete trasu a nacházíte poklady. Přibližně vyhledávací robot funguje, když začne indexovat web nebo stranu. Měli byste znát soubor robots.txt. Každý ví, které stránky je třeba indexovat a které ne. A podle těchto příkazů vynecháte portál a přidáte jeho stránky do indexu.
Proč potřebujete soubor robots.txt?
Začnou navštěvovat weby a indexové stránky poté, co web požádá o hostování a registrované DNS. Je důležité přestat pracovat na své práci, i když nemáte žádné technické soubory. Roboti vtipálkům nařídí, že při procházení webu musí uložit parametry, které na něm mají.
Přítomnost souboru robots.txt může způsobit problémy s rychlostí procházení webu a přítomností webu v indexu. Nesprávná konfigurace souboru může mít za následek zahrnutí důležitých částí zdroje z indexu a přítomnost nepotřebných stránek.
To vše v důsledku vede k problémům s únikem.
Pojďme se podívat na zprávu, abychom viděli, jaké vložky jsou umístěny v tomto souboru a jak ovlivňují chování robota na vašem webu.
Jak zrobiti robots.txt
Nejprve zkontrolujte, jaký soubor máte.
Zadejte adresu webové stránky do adresního řádku prohlížeče a název souboru pomocí lomítka, například https://www.xxxxx.ru/robots.txt
Pokud je soubor přítomen, na obrazovce se objeví seznam parametrů.

Soubor neobsahuje:
- Soubor je vytvořen pomocí základního textového editoru, jako je Notepad nebo Notepad++.
- Musíte nainstalovat název robota, extension.txt. Zadejte data v souladu s přijatými konstrukčními normami.
- Můžete zkontrolovat výhody pro další služby, jako je webmaster Yandex. Zde musíte vybrat položku „Analyze robots.txt“ v části „Nástroje“ a dokončit výzvy.
- Když je soubor připraven, nahrajte jej do kořenového adresáře webu.
Pravidla pro nastavení
Žolíky mají více než jednoho robota. Někteří roboti indexují pouze textový obsah, zatímco roboti indexují pouze grafický obsah. Stejný obvod robotických prolézaček v samotných zvukových systémech se může lišit. Při skládání šanonu je nutné jej zajistit.
Jejich provozovatelé mohou některá pravidla ignorovat, například GoogleBot nereaguje na informace o těch, kteří stránky zrcadlí v hlavě. Obecně platí, že smrad se zachytí a uloží do souboru.
Syntaxe souboru
Parametry dokumentu: jméno robota “User-agent”, direktivy: samostatná vlastnost “Allow” a zabezpečení “Disallow”.
Existují dva klíčové vyhledávací systémy: Yandex a Google. Při vytváření webových stránek je samozřejmě důležité využít oba.
Formát vytváření záznamů vypadá takto, aby se projevil respekt v polích a prázdných řádcích.

Direktiva user-agent
Robot hledá záznamy, které začínají User-agentem, a jsou zde záznamy pro jméno vyhledávacího robota. Ačkoli to není uvedeno, je důležité, aby přístup robota nebyl omezen.
Direktivy zakázat a povolit
Pokud potřebujete zablokovat indexování ze souboru robots.txt, použijte Disallow. To pomůže omezit přístup robota na stránku nebo různé sekce.
Protože robots.txt není v souladu se stejnou direktivou „Disallow“, která chrání, je důležité, aby bylo povoleno indexování celého webu. Zazvichiy zaboroni jsou předepsány po kožní robot okremo.
Všechny informace zadané po ikoně # nejsou považovány za komentáře stroje.
Povolit blokování pro povolení přístupu.
Symbol hvězdy slouží jako zkratka pro ty, kterých se každý obává: User-agent: *.
Tato možnost však znamená úplný zákaz indexování pro všechny.
Podívám se na plot místo na zpívající složku-katalog
Chcete-li zablokovat jeden soubor, musíte zadat tuto absolutní cestu
Sitemap, příkazy hostitele
Pro Yandex je obvyklé říkat, jako zrcadlo, chcete ho rozpoznat jako šmejd. A Google, jak si pamatujeme, ho ignoruje. Vzhledem k tomu, že neexistují žádná zrcadla, povšimněte si, jak důležité je správně napsat název vašeho webu s www nebo bez.
Směrnice Clean-param
Mohou být zmrazeny, pokud má adresa URL webových stránek nahradit parametry, které se mění, ale nesloučit se do nich (může to zahrnovat ID přispěvatelů, referrerů).
Například adresa stránek „ref“ označuje cíl provozu. Vezměte prosím na vědomí, že na webových stránkách jsou značky nejprodávanějších. Pro všechny klienty bude stránka stejná.
Práci lze odeslat online a informace se nebudou opakovat. Tím se sníží zatížení serveru.
Direktiva Crawl-delay
Kromě toho můžete určit, s jakou frekvencí robot přitahuje stránky k analýze. Tento příkaz se zastaví, pokud server revantage signalizuje, že proces bypassu je třeba urychlit.
Požadavky na soubor robots.txt
- Soubor není dostupný pro kořenový adresář. Největší robot nebude žertovat a nebude lhát.
- Písmena v názvu mohou být malá latinka.
V názvu je poznámka, někdy na konec přidáte písmeno S a napíšete robot. - V souboru robots.txt není možné měnit znaky azbuky. Pokud potřebujete zadat doménu v ruštině, použijte pro specifikaci formátu speciální formát Punycode.
- Jedná se o metodu převodu doménových jmen na sekvenci znaků ASCII. K tomu můžete rychle použít speciální převodníky.
Kód vypadá takto:
site.rf = xn--80aswg.xn--p1ai
Další informace, které by měly být skryty v robots txt a přizpůsobeny podle vyhledávačů Google a Yandex, naleznete v dodatečných dokumentech. Pro různé cm mohou mít své vlastní charakteristiky, ale budou se lišit.
bez komentářeSoubor robots.txt je vytvořen speciálně pro vyhledávací roboty, aby věděli, kam jít a indexovat a kde je vstup blokován. Pokud jej nastavíte špatně, možná nestrávíte mnoho času hledáním, nebo se vám může stát, že nebudete dělat nic.
Abyste se vyhnuli problémům s indexováním a indexováním článků, musíte vědět, jak vytvořit robots txt pro všechny vyhledávače. Zabere to jen malou hodinu, ale poté budete v klidu.
Weboví mistři se bez něj snažili obejít (zpočátku většinou z neznalosti). Na jednu stranu je to rozumné pro začátečníky – rozhodně si tak nezablokujete požadované informace před vyhledávacími roboty. Na druhou stranu tento malý soubor chrání data a zabraňuje spambotům v prohlížení informací na webu.
Doporučuji novým blogerům používat šablony. Například šablona robots txt pro WordPress. Vylepšete a vylepšujte své stránky.

Nešifrovaná hodnota:
- User-agent: * - Jste připojeni přímo ke všem vyhledávačům, Yandex - pouze k Yandex.
- Disallow: Seznam složek a souborů, které jsou blokovány pro indexování
- Host – zadejte název svého webu bez www.
- Sitemap: nahrajte do souboru Sitemap XML.
Umístěte soubor do kořenového adresáře webu pomocí Filezilla nebo prostřednictvím webu hostitele. Odešlete do hlavního adresáře, aby byl dostupný pro doručení: your_site.ru/robots.txt
To platí zejména pro ty, kteří používají CNC (pokyny jsou psány slovy, ale ne p=333). Vše, co musíte udělat, je přejít do Nastavení – Postname, vybrat spodní možnost a do pole zadat /%postname%.
Hercům se doporučuje, aby si tento soubor vytvořili sami co nejrychleji:
Chcete-li začít, vytvořte si na počítači poznámkový blok a pojmenujte jej roboti (neměňte velká písmena). Například při úpravě velikosti není nutné překročit 500 kb.
User-agent- Název vyhledávacího systému (Yandex, Googlebot, StackRambler). Pokud se chceš zlobit na všechny najednou, dej hvězdičku *

A pak označte stránky nebo složky, které nelze v této práci indexovat Zakázat:

Zpočátku byly reorganizovány tři adresáře, včetně konkrétního souboru.
Chcete-li umožnit indexování všeho, musíte napsat:
User-agent: *
Zakázat:
Nastavení souboru robots.txt pro Yandex a Google
Pro Yandex Je povinné přidat hostitelskou direktivu, aby nebyly žádné duplicitní stránky. Tomuto slovu rozumí pouze robot Yandex, proto prosím napište slova pro nový význam.

Pro Google Už nejsou žízniví. Za prvé, šlechta musí být brutalizována až do konce. V sekci User-agent musíte napsat:
- Googlebot;
- Googlebot-Image – jak obklopíte indexaci obrázku;
- Googlebot-Mobile – pro mobilní verzi webu.
Jak zkontrolovat platnost souboru robots.txt
Můžete pracovat v části „Nástroje pro webmastery“ vyhledávače Google nebo na webu Yandex.Webmaster v sekci Check robots.txt.
Pokud jsou nějaké chyby, opravte je a znovu je otočte. Pro dosažení dobrého výsledku pak nezapomeňte zkopírovat správný kód do robots.txt a nahrát jej na web.
Nyní můžete vidět, jak vytvořit soubor robots.txt pro všechny vyhledávače. Doporučuji nováčkům vikorist hotový soubor s uvedením názvu vašeho webu.
Poruchy