Linijinė paieška
Tiesiog nuosekliai apibrėžkite nurodytą metriką (pavyzdžiui, Levenshtein metriką) įvesties tekstui. Kai metrika keičiama su keitimais, šis metodas leidžia pasiekti optimalų roboto greitį. Ale su kuo daugiau k, tuo daugiau darbo valandų padidės. Valandos įvertinimas yra asimptotinis - O (kn).Bitap (taip pat žinomas kaip Shift-Or arba Baeza-Yates-Gonnet, Wu-Manber modifikacija)
Algoritmas Bitap O įvairios modifikacijos dažniausiai naudojamos neaiškiai paieškai be indeksavimo. Šis variantas naudojamas, pavyzdžiui, Unix įrankyje agrep , jo funkcija panaši į standartinį grep , bet pridėjus užuominą į paieškos terminą ir, tikiuosi, trukdo įprastų įrašų sustojimui.Idėją, kieno algoritmą pirmiausia išplatino milžinai Ricardo Baeza-Yatesasі Gastonas Gonnetas, 1992 m. paskelbė atskirą straipsnį.
Pradinė algoritmo versija susideda tik iš simbolių pakeitimų ir iš tikrųjų apskaičiuoja pakeitimą Hemming. Ale po tris rublius Sun Wuі Udi Manberis pristatė šio algoritmo modifikaciją poskyrio skaičiavimui Levenšteinas, tada. Jie pridėjo palaikymą įterpimams ir tuo pagrindu sukūrė pirmąją agrep programos versiją.

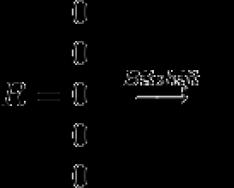
Gauta vertė
De k- malonių skaičius, j- Simbolio rodyklė, s x - simbolio kaukė (kauke pavieniai bitai pasukami tokiomis pozicijomis, kurios atitinka šio simbolio pozicijas įraše).
Įvesties pabėgimą arba atskyrimą rodo likęs gauto vektoriaus R bitas.
Didelę robotizuoto algoritmo spartą užtikrina bitų lygiagretumo skaičiavimas – per vieną operaciją vienu metu galima apskaičiuoti per 32 ir daugiau bitų.
Šiuo atveju trivialus įgyvendinimas palaikomas dviem ar trim garsu daugiau nei 32. Šis sujungimas nustatomas pagal standartinio tipo plotį tarpt(32 bitų architektūrose). Galite pasirinkti didelių matmenų tipus, bet taip pat galite patobulinti algoritmą.
Nepriklausomai nuo tų, kurie turi asimptotinę valandą algoritmui O (kn) Venkite naudoti šį linijinį metodą, jis bus daug greitesnis, kai bėgsite ilgai ir daug kartų k virš 2.
Testavimas
Testas buvo atliktas su 3,2 milijono žodžių tekstu, vidutinis žodis yra 10.Tiksli paieška
Paieškos valanda: 3562 msIeškokite Levenshtein metrikos Vikoristanyje
Valandėlę ieškosiu k = 2: 5728 msValandėlę ieškosiu k=5: 8385 ms
Ieškokite Bitap algoritmo su modifikacijomis iš Wu-Manber
Valandėlę ieškosiu k = 2: 5499 msValandėlę ieškosiu k=5: 5928 ms
Akivaizdu, kad paprasta metrikos paieška, kuriai taikomas Bitap algoritmas, gali sukelti daugybę klaidų. k.
Timas yra ne mažesnis, jei norite pakalbėti apie pokštą nekintamuose didžiojo apsėsto tekstuose, tai pokšto valandą galima gerokai sutrumpinti užpildžius pirmąją tokio teksto dalį, dar vadinamą Indeksavimas.
Neaiškios paieškos algoritmai su indeksavimu (neprisijungus)
Visų neaiškios paieškos algoritmų su indeksavimu ypatumas yra tas, kad indeksas bus už žodyno, saugomas už išvesties teksto arba įrašų sąrašo bet kurioje duomenų bazėje.Šie algoritmai naudoja skirtingus problemos sprendimo būdus – vieni naudoja duomenis, kad pasiektų tikslią paiešką, kiti – metriką, kad nustatytų skirtingas erdvines struktūras ir pan.
Visų pirma, šalia išvesties teksto bus žodynas žodžiams ir pozicijoms talpinti tekste. Taip pat galite pagerinti žodžių ir žodžių dažnį, kad sumažintumėte paieškos rezultatų intensyvumą.
Pranešama, kad rodyklė, kaip ir žodynas, yra visiškai skirta mįslei.
Žodyno taktinės ir techninės charakteristikos
- Išvesties tekstas – 8,2 gigabaito medžiagos iš Moshkov bibliotekos (lib.ru), 680 mln. žodžių;
- Žodyno dydis – 65 megabaitai;
- Žodžių kiekis – 3,2 mln.;
- Vidurinė žodžio dovžina yra 9,5 simbolio;
- Vidutinė kvadratinė žodžio dovžina (gali būti jaukus vertinant tam tikrus algoritmus) - 10,0 simbolių;
- Abėcėlė – puikios raidės A-Z, be E (siekiant supaprastinti tam tikras operacijas). Žodžiai, kurių simbolių nėra abėcėlėje, į žodyną neįtraukti.

Pasirinkimo išplėtimo algoritmas
Šis algoritmas dažnai užstringa rašybos tikrinimo sistemose (arba rašybos tikrintuvuose), kur žodyno dydis yra mažas, o darbo sklandumas nėra pagrindinis kriterijus.Tai pagrįsta ankstesne problema apie neaiškią paiešką ir problemą dėl tikslios paieškos.
Dienos pabaigoje nebus aiškių žodžių, kurių tiksli paieška bus atlikta žodyne.

Darbo valanda atsigulti iki k raidžių skaičiaus ir paspaudus abėcėlės dydį A, o kartą dvejetainė žodyno paieška tampa:
Pavyzdžiui, kada k = 1 O VII amžiaus žodžiai (pavyzdžiui, „Krokodilas“) rusų abėcėlėje be žodžių bus apie 450 dydžio, todėl prieš žodyną reikia sukurti 450 žodžių, o tai labai malonu.
Ale jau skirta k = 2 tokio daugialypumo dydis tampa daugiau nei 115 tūkstančių variantų, o tai rodo visišką mažo žodyno paiešką arba 1/27 mūsų pasirinkime, todėl darbo valanda taps puiki. Šiuo atveju nereikia pamiršti, kad kiekvienam iš šių žodžių reikia ieškoti tikslaus atitikimo žodyne.
funkcijos:
Algoritmą galima lengvai modifikuoti, kad būtų generuojami atsitiktiniai variantai, naudojant papildomas taisykles, be to, nereikia jokio papildomo žodyno apdorojimo, taigi ir papildomos atminties.Galimos spalvos:
Galima sugeneruoti ne visus beprasmius žodžius, o tik tuos, kurie labiausiai tiktų realioje situacijoje, pavyzdžiui, žodžius su dideliais rašybos pakeitimais ir rinkiniais.Šis išradimo būdas egzistuoja jau seniai ir yra plačiausiai naudojamas, nes jo įgyvendinimas itin paprastas ir užtikrina gerą našumą. Algoritmas pagrįstas tokiu principu:
„Jei žodžio A vengia žodis B dėl daugelio atleidimo atvejų, tada jie tikrai norės vienos velniškos eilės prieš N.
Šios N pogrupiai vadinami N gramais.
Indeksavimo valandą žodis padalijamas į tokius N gramus, o tada žodis sumažinamas iki kiekvieno iš šių N gramų sąrašų. Dienos pabaigoje paieškos užklausa taip pat padalijama į N gramus, o iš jų atliekama tolesnė paieška į žodžių sąrašą, pakeičiantį tokią seką.

Praktikoje dažniausiai vartojamos trigramos yra dovzhin eilės 3. Pasirinkus didesnę reikšmę, keičiamasi minimaliu dovžinos žodžiu, jei įmanoma atpažinti atleidimą.
funkcijos:
N-gramų algoritmas nuolat žino galimus žodžius su atleidimu. Paimkime, pavyzdžiui, žodį VOTKA ir suskirstykime į trigramas: IN T KA → VO T Apie T Prieš T KA - galite pastebėti, kad jie visi atkeršys T. Tokiu būdu žodis "MIESTAS" nebus rastas, kol negalėsite atkeršyti kiekvienam iš šių trigramų ir jų neprarasite iš jų sąrašų. Tokiu būdu, kuo mažiau žodžių ir kuo daugiau žodžių naujame, tuo didesnė tikimybė, kad sąrašuose neiššvaistysite iki svarbiausių N gramų ir rezultato nebus.Šiais laikais N-gramų metodas atima daugiau vietos pakankamai galingai ir sudėtingai galios metrikai pasirinkti, tačiau už tai reikia mokėti – naudojant šį variantą nereikia nuosekliai ieškoti maždaug 15 % žodyno. kad gautumėte klaidą tada labai svarbiems žodynams.
Galimos spalvos:
Galite padalyti N gramų maišos lentelę pagal žodžius ir N gramų vietas žodyje (1 modifikacija). Kaip ir ištarto žodžio pabaiga, jo nebegalima kartoti k, o N gramų padėtis žodyje gali būti padalinta tik iš k. Taip pat turėsite patikrinti lentelę, atitinkančią žodžio N gramų padėtį, ir tada eiti į piktojo ir dešiniarankio lentelę. viskas 2k+1 Teismo stalai.
Taip pat galite šiek tiek pakeisti peržiūrai reikalingos kartotės dydį padalydami lenteles iš paskutinio žodžio ir panašiai peržiūrėdami kitus pažodinius žodžius 2k+1 lentelė (2 modifikacija).
Šis algoritmas aprašytas L.M. Boytsovo straipsnyje. „Cheshuvannya su parašu“. Jis pagrįstas akivaizdžiu žodžio „struktūros“ pateikimu bitų eilių forma, kuri maišos lentelėje interpretuojama kaip maiša (parašas).
Indeksavimo metu tokios maišos skaičiuojamos kiekvienam žodžiui, o lentelėje įrašoma atitiktis tos maišos žodyno žodžių sąrašui. Tada dienos pabaigoje apskaičiuojama maiša ir visos maišos kartojamos, todėl gaunama ne daugiau kaip k bitų. Kiekvienai iš šių maišų ieškoma panašių žodžių sąrašo.
Maišos apskaičiavimo procesas – kiekvienam maišos bitui priskiriama abėcėlės simbolių grupė. 1 bitas ant padėties i maiša reiškia, kad išvesties žodis turi simbolį su i-oji abėcėlės grupės. Raidžių tvarka žodyje visiškai neturi reikšmės.

Pašalinus vieną simbolį arba nepakeitus maišos reikšmės (nes žodis prarado simbolius iš tos pačios abėcėlės grupės), arba atitinkama bitų grupė pasikeis į 0. Įterpiant, panašiai arba vienas bitas bus nustatytas į 1 , kitu atveju pokyčių nebus. Keičiant simbolius, visos dalys yra sudėtingesnės – maiša gali nepasikeisti arba pasikeisti 1 arba 2 pozicijomis. Keičiant kasdienius pokyčius, tai neįsimenama, todėl simbolių eiliškumas sufleruojant maišą, kaip buvo pažymėta anksčiau, neišsaugoma. Tokiu būdu, norint visiškai padengti k atleidimą, būtina juos kuo mažiau keisti 2kšiek tiek maišos.

Darbo valanda, viduryje, su k „nenuosekliu“ (įterpimai, išbraukti ir perkėlimai, taip pat nedidelė dalis pakeitimų) pataisymai: 
funkcijos:
Kadangi pakeičiant vieną simbolį, vienu metu galima keisti du bitus, algoritmas, įgyvendinantis, pavyzdžiui, ne daugiau kaip 2 bitų maišymą vienu metu, iš tikrųjų negali matyti rezultatų, kai yra reikšmė (saugoma In santykis su maišos dydžiu ir abėcėlė) žodžių dalys su dviem pakaitalais (ir kuo didesnis maišos dydis, tuo dažniau norint pakeisti simbolį reikia dviejų bitų derinio, ir tuo rezultatas bus ne toks pastovus) . Be to, šis algoritmas neleidžia ieškoti priešdėlių.BK-medžiai
medžiai Burkhardas-Kelleris- metrinių medžių, tokių medžių algoritmai yra pagrįsti metrikos galia parodyti trikūnio sluoksnio nestabilumą:Ši galia leidžia metrikai sukurti pakankamo dydžio metrines erdves. Tokios metrinės erdvės neapsunkina Euklido, pavyzdžiui, metrikos Levenšteinasі Damerau-Levenšteinas tvirtinti neeuklido erdvė. Remiantis šiais autoritetais, galima daryti išvadą apie duomenų struktūrą, kuri yra svarbi tokiai metrinei erdvei kaip Barkhard-Keller medis.

Patikslinimas:
Norėdami apskaičiuoti atstumą nuo ribų, galite naudoti tam tikras metrikas, nustatydami viršutinę ribą, kuri yra lygi didžiausiam atstumui iki viršaus ir gautą atstumą, kuris leidžia šiek tiek pagreitinti procesą:Testavimas
Testavimas buvo atliktas nešiojamuoju kompiuteriu su Intel Core Duo T2500 (2GHz/667MHz FSB/2MB), 2Gb RAM, OS – Ubuntu 10.10 Desktop i686, JRE – OpenJDK 6 Update 20.
Bandymas buvo atliktas Damerau-Levenshtein stotyje ir su daugybe kompromisų k = 2. Žodyno teiginių rodyklės dydis (65 MB).
Indekso dydis: 65 MB
Paieškos valanda: 320 ms / 330 ms
Rezultatų pakartojamumas: 100 %
N gramai (originalas)
Indekso dydis: 170 MBIndekso darbo laikas: 32 s
Paieškos valanda: 71 ms / 110 ms
Rezultatų pakartojamumas: 65 %
N gramas (1 modifikacija)
Indekso dydis: 170 MBIndekso darbo laikas: 32 s
Paieškos valanda: 39 ms / 46 ms
Rezultatų pakartojamumas: 63 %
N gramas (2 modifikacija)
Indekso dydis: 170 MBIndekso darbo laikas: 32 s
Paieškos valanda: 37 ms / 45 ms
Rezultatų pakartojamumas: 62 %
Indekso dydis: 85 MB
Indekso darbo laikas: 0,6 s
Paieškos valanda: 55 ms
Rezultatų pakartojamumas: 56,5 %
BK-medžiai
Indekso dydis: 150 MBRodyklės sukūrimo laikas: 120 s
Paieškos valanda: 540 ms
Rezultatų pakartojamumas: 63 %
Kartu
Dauguma neaiškių paieškos algoritmų su indeksavimu nėra iš tikrųjų sublinijiniai (todėl gali būti asimptotinė darbo valanda) O(log n) arba žemesnis), o jų sklandumas turi būti viduryje N. Laikas ne mažesnis, daugybė patobulinimų ir papildomų tyrimų leidžia pasiekti pakankamai trumpą darbo laiką net ir didžiosioms žodynų pareigoms.Taip pat trūksta įvairių ir neveiksmingų metodų ir pagrindo, be kita ko, įvairių, jau sustingusių, technikų ir požiūrių pritaikymui tam tikrai dalykinei sričiai. Tarp tokių metodų yra priešdėlių medžių (Trie) pritaikymas neaiškiai idėjai sukurti, kuri dėl mažo efektyvumo atimtų pagarbą. Taip pat yra algoritmų, pagrįstų originaliais metodais, pavyzdžiui, algoritmas Massa-Nowak, kuri gali būti subtiesinė asimptotinė darbo valanda, tačiau yra labai neveiksminga dėl didelių konstantų, kurios atsilieka nuo tokio valandinio įvertinimo, kurios atsiranda didelio indekso dydžio pavidalu.
Praktinis neaiškių paieškos algoritmų panaudojimas realiose paieškos sistemose yra glaudžiai susijęs su fonetiniais algoritmais, leksiniais kamieno algoritmais – matant skirtingų to paties žodžio žodžių formų bazinę dalį (pavyzdžiui, tokį funkcionalumą suteikia Snowball ir Yandex mystem ), kaip taip pat reitingus, pagrįstus statistine informacija arba įvairia sudėtinga, sudėtinga metrika.
- Levenšteino vaizdas (su kitokia ir priešdėlio versija);
- Vidstan Damerau-Levenshtein (su skirtinga ir priešdėlio versija);
- Bitap algoritmas (Shift-OR/Shift-AND su Wu-Manber modifikacijomis);
- Atrankos išplėtimo algoritmas;
- N-gramų metodas (originalus ir su pakeitimais);
- maišos su parašu metodas;
- BK medis.
Svarbu pažymėti, kad tyrinėdamas šį procesą išsiugdžiau galias, kurios leidžia greitai paspartinti pagrįsto indekso dydžio padidinimo paiešką ir bet kokį apsikeitimą laisve pasirinkti metriką. Bet tai visiškai kita istorija.
Semantinė šerdis
Norint sėkmingai plėtoti ir padidinti svetainės matomumą šiandieninėje realybėje, būtina palaipsniui plėsti semantinį branduolį. Vienas geriausių būdų plėstis – rinkti raktinius žodžius iš konkurentų.
Šiandien sunku atskirti konkurentų semantiką, nes... Yra daugybė paslaugų, tiek mokamų, tiek nemokamų.
Be kačių sąrašas:
- megaindex.ru - "Svetainės matomumo" įrankis
- xtool.ru - universali paslauga, kuri taip pat rodo raktinius žodžius, pagal kuriuos svetainė yra reitinguojama
Mokamų sąrašas:
- spywords.ru - tinka Yandex ir Google
- semrush.ru - orientacijos tik pagal Google
- prodvigator.ua - Ukrainos spywords.ru analogas
Be paslaugų, galite naudoti rankinį metodą, pagrįstą pavadinimo ir aprašymo paskirstymu n-gramais, todėl išvestis yra papildomas frazių sąrašas.
N-gramas – n elementų seka. Tiesą sakant, N gramas dažniau paaštrintas žemesniuose lygiuose. Dažnai vadinama dviejų sekančių elementų seka bigrama, vadinama trijų elementų seka trigrama. Ne mažiau kaip keturi ar daugiau elementų žymimi N-gramais, o tai reiškia, kad N pakeičiamas keletu vėlesnių elementų.
Pažvelkime į techniką žingsnis po žingsnio:
- Pagyvinkite konkurentų pavadinimus (apibūdinimus). Papildomos pagalbos galite gauti naudodami SEO programą „Screaming Frog“.
- Teksto rengyklėje yra švarus naujausių dalykų sąrašas, pvz., kalbos paslaugų dalys, skirstymo simboliai ir kiti dalykai. Aš naudoju funkciją „ieškoti ir pakeisti“ puikiame teksto rengyklėje (spartusis klavišas ctrl+H) su reguliariosiomis išraiškomis:
— Parenkame reikiamą n-gramą ir nustatome bent vieną dažnį. Geriausias variantas yra ir trigramai, ir 4 gramai:

- Galime atmesti greitą rezultatą:

Stovpetsskaičiuotirodo pakartojimų skaičiųn-gramas, viryklėsdažnis - Dažnisn- gramai.
Pasirinkę frazių sąrašą, turime jį išanalizuoti ir pasirinkti tinkamus raktinius žodžius, kad išplėstume semantinę šerdį. Ataskaitą galite rasti tam skirtame mūsų tinklaraščio skyriuje.
Užklausų grupavimas
Labai svarbu suprasti, kaip sugrupuojamas semantinis konkurentų branduolys, nes Tai padeda teisingai paskirstyti pagrindines frazes svetainės puslapiuose.
Šiuo tikslu, sudarę naują užklausų sąrašą, turime pasirinkti atitinkamus puslapius ir konkurentų pozicijas (galite naudoti seolib.ru) ir palyginti juos su mūsų grupėmis. Akivaizdu, kad konkurentas užima gerą poziciją ir tokiu atveju grupavimas skiriasi nuo mūsų (pavyzdžiui, konkurentas turi padalinius skirtingose pusėse, o mes taip pat turime sėdėti vienoje), reikia didinti rinkos dalį Peržiūrėkite nukreipimo puslapius savo svetainėje .
Pažvelkime į mažą to konkurento psichinės vietos grupavimo užpakalį.
Kaip matyti iš lentelės, svetainė site.ru turi vieną nukreipimo puslapį visiems raktiniams žodžiams. Konkurentas reitinguoja skirtingas svetaines pagal šias užklausas ir užima TOP arba pozicijas, artimas TOP. Iš to galite padaryti išvadą, kad reikia pažvelgti į site.ru grupavimą ir sukurti šoninį puslapį pagrindinėms frazėms su žodžiu „fasadas“.
Teksto blizgesys
Visų pirma, svarbu atkreipti dėmesį į konkurentų tekstų analizę, bet ne į didelę sandėlio apimtį (įvesties į tekstą skaičių irgi), o būti aišku ir prasminga – kiek vertingas yra informacija, kurią turiu perteikti konkurentui ir kaip dirbti.
Pažvelkime į krūvą užpakalių.
Gali būti, kad jūs užsiimate bilietų pristatymu į pagrindinį teksto puslapį ir garantuojate jų šviežumą. Pavyzdžiui, taip:
Pristatymo paslaugasvetainę. rugarantuoja puokščių taupymą šaltuoju metų laiku.
Ir vieno iš konkurentų užpakalinė ašis:
Pas mus pasidaryti kvapnias kompozicijas paprasta, nes garantuojame 100% centų grąžą, nes bilietų šviežumas nekelia abejonių.
Konkurento garantija papildyta menka suma, o tai yra prasmingesnė už abstrakčią garantiją.
Pažiūrėkime į kitą pavyzdį – tekstą internetinės parduotuvės kategorijos „keraminės plytelės“ puslapyje:

Šis tekstas neturi jokios korisnogo semantinės reikšmės, sutіlna vandens. Na, o už viską, žmogus, kuris ateina į svetainę ir priima sprendimą dėl pirkimo, nori sužinoti apie produkto privalumus ir galimas komplektacijas, tada yra be rūpesčių simbolių rinkimas.
Dabar pasigrožėkite konkurento tekstu:

Šis tekstas rusvas, nes... glaustai informuoja apie plytelių universalumą ir padeda suprasti, kaip išsirinkti tinkamą.
Tokiu būdu, lygindami konkurentų tekstus su savaisiais, galite išgauti daug naudingos informacijos, kuri padės tekstų kūrėjams dėliojant technines specifikacijas.
Tekstų aktualumas
Tęsiant tekstualumo temą, negalima nepažymėti jų aktualumo. Šiandien tam, kad tekstas būtų aktualus, neužtenka įvesti raktinių žodžių. Norėdami padidinti puslapio aktualumą ir nepadaryti teksto šlamšto, turite pasirinkti žodžius, susijusius su tema.
Vertindama paieškos teksto atitikimą tekstui, paieškos sistema analizuoja, ar yra raktinių žodžių ir papildomų žodžių, kurie naudojami tekstui pakeisti. Pavyzdžiui, jei rašome tekstą apie dramblį, tai su jungiamaisiais žodžiais galime vartoti „kamieną“, „iltis“, „gamtą“, „zoologijos sodą“. Jei tekstas yra apie čekį vyskupą, tai bus šie žodžiai: gabalas, čekis, karalienė ir kt.
Savo užklausoms tinkamiausią atitikmenų sąrašą galite rasti iš konkurentų tekstų. Kodėl reikia atlikti šiuos veiksmus:
— Visus tekstus iš TOP-10 po reikiamo HF įvesties nukopijuojame į įvairius tekstinius failus.
— Iš tekstų matosi tarnybinės kalbos dalys, skyrybos ženklai ir skaičiai (žiūrėta anksčiau).
— Žodžių išdėstymas iš eilės – naudojant funkciją „Ieškoti ir pakeisti“ įprastomis išraiškomis. Pakeiskite tarpą \n.
- Toliau reikia visas žodžių formas perkelti į įprastą žodžio formą (lemi). Tam galite greitai pasinaudoti paslauga https://tools.k50project.ru/lemma/. Lauke turite įvesti kiekvieno failo duomenų sąrašą, paspauskite mygtuką „Lemetizuoti ir rodyti CSV lentelėje“. Rezultatas gali būti 10 failų iš lemetizuotų žodžių.
— Žodžių dublikatai matomi odos faile.
- Žodžių iš failų sujungimas į vieną sąrašą.
– Dabar reikia susikurti dažnių žodyną. Šiuo tikslu sąrašas pridedamas prie paslaugos https://tools.k50project.ru/lemma/ ir spustelėjama „Gauti dažnių žodyną CSV rodinyje“.
- Mūsų paruoštų valgyti prekių sąrašas:

Jei dažnis yra 10, tai reiškia, kad žodis buvo vikorizuotas visose 10 svetainių, jei yra 8, tada tik 8 ir kt. Rekomenduojama rinktis didžiausio dažnio žodžius, tačiau tarp žodžių, kurie retai sutampa, galima rasti naudingų sprendimų.
Šiuo paprastu būdu galite pasirinkti teminių žodžių sąrašą, skirtą tekstų kūrėjams sudaryti technines specifikacijas.
Matyt, konkurentai yra labai svarbus informacijos šaltinis, galintis padėti geriau optimizuoti svetaines. Neaptariau visų šio straipsnio aspektų ir artimiausiu metu parašysiu apie gerus dalykus, kuriuos galite atimti iš savo konkurentų.
Prenumeruokite naujienlaiškį,
Pažvelgė N-gramai kaip šiuolaikinės realybės fiksacija kaip modelio konstruktas. Pasirinktos modelių nuorodos N-grama ir formalioji gramatika. Pagarba buvo sugrąžinta trumpam laikui ir trintis, siejama su tarptautinių modelių žiaurumu.
Įeikite
Užbaikime formalumus. Atlikime dainuojamosios abėcėlės užduotis VT={wi), de wi- Ypatingas simbolis. Be galo dovegin briaunų (eilučių), sudarytų iš abėcėlės simbolių VT, vadinamas mano abėcėlės būdu VT ir yra nurodyta L(VT). Okremiy lanciuzhok z filmas L(VT) Mes tai vadiname mano meile. Tavo širdyje, N-gramu Abetsi mieste VT vadinamas lanzyuzhok dovzhina N. N-Grama gali išvengti bet kokių įsipareigojimų, jei būsi iš eilės arba neįeisite iki L(VT).
Nutaikykim krūvą užpakalių N- gramas.
3. , N- rusiški gramai. // Nuorodų rinkinys.
4. Glanzas. Medicinos ir biologijos statistika Prov. iš anglų kalbos pagal leid. V. M., 1999 m.
5. Aprašomoji kalbotyra. Peredmova prie G. Gleasono knygos „Įvadas į aprašomąją kalbotyrą“. M., 1959 m.
6. Lingvistika yra teorinė ir taikomoji. M., 1968 m.
8. , Pauzė automatinės filmų sintezės metu. // Mokslinių tyrimų teorija ir praktika. M. 1999 m.
9. Minskis M. Pažinimo nežinomybės buvimas ir logika. // Naujiena užsienio kalbotyroje. VIP. XXIII. M., 1988 m.
10. Slobinas D., Greenas J. Psicholingvistika. M., 1976 m
11. Viralumo teorija. M., 1972 m.
12. Fu Do. Struktūriniai vaizdo atpažinimo metodai. M., 1977 m.
13. Harisas T. Epizodinių procesų teorija, todėl ji karšta. M., 1966 m.
14. Brilis E. ir į. Už jos ribų N-gramai: ar kalbinis rafinuotumas gali pagerinti kalbos modeliavimą?
15. Booth T. Formalių kalbų tikimybinis vaizdavimas. // IEEE metinis ženklas. Perjungimo ir automatų teorija. 1969 m.
16. Jelinek F. Savarankiškai organizuotas kalbos modeliavimas, skirtas kalbos atpažinimui. // Kalbos atpažinimo skaitymai. 1989 m.
17. Jelinija F., Lafferty J. Pradinės poeilutės generavimo tikimybės apskaičiavimas pagal stochastinę bekontekstinę gramatiką. //Kompiuterinė lingvistika, t.
18. Harisas Z. S. Struktūrinės lingvistikos metodas. Čikaga, 1951 m.
19. Lashley K. Problema dėl serijinės elgsenos tvarkos. // Psicholingvistika: skaitinių knyga, N. Y. 1961 m.
20. Šlesingeris E. Sakinio sandara ir skaitymo procesas. Mouton. 1968 metai.
21. Šiberis S. Natūralios kalbos išankstinio kontakto nebuvimo įrodymas. // Kalbotyra ir filosofija, t.
22. Sola baseinas I. Turinio analizės tendencijos šiandien. // Psicholingvistika: skaitinių knyga, N. Y. 1961 m
23. Stolcke A., Segal J. Virishenya n-gramų tikimybės iš stochastinių bekontekstinių gramatikų. // LKL 32-ojo metinio susirinkimo medžiaga. 1994 m.
Vikoristannya N-grama
Zagalne vikoristannya N-gram
- naudojant duomenis Žemės palydovinių vaizdų iš kosmoso serijai sugrupuoti, kad būtų galima nustatyti, kurios konkrečios Žemės dalys yra vaizde,
- ieškoti genetinių sekų,
- Genetikos srityje atliekami tyrimai, iš kurių konkrečių gyvūnų rūšių jie renka DNR mėginius.
- kompiuterio rankenoje
- Iš atitinkamų N gramų iškvieskite indeksuotus duomenis, susietus su garsu.
N gramai taip pat plačiai naudojami natūralios kalbos pavyzdžiuose.
Vikoristannya N-gram natūralios kalbos apdorojimo poreikiams
Natūralios kalbos apdorojimo srityje N-gramos daugiausia naudojamos vertimui pagal tarptautinius modelius. N-gramų modelis nustato likusio žodžio N-gram galimybę, nes mes viską žinome iš anksto. Naudojant šį metodą modeliavimui, kalba perkeliama taip, kad odos žodžio išvaizda būtų tiesiai virš priekinių linijų.
Priešingu atveju N gramų naudojimas yra plagiato požymis. Padalijus tekstą į keletą nedidelių fragmentų, pavaizduotų n-gramais, juos galima nesunkiai palyginti vienas su kitu ir tokiu būdu pašalinti valdomų dokumentų panašumo lygį. N-grama dažnai sėkmingai naudojama skirstant tekstą ir kalbą. Be to, jie gali būti naudojami kūrybinėms funkcijoms, kurios leidžia iš tekstinių duomenų išgauti žinias. Naudodami N-gramą galite efektyviai rasti kandidatus, kad pakeistumėte žodžius rašybos nuolaidomis.
Naujausi „Google“ tyrimų projektai
Ankstesni „Google“ tyrimų centrai kūrė N-gramų modelius įvairiems tyrimams ir plėtrai. Tai apima tokius projektus kaip statistinis vertimas iš vienos kalbos į kitą, kalbos atpažinimas, rašybos taisymas, informacijos gavimas ir daug daugiau. Šių projektų tikslais korpusų tekstai buvo naudojami trilijonams žodžių.
„Google“ nusprendė pastatyti savo būstinę. Projektas vadinamas Google teracorpus ir jame yra 1 024 908 267 229 žodžiai, surinkti iš nelegaliai prieinamų svetainių.
N-gramų gavimo būdai
Dėl dalinio N-gramų pakeitimo įvairioms užduotims reikalingas patikimas ir lankstus algoritmas joms išgauti iš teksto. Papildomas įrankis n-gramoms išgauti yra dėl galimybės dirbti su nesurišto dydžio tekstu, apdoroti duomenis ir efektyviai naudoti turimus išteklius. Yra keletas metodų, kaip išgauti N gramus iš teksto. Šie metodai yra pagrįsti skirtingais principais:
Pastabos
Div. taip pat
Wikimedia fondas. 2010 m.
- n-tv
- N-kadherinas
Įdomu, kas yra „N-gram“ kituose žodynuose:
Gramas- (prancūzų Gramme, graikiški Gramma ryžiai). Odinitsa prancūzų kalba. vago = vago 1 kubinis centimetras distiliuoto vandens = 22,5 rasos. dalys. Rusų kalbos sandėlį pasiekusių svetimžodžių žodynas. Chudinovas A.N., 1910. GRAM taikos vienetas Prancūzijoje... Rusų kalbos svetimžodžių žodynas
gramas- gramas, red. pl. gramų ir priimtinų (įprastoje reklamoje po skaitinių) gramų. Šimtas g (gramų). Norėdami apsaugoti naują formą, perskaitykite. edminka mn. Gramų skaičių pristatė žymus rusų kalbos rašytojas K. Čukovskis. Ką jis parašė knygoje „Gyvenimas kaip gyvenimas“: ... Sunkių žodžių ir žodžių žodynas dabartine rusų kalba
Gramas- GRAM, grama, žmogau. (Graikiškai gramatinis ženklas raidė). Pagrindinis vandens vienetas metrinėje sistemoje yra lygus 1 kubiniam centimetrui vandens. Gramas yra beveik 1/400 svarų. ❖ Gramo atomas (fizinis) – kalbos gramų skaičius, senesnis už atominę vazą. Tlumachny Ušakovo žodynas
gramo rentgeno nuotrauka- gramo rentgeno/n, gramo rentgeno/na, red. pl. gramų rentgenas ir gramų rentgenas... Gerai. Okremo. Per brūkšnelį.
gramas- Gramai, šis paprastas žodis gali būti vartojamas be pasiteisinimų žodynui, tarsi nebūtų dviejų sąlygų; Visų pirma, jei norite parodyti savo absoliučiai taisyklingą kalbą, tada, atėję į parduotuvę, paklauskite pardavėjo teisingos: Pasisveikinkite su manimi du šimtai gramų (ne... ... Atleidimo žodynas rusų kalba
GRAM-ATOMAS- GRAM ATOM, elemento kiekis, jo masė gramais yra panaši į jo ATOMINĖ MASĖ. Jį pakeitė sistemos vienetas СІ molis. Pavyzdžiui, vienas gramas vandens atomas (H, atominė masė = 1) prilygsta vienam gramui. b>GRAMŲ EKVIVALENTAS, vaga gramais to... ... Mokslinis ir techninis enciklopedinis žodynas
Gramas- GRAM, ah, red. pl. gramas ir gramas, žmogau. Viena masė dešimtojoje įrašų sistemoje, viena tūkstantoji kilogramo dalis. Nė gramo (ne) nieko (nesuderinamo) nitrocho, visai ne. Šie žmonės neturi sąžinės. | papildyti. gramas, oi, oi. Tlumachny...... Tlumachny Ožegovo žodynas
gramas- A; pl. red. gramai ir gramai; m [prancūzų kalba] grame] Masės vienetas metrinėje sistemoje, viena tūkstantoji kilogramo dalis. ◊ Geležies gramo nėra. Anitrohi, visai neužtenka. Kas turi L. Nė uncijos melo. Niekam nėra nė lašelio sąžinės. * * * gramas (prancūzų ... Enciklopedinis žodynas
Gramas Zenob Theophile- (Gramme) (1826-1901), elektros inžinierius. Gimė Belgijoje, kilusi iš Prancūzijos. Patentas praktiškam elektros generatoriui su žiedine armatūra (1869). Užmigusi pramoninėje elektros mašinų gamyboje. * * * GRAM Zenob ... ... Enciklopedinis žodynas
gram-atomas- kalbos kiekis gramais, skaitinis lygus atominei masei. Nerekomenduojama vartoti šio termino. Turime daug kalbų kandžių. * * * GRAM ATOM GRAM ATOM, kalbos kiekis gramais, yra skaitiniu požiūriu senesnis už jo atominę masę (div. ... Enciklopedinis žodynas
gramų molekulė- kalbos kiekis gramais, skaitiniu požiūriu lygus jo molekulinei masei. Nerekomenduojama vartoti šio termino. Turime daug kalbų kandžių. * * * GRAM MOLECULE GRAM MOLECULE, kalbos kiekis gramais, skaitine prasme lygus yo... Enciklopedinis žodynas