Blog o koži daje svoj dokaz za ovu želju. Zato se pridošlice u pokey industriji često izgube, pa to ide ovako:
Kakav robotski bivši?
Datoteka roboti.txt ili drugo Indeksna datoteka— primarni tekstualni dokument kodiran u UTF-8 prikladan je za http, https i FTP protokole. Datoteka se daje robotima za pretraživanje u svrhu: koje se stranice/datoteke skeniraju. Ako datoteka sadrži znakove koji nisu u UTF-8, već u drugom kodiranju, roboti za pretraživanje mogu ih pogrešno obraditi. Pravila navedena u datoteci robots.txt važeća su ovisno o hostu, protokolu i broju porta na kojem se datoteka nalazi.
Datoteka mora biti instalirana u korijenskom direktoriju u obliku primarnog tekstualnog dokumenta i dostupna je na adresi: https://site.com.ua/robots.txt.
U drugim datotekama uobičajeno je staviti ikonu BOM (Byte Order Mark). Ovo je Unicode znak koji se koristi za označavanje niza u bajtovima prilikom čitanja informacija. Simbol koda je U+FEFF. Oznaka niza bajtova u datoteci robots.txt zanemaruje se.
Google je postavio ograničenja na veličinu datoteke robots.txt – niste obvezni unijeti više od 500 KB.
Garazd, budući da su ti potrebni neki tehnički detalji, datoteka robots.txt opisana je u obrascu Beckus-Naur (BNF). U ovom slučaju pregledavaju se pravila RFC 822.
Prilikom raščlambe pravila iz datoteke robots.txt, roboti za pretraživanje ispisat će jednu od tri upute:
- privatni pristup: skeniranje ostalih elemenata stranice nije dostupno;
- univerzalni pristup: sve se može skenirati;
- puna ograda: robot ne može ništa skenirati.
Prilikom skeniranja datoteke robots.txt, roboti će otkriti sljedeće vrste odgovora:
- 2xx - skeniranje je bilo uspješno;
- 3xx Zvučni robot prati preusmjeravanje podataka, ali ne odbija druge ulaze. Najčešće postoji pet pokušaja da robot pokupi liniju 3xx, a zatim se registrira pogreška 404;
- 4xx - Robot za pretraživanje cijeni to što možete skenirati cijelu stranicu;
- 5xx - se procjenjuje kao pravovremeni kvarovi poslužitelja, skeniranje je potpuno blokirano. Robot će nastaviti listati kroz datoteku dok ne odbije drugi unos. Googleov robot za pretraživanje može utvrditi je li ispis različitih stranica na web-mjestu prilagođen ispravno ili netočno, tako da umjesto odgovora 404 stranica proizvodi verziju 5xx, u kojem će slučaju stranica biti Nazovi s kodom linije 404.
Još uvijek nije poznato kako se generira datoteka robots.txt, koja je nedostupna zbog problema poslužitelja s pristupom internetu.
Na kraju, potrebna datoteka robots.txt
Na primjer, ponekad roboti nisu dobri u isporuci:
- stranice s posebnim informacijama o klijentima na stranici;
- stranice s različitim oblicima dijeljenja informacija;
- ogledala za web stranice;
- stranice s rezultatima pretraživanja.
Važno: budući da se stranica nalazi u datoteci robots.txt, jasno je da će se pojaviti ako se na njoj pronađe poruka na web mjestu ili na vanjskom izvoru.
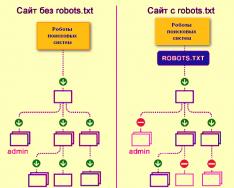
Ovako roboti tražilice indeksiraju web stranicu sa ili bez datoteke robots.txt:

Bez robots.txt, informacije koje su uhvaćene od trećih strana mogu se izgubiti iz vidokruga, a zbog toga ćete vi i stranica patiti.
Ovako robot sustava za pretraživanje preuzima datoteku robots.txt:

Google je identificirao datoteku robots.txt na web mjestu i zna pravila koja stoje iza indeksiranja stranica na web mjestu
Kako stvoriti datoteku robots.txt
Koristite notepad, Notepad, Sublime ili bilo koji drugi uređivač teksta.
User-agent - posjetnica za robote
User-agent - pravilo o onim robotima koji trebaju slijediti upute opisane u datoteci robots.txt. Trenutno su vidljiva 302 robota za pretraživanje
Razgovarajmo o onima za koje navodimo pravila robots.txt za sve robote za pretraživanje.
Za Google je glavni robot Googlebot. Ako želimo zaštititi bilo što drugo, unos datoteke će biti ovakav:
U tom će slučaju svi ostali roboti indeksirati sadržaj na temelju svojih direktiva za obradu prazne datoteke robots.txt.
Za Yandex, glavni robot je... Yandex:
Drugi posebni roboti:
- Mediapartners-Google- za uslugu AdSense;
- AdsBot-Google- Provjeriti okvir cijele strane;
- YandexImages- Yandex.Images indeksator;
- Googlebotova slika- Za slike;
- YandexMetrika- Yandex.Metrica robot;
- YandexMedia- Robot koji indeksira multimedijske podatke;
- YaDirectFetcher- Yandex.Direct robot;
- Googlebot-Video- Za video;
- Googlebot-Mobile- za mobilnu verziju;
- YandexDirectDyn- Robotsko generiranje dinamičkih bannera;
- YandexBlogovi- Robot traži blogove koji indeksiraju objave i komentare;
- YandexMarket- Yandex.Market robot;
- YandexNews- Robot Yandex.Novin;
- YandexDirect— prikuplja informacije o sadržaju partnerskih stranica Oglašavačkih medija kako bi se razjasnile njihove teme za odabir relevantnog oglašavanja;
- YandexPagechecker- validator mikro-označavanja;
- YandexCalendar- Yandex.Calendar robot.
Disallow - postaviti na cilj
Oprezni smo zbog toga jer je stranica u procesu finalizacije, a vi ne želite da bude izložena na bilo koji način.
Važno je znati ovo pravilo ako je stranica spremna prije nego što je pokvare korisnici. Nažalost, mnogi webmasteri zaboravljaju na ovo.
kundak. Kako napisati pravilo Disallow da roboti ne gledaju datum preporuke umjesto mape /papka/:


Ovaj redak blokira indeksiranje svih datoteka s ekstenzijama.gif
Dopusti - usmjeravanje robota
Allow vam omogućuje skeniranje bilo koje datoteke/naredbe/strane. Moguće je, ali nužno, da roboti mogu vidjeti samo stranice koje su započete bez /kataloga i zatvoriti sadržaj. Za koji tip je propisana sljedeća kombinacija:

Pravila za dopuštanje i zabranjivanje poredana su po prefiksu URL-a (od najmanjeg do najvećeg) i raspoređena redom. Ako je stranica prikladna za desetak pravila, robot odabire preostalo pravilo sa sortiranog popisa.
Domaćin - odaberite zrcalno mjesto
Host je jedno od obaveznih pravila za robots.txt, obavještava Yandex robota da se za indeksiranje treba koristiti zrcalna stranica.
Ogledalo stranice - točna ili točna kopija stranice, dostupna na različitim adresama.
Robot neće lutati ako na stranici ima ogledala i jasno je da je ogledalo navedeno u datoteci robots.txt. Adrese web-mjesta moraju se unijeti bez prefiksa http://; u suprotnom, ako web-mjesto radi na HTTPS-u, mora biti naveden prefiks https://.
Kako zapisati ovo pravilo:

Primjer datoteke robots.txt, budući da stranica radi na HTTPS protokolu:

Sitemap - karta medicinskih stranica
Sitemap obavještava robote da se nalaze svi URL-ovi na web-mjestu koji zahtijevaju indeksiranje http://site.ua/sitemap.xml. Tijekom pretraživanja kože, robot će biti svjestan promjena koje su napravljene u ovoj datoteci i brzo će ažurirati informacije o web mjestu u bazama podataka sustava pretraživanja.

Crawl-delay - štoperica za slabe poslužitelje
Odgoda indeksiranja je parametar koji vam omogućuje da odredite razdoblje tijekom kojeg će se stranice web mjesta indeksirati. Ovo pravilo je relevantnije ako imate slab poslužitelj. U tom slučaju može doći do velikih problema s postavljanjem robota za pretraživanje na strani web mjesta. Ovaj se parametar mijenja u sekundi.

Clean-param - briga za sadržaj koji se duplicira.
Clean-param pomaže u rješavanju get-parametara kako bi se spriječilo dupliciranje sadržaja koji može biti dostupan na različitim dinamičkim adresama (iz feedova). Takve se adrese pojavljuju jer web mjesto ima drugačije sortiranje, ID-ove sesija itd.
Moguće je da je strana dostupna na sljedećim adresama:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
U ovom slučaju datoteka robots.txt izgleda ovako:

Ovdje ref označava da je obavijest poslana, to je napisano na samoj stranici, a zatim je naznačena adresa.
Prije nego što odete na referentnu datoteku, morate biti svjesni određenih znakova koji će se primjenjivati prilikom pisanja datoteke robots.txt.
Simboli u robots.txt
Glavni znakovi za datoteku su "/, *, $, #".
Za daljnju pomoć kosa crta "/" Pokazujemo što želimo pokriti robotima. Na primjer, ako pravilo Disallow ima jednu kosu crtu, ono sprječava indeksiranje cijele stranice. Pomoću dvije kose crte možete blokirati skeniranje bilo kojeg drugog direktorija, na primjer: /katalog/.
Takav bi zapis značio da bismo cijelu stvar skenirali u imenik kataloga, a ako napišemo /katalog, blokirali bismo sve postove na stranici koji počinju s /katalog.
Ziročka "*" znači koji god niz znakova datoteka ima. Treba ga postaviti nakon pravila kože.
Ovaj unos sugerira da nisu svi roboti krivi za indeksiranje datoteka s ekstenzijom .gif u mapi /katalog/
znak dolara «$» okružen znakom zvijezde. Ako trebate zaštititi cijelu mapu kataloga, inače ne možete zaštititi URL-ove poput /catalog, unos u indeksnoj datoteci bit će ovakav:
Upišite "#" Vikorist za komentare da se webmaster uskraćuje drugim webmasterima. Robot nije odgovoran za skeniranje stranice.
Na primjer:
Kako izgleda idealan robots.txt

Datoteka se učitava na web mjesto radi indeksiranja, host se registrira i daje se karta web mjesta kako bi tražilice mogle dohvatiti adrese koje bi mogle biti indeksirane. Pravila za Yandex jasno su navedena, jer svi roboti ne razumiju upute hosta.
Samo nemojte žuriti kopirati datoteku na sebe - svaka stranica može imati jedinstvena pravila, ovisno o vrsti stranice i CMS-u. Stoga se trebate sjetiti svih pravila prilikom ispunjavanja datoteke robots.txt.
Kako provjeriti datoteku robots.txt
Ako želite biti sigurni da ste ispravno ispunili datoteku robots.txt, provjerite je u Alatima za webmastere Google i Yandex. Samo unesite izlazni kod u datoteku robots.txt u obrascu za slanje i navedite web mjesto koje se provjerava.
Kako spremiti datoteku robots.txt
Često se prilikom popunjavanja indeksne datoteke dopuštaju sekreti, i to zbog izrazitog nepoštivanja ili žurbe. Nekoliko puta niže od tablice pomilovanja koju sam naučio u praksi.


2. Snimanje više mapa/direktorija u jednu uputu Disallow:

Takva snimka može zbuniti zvučne robote, oni možda neće shvatiti da sami ne bi trebali biti indeksirani: bilo da otvorim mapu ili je napustim, moram pažljivo napisati pravilo kože.

3. Sama datoteka se može pozvati samo robots.txt, a ne Robots.txt, ROBOTS.TXT ili na neki drugi način.
4. Pravilo User-agent nije moguće poništiti - potrebno je reći koji je robot odgovoran za promjenu pravila zapisanih u datoteci.
5. Osiguranje oznaka s turpije (kose crte, zvjezdice).
6. Dodavanje u datoteku stranica koje ne moraju biti u indeksu.
Nestandardni roboti.txt
Uz svoje izravne funkcije, indeksna datoteka može postati izvor kreativnosti i način pronalaženja novih volontera.
Ovo je stranica gdje je sam robots.txt mala stranica s radnim elementima i oglasnim blokom.




Kao maydanchik za traženje krivotvorina, datoteku koriste uglavnom SEO agencije. Tko još može saznati za vaš san? :)

I Google pohranjuje posebnu datoteku ljudi.txt Tako da ne dopuštate misli o diskriminaciji fahivta zbog njihove kože i mesa.

Visnovki
Uz pomoć Robots.txt možete dati upute robotima za pretraživanje, reklamirati sebe, svoju marku i stručnjake za šale. Ovo je odlično polje za eksperimentiranje. Golovny, sjetite se pravilnog punjenja datoteke i standardnog čišćenja.
Pravila, smrde na direktive, smrde na upute za datoteku robots.txt:
- User-agent je pravilo o robotima koji trebaju slijediti upute opisane u robots.txt.
- Disallow predstavlja preporuku da se same informacije ne mogu skenirati.
- Sitemap obavještava robote da se svi URL-ovi web mjesta koji zahtijevaju indeksiranje nalaze na http://site.ua/sitemap.xml.
- Domaćin obavještava Yandex robota da je potrebno angažirati zrcalno mjesto za indeksiranje.
- Allow vam omogućuje skeniranje bilo koje datoteke/naredbe/strane.
Znakovi prilikom savijanja robots.txt:
- Znak dolara "$" okružen je znakom zvjezdice.
- Nakon kose crte "/" prikazujemo ono što želimo sakriti od otkrivanja robota.
- Zvjezdica "*" označava koji god niz znakova datoteka ima. Treba ga postaviti nakon pravila kože.
- Hash "#" koristi se za označavanje komentara koje webmaster piše za sebe ili druge webmastere.
Mudro koristite datoteku indeksa - i stranica će biti vidljiva u budućnosti.
Sat čitanja: 7 hwilin(s)
Gotovo svaki projekt koji nam dođe na reviziju ili inspekciju sadrži neispravnu datoteku robots.txt, a često i cijeli dan. Pa se čini da se pri izradi spisa svatko vodi svojom maštom, a ne pravilima. Smislimo kako pravilno presavijati ovu datoteku kako bi roboti za pretraživanje mogli učinkovito raditi s njom.
Postoji li potreba za poboljšanjem robots.txt?
Roboti.txt- ova se datoteka nalazi na web stranici root catalosis, koju javlja robot tražilice, kojim dijelovima i stranicama web stranice im se može zabraniti pristup, ali kojima nema pristupa.
Prilagodba robots.txt važan je dio za sustave tražilica; pravilna prilagodba robota također povećava produktivnost stranice. Prisutnost Robots.txt ne dopušta tražilicama indeksiranje i indeksiranje stranice, inače ako nemate ovu datoteku, možete naići na dva problema:
Robot za pretraživanje čita cijelu stranicu, tako da "briše" budžet za indeksiranje. Proračun indeksiranja iznosi onoliko stranica koliko robot za pretraživanje može pregledati u samo jednom satu.
Bez robotske datoteke, tražilica odbija pristup crno-bijelim stranicama, do stotinama stranica koje se koriste za CMS administraciju. Indeksira ih, a ako odete na prave stranice s desne strane, na kojima su prezentacije najvažnijeg sadržaja za izdavače, proračun za indeksiranje će završiti.
Indeks može koristiti stranicu za prijavu na web mjesto i druge administratorske resurse, tako da im napadač može lako pristupiti i izvršiti DDoS napad ili zlonamjerni softver na web mjestu.
Kako tražiti robote za preuzimanje stranice koristeći robots.txt i bez njega:

Robots.txt sintaksa
Prvo počnite razumjeti sintaksu i prilagodite robots.txt, ovisno o tome kako "idealna datoteka" izgleda:

Ale ne varto razu z yogo zastosovuvati. Za svaku stranicu najčešće je potrebno imati svoje prilagodbe, jer svi imamo drugačiju strukturu stranice, drugačiji CMS. Uzmimo direktivu o koži redom.
Korisnički agent
Korisnički agent - znači robot za pretraživanje koji mora slijediti upute opisane u datoteci. Ako se trebate vratiti na sve odjednom, pojavit će se ikona *. Također možete eskalirati do robota koji pjeva zvuk. Na primjer, Yandex i Google:

Za dodatnu svrhu direktive, robot razumije koje su datoteke i mape za indeksiranje blokirane. Ako želite da vaša cijela stranica bude otvorena za indeksiranje, ostavite vrijednost Disallow praznu. Da biste prihvatili sav sadržaj na stranici nakon Disallow, stavite “/”.
Možemo blokirati pristup mapi pjesme, datoteci ili ekstenziji datoteke. Naša aplikacija zatvara sve tražilice, blokira pristup mapama bitrix, search i pdf.

Dopusti
Allow Primus otvara se za indeksiranje stranica i odjeljaka web mjesta. U aplikaciji prelazimo na Google robote za pretraživanje, blokirajući pristup bitrix mapi, pretraživanju i pdf ekstenziji. U mapi Bitrix otvaramo 3 mape za indeksiranje: komponente, js, alati.

Domaćin - stranica ogledala
Zrcalna stranica je duplikat glavne stranice. Ogledala se koriste u razne svrhe: promjena adrese, sigurnost, smanjenje prometa na poslužitelju itd.
Domaćin je jedno od najvažnijih pravila. Ako je ovo pravilo napisano, tada će robot shvatiti da će ono biti prihvaćeno za indeksiranje iz ogledala stranice. Ova je direktiva neophodna za Yandex i Mail.ru robote. Drugi se roboti općenito ignoriraju. Host se mora registrirati samo jednom!
Za protokole "https://" i "http://", sintaksa datoteke robots.txt bit će drugačija.
Sitemap - mapa stranice
Karta web stranice oblik je navigacije web stranice koja se koristi za informiranje tražilica o novim stranicama. Slijedeći dodatnu direktivu karte web stranice, "prisilno" pokazujemo robotu da je karta uklonjena.

Simboli u robots.txt
Znakovi koji se pojavljuju u datoteci su: “/, *, $, #”.

Provjera učinkovitosti procesa nakon podešavanja robots.txt
Nakon što postavite Robots.txt na svoju web stranicu, trebate ga dodati i potvrditi kod webmastera Yandexa i Googlea.
Yandex potvrda:
- Slijedi upute.
- Odaberite: Prilagođeno indeksiranje – Analiza robots.txt.
Google provjeri:
- Slijedi upute.
- Odaberite: Skeniraj - alat za provjeru datoteke robots.txt.
Na taj način možete provjeriti ima li promjena u datoteci robots.txt i izvršiti potrebne prilagodbe prema potrebi.
- Umjesto datoteke potrebno je pisati velikim slovima.
- Direktiva Disallow zahtijeva navođenje najmanje jedne datoteke ili direktorija.
- Redak “User-agent” ne mora biti prazan.
- User-agent uvijek može ići ispred Disallow.
- Ne zaboravite uključiti kosu crtu ako trebate zaštititi imenik od indeksiranja.
- Prije postavljanja datoteke na poslužitelj, morate je provjeriti ima li sintaktičkih i pravopisnih pogrešaka.
Sretno ti!
Video pregled 3 metode za izradu i podešavanje datoteke Robots.txt
Objavili smo novu knjigu, “Content Marketing in Social Media: Kako ući u glave pretplatnika i zbuniti ih svojim brendom.”

Direktiva Host je naredba ili pravilo koje obavještava tražilicu o onima (sa ili bez www) koji su važni. Čini se da je Host direktiva datoteke dodijeljena isključivo Yandexu.
Često postoji potreba za osiguravanjem da tražilica ne indeksira stranice vašeg zrcalnog mjesta. Na primjer, resurs se nalazi na jednom poslužitelju, ali na Internetu je identičan nazivu domene, koji je odgovoran za indeksiranje i prikaz rezultata pretraživanja.
Yandex roboti za pretraživanje zaobilaze strane web stranica i dodaju prikupljene informacije u bazu podataka iza trenutnog rasporeda. Tijekom procesa indeksiranja problemi nastaju sami od sebe, koju stranu treba obraditi. Na primjer, roboti bi trebali izbjegavati razne forume, tražilice, kataloge i druge resurse, de indeksirati bez zabune. Isti smrad može se naći na glavnom mjestu i ogledalu. Prvi promoviraju indeksiranje, drugi ne. Proces često ima problema. U sredini možete koristiti direktivu Host u datoteci Robots.txt.
Ovdje je potrebna datoteka Robots.txt
Robots je tipična tekstualna datoteka. Možete ga izraditi pomoću Notepada; možete s njim raditi (otvoriti i uređivati informacije) pomoću uređivača teksta Notepad++. Potreba za datotekom pri optimizaciji web resursa određena je nekoliko čimbenika:
- Ako se datoteka Robots.txt objavi, web stranica će se stalno iznova posjećivati putem robota zvučnih strojeva.
- Jasno je da će sve stranice i zrcalna mjesta biti indeksirana.
Indeksiranje će biti puno brže, a ako su postavke neispravno instalirane, možete se izgubiti u rezultatima pretraživanja Googlea i Yandexa.
Kako formatirati direktivu Host u datoteci Robots.txt
Datoteka Robots uključuje direktivu Host - upute za tražilicu o glavnoj stranici i o zrcalu.
Direktiva je napisana u sljedećem obliku: Domaćin: [nejezični izostanak] [značenje] [nejezični izostanak]. Pravila za pisanje direktiva zahtijevaju sljedeće korake:
- Direktiva Host za HTTPS protokol podržava enkripciju. Ovo se mora ispraviti jer je pristup zrcalu ograničen ukradenim kanalom.
- Naziv domene, koji nije IP adresa, kao i broj porta web izvora.
Direktiva koja omogućuje web masteru da označi za zvučne strojeve de smut dzerkalo je ispravno sastavljena. Druge će drugi poštovati i stoga neće biti indeksirani. U pravilu se ogledala mogu razlikovati po prisutnosti ili odsutnosti kratice www. Budući da dopisnik nije čak ni zrcalio web-resurs iza pomoći Host-a, sustav pretraživanja Yandex bio je najbolji izvor informacija od Webmastera. Ista obavijest bit će poslana ako datoteka Robots ima superosjetljivu direktivu Host.
Značaj, stranicu de golovne dzerkalo moguće je pronaći putem sustava pretraživanja. Trebate unijeti adresu resursa u red za pretraživanje i pogledati rezultate: web mjesto s www ispred domene u retku adrese i glavna domena.
Ako resurs nije prikazan na strani pogleda, korisnici ga mogu samostalno prepoznati kao glavno ogledalo prelaskom na sekundarni odjeljak u Yandex.Webmasteru. Budući da webmaster mora osigurati da naziv domene web stranice ne zamijeni www, domaćin ga ne smije navesti.
Mnogi web majstori koriste ćirilične domene kao dodatna ogledala za svoje stranice. Međutim, Host direktiva ne podržava ćirilicu. U tu svrhu potrebno je umnožiti riječi na latinici, kako bi se mogle lako prepoznati kopiranjem adrese stranice iz reda adresa.
Host at file roboti
Glavna svrha ove direktive leži u većini problema s dvostrukih strana. Host je potrebno rangirati jer je web-resurs namijenjen ruskoj publici i, očito, sortiranje web-mjesta može obaviti sustav Yandex.
Ne podržavaju svi zvučni sustavi Host direktivu. Funkcija je dostupna samo u Yandex. Međutim, nema jamstva da će domena biti dodijeljena kao zrcalna slika, ali, kao što sam Yandex kaže, prioritet će uvijek biti izgubljen za imena navedena u hostu.
Kako bi tražilice pravilno čitale informacije prilikom obrade robots.txt datoteke, potrebno je dodati Host direktivu u odgovarajuću grupu koja počinje nakon User-Agent-a. Međutim, roboti mogu nadigrati Domaćina bez obzira na to što je direktiva napisana prema pravilima zemlje, sve dok je presječna.
Objavili smo novu knjigu, “Content Marketing in Social Media: Kako ući u glave pretplatnika i zbuniti ih svojim brendom.”

Robots.txt je tekstualna datoteka koja sadrži poglede za robote za pretraživanje, što pomaže pri indeksiranju stranica portala.
Više videa na našem kanalu - naučite internet marketing od SEMANTICE
![]()
Otkrijte da ste otišli na otok po svoje stvari. Nacrtate kartu. Tamo je označen put: „Idi do velikog panja. Počnite tako što ćete zaraditi 10 kruna na izlazu, a zatim prijeđite na razinu. Skreni desno, naći ćeš pečeru.”
Tse - vkazivki. Prateći ih, slijedite rutu i pronalazite blaga. Otprilike robot za pretraživanje radi kada počne indeksirati stranicu ili stranu. Trebali biste znati datoteku robots.txt. Svatko zna koje stranice treba indeksirati, a koje ne. I slijedeći ove naredbe, zaobilazite portal i dodajete njegove stranice u indeks.
Zašto trebate robots.txt?
Počinju posjećivati web-mjesta i indeksirati stranice nakon što web-mjesto zatraži hosting i registrirani DNS. Važno je prestati raditi na svom radu čak i ako nemate tehničke datoteke. Roboti upućuju šaljivdžije da prilikom indeksiranja web stranice moraju spremiti parametre koje imaju na njoj.
Prisutnost datoteke robots.txt može uzrokovati probleme s brzinom indeksiranja stranice i prisutnošću stranice u indeksu. Neispravna konfiguracija datoteke može rezultirati uključivanjem važnih dijelova resursa iz indeksa i prisutnošću nepotrebnih stranica.
Sve to, kao rezultat, dovodi do problema s curenjem.
Pogledajmo izvješće da vidimo koji se umetci nalaze u ovoj datoteci i kako utječu na ponašanje robota na vašoj web stranici.
Yak zrobiti robots.txt
Prvo provjerite koju datoteku imate.
Unesite adresu web stranice u adresnu traku preglednika i naziv datoteke kroz kosu crtu, na primjer https://www.xxxxx.ru/robots.txt
Ako je datoteka prisutna, na zaslonu će se pojaviti popis parametara.

Datoteka ne sadrži:
- Datoteka se stvara pomoću osnovnog uređivača teksta kao što je Notepad ili Notepad++.
- Morate instalirati ime robota, extension.txt. Unesite podatke u skladu s prihvaćenim standardima dizajna.
- Možete provjeriti pogodnosti za dodatne usluge kao što je Yandex webmaster. Tamo trebate odabrati stavku "Analiziraj robots.txt" u odjeljku "Alati" i ispunite upite.
- Kada je datoteka spremna, prenesite je u korijenski direktorij stranice.
Pravila za postavljanje
Jokeri imaju više od jednog robota. Neki roboti indeksiraju samo tekstualni sadržaj, dok roboti indeksiraju samo grafički sadržaj. Isti krug robotskih puzača u samim zvučnim sustavima može biti drugačiji. Prilikom savijanja turpije potrebno ju je osigurati.
Njihovi operateri mogu zanemariti neka od pravila, na primjer, GoogleBot ne odgovara na informacije o onima koji zrcale stranicu u glavi. Općenito, smrad se hvata i sprema turpijom.
Sintaksa datoteke
Parametri dokumenta: naziv robota “User-agent”, direktive: zasebno svojstvo “Allow” i sigurnost “Disallow”.
Postoje dva ključna sustava pretraživanja: Yandex i Google. Očito je važno iskoristiti prednosti oba prilikom izrade web stranice.
Format kreiranja zapisa izgleda ovako, da se iskaže poštovanje u poljima i praznim redovima.

Direktiva korisničkog agenta
Robot pretražuje zapise koji počinju s User-agent, a postoje i unosi za ime robota za pretraživanje. Iako to nije naznačeno, važno je da pristup robotu nije ograničen.
Direktive Disallow i Allow
Ako trebate blokirati indeksiranje iz robots.txt, koristite Disallow. To će pomoći ograničiti pristup robota web stranici ili raznim odjeljcima.
Međutim, robots.txt nije u skladu s istom direktivom "Disallow", koja štiti, važno je da je dopušteno indeksiranje cijele stranice. Zazvichiy zaboroni su propisani nakon okrema robota kože.
Sve informacije unesene nakon ikone # stroj ne smatra komentarima.
Allow to block to enable access.
Simbol zvjezdice služi kao skraćenica za one koji su svi zabrinuti: User-agent: *.
Ova opcija, međutim, znači potpunu zabranu indeksiranja za sve.
Gledat ću ogradu umjesto raspjevane mape-kataloga
Za blokiranje jedne datoteke morate unijeti ovu apsolutnu putanju
Sitemap, smjernice hosta
Za Yandex je uobičajeno reći, poput ogledala, želite ga prepoznati kao smetnju. A Google ga, kao što se sjećamo, ignorira. Budući da nema zrcala, samo imajte na umu koliko je važno pravilno napisati naziv vaše web stranice sa ili bez www.
Clean-param direktiva
Mogu se blokirati ako URL stranica web stranice zamjenjuje parametre koji se mijenjaju, bez uplitanja u njih (ovo može uključivati ID suradnika, referera).
Na primjer, adresa stranica “ref” označava odredište prometa, dakle. Imajte na umu da na web stranici postoje znakovi najprodavanijih proizvoda. Za sve klijente stranica će biti ista.
Rad se može predati online, a podaci se neće ponavljati. Ovo će smanjiti opterećenje poslužitelja.
Direktiva za odgodu indeksiranja
Osim toga, možete odrediti kojom učestalošću bot privlači stranice za analizu. Ova naredba će se zaustaviti ako poslužitelj revantage naznači da se proces zaobilaženja treba ubrzati.
Robots.txt zahtjevi
- Datoteka nije dostupna korijenskom direktoriju. Najveći robot se neće šaliti i neće lagati.
- Slova u imenu mogu biti mala latinična.
U nazivu postoji napomena, ponekad se doda slovo S na kraj i napiše robot. - Nije moguće mijenjati ćirilične znakove u datoteci robots.txt. Ako trebate unijeti domenu na ruskom jeziku, koristite poseban Punycode format za određivanje formata.
- Ovo je metoda pretvaranja imena domena u niz ASCII znakova. Za to možete brzo koristiti posebne pretvarače.
Kod izgleda ovako:
site.rf = xn--80aswg.xn--p1ai
Dodatne informacije koje bi trebale biti skrivene u txt robotima i prilagođene prema tražilicama Google i Yandex nalaze se u dodatnim dokumentima. Za različite cm-ove, oni mogu imati svoje karakteristike, ali će biti različiti.
bez komentaraDatoteka robots.txt stvorena je posebno za robote za pretraživanje, tako da oni znaju gdje trebaju ići i indeksirati, a gdje je unos blokiran. Ako ga neispravno postavite, možda nećete potrošiti puno vremena na traženje ili ćete možda završiti tako da ništa ne poduzmete.
Da biste izbjegli probleme s indeksiranjem i indeksiranjem članaka, morate znati kako izraditi robotski txt za sve tražilice. Potrebno je samo sat vremena, ali nakon toga ćete biti mirni.
Web majstori su se pokušali snaći i bez toga (najčešće, uglavnom, neznanjem). S jedne strane, to je razumno za početnike - na ovaj način sigurno nećete blokirati tražene informacije od robota za pretraživanje. S druge strane, ova mala datoteka štiti podatke i sprječava neželjene robote da pregledaju informacije na stranici.
Preporučujem novim blogerima da koriste predloške. Na primjer, predložak robots txt za WordPress. Poboljšajte i poboljšajte svoju stranicu.

Nešifrirana vrijednost:
- User-agent: * - Povezani ste izravno na sve tražilice, Yandex - samo na Yandex.
- Disallow: navodi mape i datoteke koje su blokirane za indeksiranje
- Domaćin – unesite naziv svoje stranice bez www.
- Sitemap: prenesite u XML sitemap.
Postavite datoteku u korijenski direktorij web-mjesta pomoću Filezille ili putem web-mjesta hostera. Pošaljite u glavni direktorij tako da bude dostupan za isporuku: your_site.ru/robots.txt
Ovo posebno vrijedi za one koji koriste CNC (upute su napisane riječima, ali ne p=333). Sve što trebate učiniti je otići na Settings – Postname, odabrati donju opciju i u polje upisati /%postname%.
Glumci se potiču da sami kreiraju ovu datoteku što je prije moguće:
Za početak kreirajte bilježnicu na svom računalu i nazovite je roboti (ne mijenjajte velika slova). Na primjer, podešavanje vaše veličine nije potrebno da bi premašilo 500 kb.
Korisnički agent- Naziv sustava za pretraživanje (Yandex, Googlebot, StackRambler). Ako želiš biti ljut na sve odjednom, stavi zvjezdicu *

Zatim označite stranice ili mape koje se ne mogu indeksirati u ovom radu za pomoć Zabraniti:

U početku su reorganizirana tri direktorija, uključujući i određenu datoteku.
Da biste omogućili da sve bude indeksirano, morate napisati:
Korisnički agent: *
Zabrani:
Postavljanje robots.txt za Yandex i Google
Za Yandex Obavezno je dodati direktivu hosta kako ne bi bilo dupliciranih stranica. Ovu riječ razumije samo Yandex bot, stoga upišite riječi za novo značenje.

Za GoogleŽednih više nema. Prvo, plemstvo treba brutalizirati do kraja. U odjeljku User-agent morate napisati:
- Googlebot;
- Googlebot-Image – kako okružujete indeksiranje slike;
- Googlebot-Mobile – za mobilnu verziju stranice.
Kako provjeriti valjanost datoteke robots.txt
Možete raditi u odjeljku "Alati za webmastere" Google tražilice ili na web stranici Yandex.Webmaster u odjeljku Provjerite robots.txt.
Ako ima grešaka, ispravite ih i ponovno okrenite. Da biste postigli dobar rezultat, nemojte zaboraviti kopirati ispravan kod u robots.txt i prenijeti ga na web mjesto.
Sada možete vidjeti kako stvoriti robots.txt za sve tražilice. Preporučujem da početnici koriste gotovu datoteku, podnoseći naziv svoje stranice.
Kvarovi