Кожен блог дає свою відповідь з цього приводу. Тому новачки у пошуковому просуванні часто плутаються, ось так:
Що за роботи екс ти?
Файл robots.txtабо індексний файл— звичайний текстовий документ у кодуванні UTF-8 діє для протоколів http, https, а також FTP. Файл дає пошуковим роботам поради: які сторінки/файли варто сканувати.Якщо файл містить символи не в UTF-8, а в іншому кодуванні, пошукові роботи можуть неправильно їх обробити. Правила, перелічені у файлі robots.txt, дійсні лише щодо того хоста, протоколу та номера порту, де розміщено файл.
Файл повинен розташовуватись у кореневому каталозі у вигляді звичайного текстового документа та бути доступним за адресою: https://site.com.ua/robots.txt.
В інших файлах прийнято ставити позначку BOM (Byte Order Mark). Це юнікод-символ, який використовується для визначення послідовності в байтах при зчитуванні інформації. Його кодовий символ – U+FEFF. На початку файлу robots.txt мітка послідовності байтів ігнорується.
Google встановив обмеження за розміром файлу robots.txt – він не повинен важити більше ніж 500 Кб.
Гаразд, якщо вам цікаві суто технічні подробиці, файл robots.txt є описом у формі Бекуса-Наура (BNF). При цьому використовуються правила RFC 822.
При обробці правил у файлі robots.txt пошукові роботи отримують одну з трьох інструкцій:
- частковий доступ: доступне сканування окремих елементів сайту;
- повний доступ: сканувати можна все;
- повна заборона: робот нічого не може сканувати.
При скануванні файлу robots.txt роботи отримують такі відповіді:
- 2xx -сканування пройшло успішно;
- 3xxпошуковий робот слід за переадресацією доти, доки не отримає іншої відповіді. Найчастіше є п'ять спроб, щоб робот отримав відповідь, відмінну від відповіді 3xx, потім реєструється помилка 404;
- 4xx -пошуковий робот вважає, що можна сканувати весь вміст сайту;
- 5xx -оцінюються як тимчасові помилки сервера, сканування повністю забороняється. Робот буде звертатися до файлу до тих пір, поки не отримає іншу відповідь. Пошуковий робот Google може визначити, коректно чи некоректно налаштована віддача відповідей відсутніх сторінок сайту, тобто якщо замість 404 помилки сторінка віддає відповідь 5xx, в цьому випадку сторінка буде оброблятися з кодом відповіді 404.
Поки що невідомо, як обробляється файл robots.txt, який є недоступним через проблеми сервера з виходом в інтернет.
Навіщо потрібний файл robots.txt
Наприклад, іноді роботам не варто відвідувати:
- сторінки з особистою інформацією користувачів на сайті;
- сторінки з різноманітними формами надсилання інформації;
- сайти-дзеркала;
- сторінки з результатами пошуку.
Важливо: навіть якщо сторінка знаходиться у файлі robots.txt, існує ймовірність, що вона з'явиться у видачі, якщо на неї було знайдено посилання всередині сайту або на зовнішньому ресурсі.
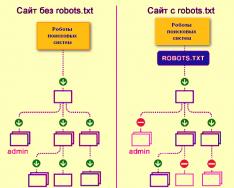
Так роботи пошукових систем бачать сайт із файлом robots.txt і без нього:

Без robots.txt та інформація, яка має бути прихована від сторонніх очей, може потрапити у видачу, а через це постраждаєте і ви, і сайт.
Так робот пошукових систем бачить файл robots.txt:

Google виявив файл robots.txt на сайті та знайшов правила, за якими слід сканувати сторінки сайту
Як створити файл robots.txt
За допомогою блокнота, Notepad, Sublime або будь-якого іншого текстового редактора.
User-agent - візитівка для роботів
User-agent - правило про те, яким роботам необхідно переглянути інструкції, описані у файлі robots.txt. На даний момент відомо 302 пошукові роботи
Вона говорить про те, що ми вказуємо правила robots.txt для всіх пошукових роботів.
Для Google головним роботом є Googlebot. Якщо ми хочемо врахувати лише його, запис у файлі буде таким:
У цьому випадку всі інші роботи будуть сканувати контент на основі своїх директив по обробці порожнього файлу robots.txt.
Для Yandex головним роботом є... Yandex:
Інші спеціальні роботи:
- Mediapartners-Google- для сервісу AdSense;
- AdsBot-Google- Для перевірки якості цільової сторінки;
- YandexImages- Індексатор Яндекс.Картинок;
- Googlebot-Image- Для картинок;
- YandexMetrika- Робот Яндекс.Метрики;
- YandexMedia- Робот, що індексує мультимедійні дані;
- YaDirectFetcher- Робот Яндекс.Директа;
- Googlebot-Video- Для відео;
- Googlebot-Mobile- для мобільної версії;
- YandexDirectDyn- Робот генерації динамічних банерів;
- YandexBlogs- Робот пошук по блогах, що індексує пости та коментарі;
- YandexMarket- Робот Яндекс.Маркета;
- YandexNews- Робот Яндекс.Новин;
- YandexDirect— завантажує інформацію про контент сайтів-партнерів Рекламної мережі, щоб уточнити їхню тематику для підбору релевантної реклами;
- YandexPagechecker- валідатор мікророзмітки;
- YandexCalendar- Робот Яндекс.Календаря.
Disallow - розставляємо цеглу
Її варто використовувати, якщо сайт знаходиться в процесі доробок, і ви не хочете, щоб він у нинішньому стані засвітився у видачі.
Важливо зняти це правило, коли сайт буде готовий до того, щоб його побачили користувачі. На жаль, про це забувають багато вебмайстрів.
приклад. Як прописати правило Disallow, щоб дати рекомендації роботам не переглядати вміст папки /papka/:


Цей рядок забороняє індексувати всі файли з розширенням.gif
Allow - направляємо роботів
Allow дозволяє сканувати будь-який файл/директиву/сторінку. Допустимо, необхідно, щоб роботи могли подивитися тільки сторінки, які починалися б з /catalog, а решту контенту закрити. У цьому випадку прописується така комбінація:

Правила Allow та Disallow сортуються за довжиною префікса URL (від меншого до більшого) та застосовуються послідовно. Якщо для сторінки підходить декілька правил, робот вибирає останнє правило у відсортованому списку.
Host - вибираємо дзеркало сайту
Host - одне з обов'язкових для robots.txt правил, воно повідомляє роботу Яндекса, яке із дзеркал сайту варто враховувати для індексації.
Дзеркало сайту – точна або майже точна копія сайту, доступна за різними адресами.
Робот не плутатиметься при знаходженні дзеркал сайту і зрозуміє, що головне дзеркало вказано у файлі robots.txt. Адреса сайту вказується без приставки http://, але якщо сайт працює на HTTPS, приставку https:// вказати потрібно.
Як потрібно прописати це правило:

Приклад файлу robots.txt, якщо сайт працює на протоколі HTTPS:

Sitemap - медична карта сайту
Sitemap повідомляє роботам, що всі URL-адреси сайту, обов'язкові для індексації, знаходяться за адресою http://site.ua/sitemap.xml. При кожному обході робот дивитиметься, які зміни вносилися до цього файлу, та швидко освіжатиме інформацію про сайт у базах даних пошукової системи.

Crawl-delay - секундомір для слабких серверів
Crawl-delay — параметр, за допомогою якого можна задати період, через який завантажуватимуться сторінки сайту. Це правило актуальне, якщо у вас слабкий сервер. У такому разі можливі великі затримки при зверненні пошукових роботів на сторінки сайту. Цей параметр вимірюється за секунди.

Clean-param — мисливець за контентом, що дублюється.
Clean-param допомагає боротися з get-параметрами для запобігання дублювання контенту, який може бути доступний за різними динамічними адресами (із питаннями). Такі адреси з'являються, якщо на сайті є різні сортування, id сесії тощо.
Допустимо, сторінка доступна за адресами:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
У такому разі файл robots.txt виглядатиме так:

Тут refвказує, звідки йде посилання, тому вона записується на самому початку, а вже потім вказується решта адреси.
Але перш ніж перейти до еталонного файлу, необхідно дізнатися про деякі знаки, які застосовуються при написанні файлу robots.txt.
Символи у robots.txt
Основні символи файлу - "/, *, $, #".
За допомогою слеша «/»ми показуємо, що хочемо закрити виявлення роботами. Наприклад, якщо стоїть один слєш у правилі Disallow, ми забороняємо сканувати весь сайт. За допомогою двох знаків слеш можна заборонити сканування будь-якої окремої директорії, наприклад: /catalog/.
Такий запис каже, що ми забороняємо сканувати весь вміст каталогу catalog, але якщо ми напишемо /catalog, заборонимо всі посилання на сайті, які будуть починатися на /catalog.
Зірочка «*»означає будь-яку послідовність символів у файлі. Вона ставиться після кожного правила.
Цей запис каже, що всі роботи не повинні індексувати будь-які файли з розширенням.gif у папці /catalog/
Знак долара «$» обмежує дії знак зірочки. Якщо необхідно заборонити весь вміст папки catalog, але при цьому не можна заборонити урли, які містять /catalog, запис в індексному файлі буде таким:
Ґрати «#»використовується для коментарів, які вебмайстер залишає для себе чи інших вебмайстрів. Робот не враховуватиме їх при скануванні сайту.
Наприклад:
Як виглядає ідеальний robots.txt

Файл відкриває вміст сайту для індексування, прописаний хост та вказана карта сайту, яка дозволить пошуковим системам завжди бачити адреси, які мають бути проіндексовані. Окремо прописані правила для Яндекса, тому що не всі роботи розуміють інструкцію Host.
Але не поспішайте копіювати вміст файлу до себе — для кожного сайту мають бути прописані унікальні правила, які залежать від типу сайту та CMS. Тому варто згадати всі правила при заповненні файлу robots.txt.
Як перевірити файл robots.txt
Якщо хочете дізнатися, чи правильно заповнили файл robots.txt, перевірте його в інструментах вебмайстрів Googleта Яндекс. Просто введіть вихідний код файлу robots.txt у форму за посиланням та вкажіть сайт, що перевіряється.
Як не потрібно заповнювати файл robots.txt
Часто при заповненні індексного файлу допускаються прикри помилки, причому вони пов'язані зі звичайною неуважністю або поспіхом. Трохи нижче чарт помилок, які я зустрічала на практиці.


2. Запис кількох папок/директорій в одній інструкції Disallow:

Такий запис може заплутати пошукових роботів, вони можуть не зрозуміти, що саме їм не слід індексувати: чи то першу папку, чи то останню, тому потрібно писати кожне правило окремо.

3. Сам файл має називатися тільки robots.txt,а не Robots.txt, ROBOTS.TXT або якось інакше.
4. Не можна залишати порожнім правило User-agent - потрібно сказати, який робот повинен враховувати прописані у файлі правила.
5. Зайві знаки у файлі (слеші, зірочки).
6. Додавання до файлу сторінок, яких не повинно бути в індексі.
Нестандартне застосування robots.txt
Крім прямих функцій індексний файл може стати майданчиком для творчості та способом знайти нових співробітників.
Ось сайт, у якому robots.txt сам є маленьким сайтом із робочими елементами і навіть рекламним блоком.




Як майданчик для пошуку фахівців, файл використовують в основному SEO-агентства. А хто ще може дізнатися про його існування? :)

А Google має спеціальний файл humans.txtщоб ви не допускали думки про дискримінацію фахівців зі шкіри та м'яса.

Висновки
За допомогою Robots.txt ви зможете задавати інструкції пошуковим роботам, рекламувати себе, свій бренд, шукати спеціалістів. Це велике поле для експериментів. Головне, пам'ятайте про грамотне заповнення файлу та типові помилки.
Правила, вони ж директиви, вони інструкції файлу robots.txt:
- User-agent — це правило про те, яким роботам необхідно переглянути інструкції, описані в robots.txt.
- Disallow пропонує рекомендацію, яку саме інформацію не варто сканувати.
- Sitemap повідомляє роботам, що всі URL-адреси сайту, обов'язкові для індексації, знаходяться за адресою http://site.ua/sitemap.xml.
- Host повідомляє роботу Яндекса, яке із дзеркал сайту варто враховувати для індексації.
- Allow дозволяє сканувати будь-який файл/директиву/сторінку.
Знаки при складанні robots.txt:
- Знак долара "$" обмежує дії знак зірочки.
- За допомогою слеша "/" ми показуємо, що хочемо закрити від виявлення роботами.
- Зірочка "*" означає будь-яку послідовність символів у файлі. Вона ставиться після кожного правила.
- Решітка «#» використовується для позначення коментарів, які пише вебмайстер для себе або інших вебмайстрів.
Використовуйте індексний файл з розумом – і сайт завжди буде у видачі.
Час читання: 7 хвилин(и)
Практично кожен проект, який приходить до нас на аудит або просування, має неправильний файл robots.txt, а нерідко він зовсім відсутній. Так відбувається тому, що при створенні файлу всі керуються своєю фантазією, а не правилами. Давайте розберемо, як правильно скласти цей файл, щоб пошукові роботи з ним ефективно працювали.
Навіщо потрібне налаштування robots.txt?
Robots.txt- це файл, розміщений у кореневому каталозі сайту, який повідомляє робота пошукових систем, до яких розділів та сторінок сайту вони можуть отримати доступ, а до яких немає.
Налаштування robots.txt – важлива частина у видачі пошукових систем, правильно налаштований robots також збільшує продуктивність сайту. Відсутність Robots.txt не зупинить пошукові системи сканувати та індексувати сайт, але якщо цього файлу у вас немає, у вас можуть виникнути дві проблеми:
Пошуковий робот зчитуватиме весь сайт, що «підірве» краулінговий бюджет. Краулінговий бюджет - це кількість сторінок, які пошуковий робот може обійти за певний проміжок часу.
Без файлу robots, пошуковик отримає доступ до чорнових та прихованих сторінок, до сотень сторінок, які використовуються для адміністрування CMS. Він їх проіндексує, а коли справа дійде до потрібних сторінок, на яких представлений безпосередній контент для відвідувачів, закінчиться краулінговий бюджет.
В індекс може потрапити сторінка входу на сайт, інші ресурси адміністратора, тому зловмисник зможе легко їх відстежити і провести атаку ddos або зламати сайт.
Як пошукові роботи бачать сайт із robots.txt і без нього:

Синтаксис robots.txt
Перш ніж почати розбирати синтаксис і налаштовувати robots.txt, подивимося на те, як має виглядати «ідеальний файл»:

Але не варто одразу ж його застосовувати. Для кожного сайту найчастіше необхідні свої налаштування, тому що у всіх у нас різна структура сайту, різні CMS. Розберемо кожну директиву по порядку.
User-agent
User-agent - визначає пошукового робота, який повинен слідувати описаним у файлі інструкціям. Якщо потрібно звернутися одразу до всіх, то використовується значок *. Також можна звернутися до певної пошукової роботи. Наприклад, Яндекс та Google:

За допомогою цієї директиви робот розуміє які файли та папки індексувати заборонено. Якщо ви хочете, щоб весь ваш сайт був відкритий для індексації, залиште значення Disallow порожнім. Щоб приховати весь контент на сайті після Disallow, поставте “/”.
Ми можемо заборонити доступ до певної папки, файлу або розширення файлу. У нашому прикладі ми звертаємося до всіх пошукових робіт, закриваємо доступ до папки bitrix, search і розширення pdf.

Allow
Allow примусово відкриває для індексування сторінки та розділи сайту. На прикладі вище ми звертаємося до пошукової роботи Google, закриваємо доступ до папки bitrix, search та розширення pdf. Але в bitrix папці ми примусово відкриваємо 3 папки для індексування: components, js, tools.

Host - дзеркало сайту
Дзеркало сайту – це дублікат основного сайту. Дзеркала використовуються для різних цілей: зміна адреси, безпека, зниження навантаження на сервер і т.д.
Host – одне з найважливіших правил. Якщо прописане це правило, то робот зрозуміє, яке із дзеркал сайту варто враховувати для індексації. Ця директива необхідна для роботів Яндекса та Mail.ru. Інші роботи це правило ігноруватимуть. Host прописується лише один раз!
Для протоколів "https://" та "http://", синтаксис у файлі robots.txt буде різним.
Sitemap - карта сайту
Карта сайту - це форма навігації сайтом, яка використовується для інформування пошукових систем про нові сторінки. За допомогою директиви sitemap ми «насильно» показуємо роботу, де розташована карта.

Символи у robots.txt
Символи, що застосовуються у файлі: "/, *, $, #".

Перевірка працездатності після налаштування robots.txt
Після того як ви розмістили Robots.txt на своєму сайті, вам необхідно додати та перевірити його у вебмайстрі Яндекса та Google.
Перевірка Яндекса:
- Перейдіть за посиланням .
- Виберіть: Налаштування індексування – Аналіз robots.txt.
Перевірка Google:
- Перейдіть за посиланням .
- Виберіть: Сканування - інструмент перевірки файлу robots.txt.
Таким чином ви зможете перевірити свій robots.txt на помилки і внести необхідні налаштування, якщо потрібно.
- Вміст файлу необхідно писати великими літерами.
- У директиві Disallow потрібно вказувати лише один файл або директорію.
- Рядок «User-agent» не повинен бути порожнім.
- User-agent завжди має йти перед Disallow.
- Не слід забувати прописувати слеш, якщо потрібно заборонити індексацію директорії.
- Перед завантаженням файлу на сервер обов'язково потрібно перевірити його на наявність синтаксичних та орфографічних помилок.
Успіхів вам!
Відеоогляд 3 методів створення та налаштування файлу Robots.txt
Ми випустили нову книгу «Контент-маркетинг у соціальних мережах: Як засісти в голову передплатників та закохати їх у свій бренд».

Директива Host – це команда або правило, що повідомляє пошукову машину про те, яке (з www або без) вважати основним. Знаходиться директива Host у файлі та призначена виключно для Яндекса.
Часто виникає необхідність, щоб пошукова система не індексувала деякі сторінки сайту чи його дзеркала. Наприклад, ресурс знаходиться на одному сервері, однак в інтернеті є ідентичне доменне ім'я, за яким здійснюється індексація та відображення результатів пошукової видачі.
Пошукові роботи Яндекса обходять сторінки сайтів та додають зібрану інформацію до бази даних за власним графіком. У процесі індексації вони самостійно вирішують, яку сторінку потрібно опрацювати. Наприклад, роботи обходять стороною різні форуми, дошки оголошень, каталоги та інші ресурси, де індексація безглузда. Також вони можуть визначати головний сайт та дзеркала. Перші підлягають індексації, другі – ні. У процесі часто виникають помилки. Вплинути на це можна шляхом використання директиви Host у файл Robots.txt.
Навіщо потрібний файл Robots.txt
Robots – це типовий текстовий файл. Його можна створити через блокнот, проте працювати з ним (відкривати та редагувати інформацію) рекомендується у текстовому редакторі Notepad++. Необхідність файлу при оптимізації веб-ресурсів обумовлюється кількома факторами:
- Якщо файл Robots.txt відсутній, веб-сайт буде постійно перевантажений через роботу пошукових машин.
- Існує ризик, що індексуватимуться зайві сторінки або сайти дзеркала.
Індексація буде проходити набагато повільніше, а при неправильно встановлених налаштуваннях він може зникнути з результатів пошукової видачі Google і Яндекс.
Як оформити директиву Host у файлі Robots.txt
Файл Robots включає директиву Host - інструкцію для пошукової машини про те, де головний сайт, а де його дзеркала.
Директива має таку форму написання: Host: [необов'язковий пропуск] [значення] [необов'язковий пропуск]. Правила написання директиви вимагають дотримання наступних пунктів:
- Наявність у директиві Host протоколу HTTPS підтримки шифрування. Його необхідно використовувати, якщо доступ до дзеркала здійснюється лише захищеним каналом.
- Ім'я домену, що не є IP-адресою, а також номер порту веб-ресурсу.
Коректно складена директива дозволить веб-майстру позначити для пошукових машин де головне дзеркало. Інші будуть вважатися другорядними і, отже, не індексуватимуться. Як правило, дзеркала можна відрізнити за наявністю або відсутністю абревіатури www. Якщо користувач не вкаже головне дзеркало веб-ресурсу за допомогою Host, пошукова система Яндекс надішле відповідне повідомлення у Вебмайстер. Також повідомлення буде надіслано, якщо у файлі Роботс задана суперечлива директива Host.
Визначити, де головне дзеркало сайту можна через пошукову систему. Необхідно вбити адресу ресурсу в пошуковий рядок і подивитися на результати видачі: сайт, де перед доменом в адресному рядку стоїть www, є головним доменом.
Якщо ресурс не відображається на сторінці видачі, користувач може самостійно призначити його головним дзеркалом, перейшовши у відповідний розділ в Яндекс.Вебмайстрі. Якщо веб-майстру необхідно, щоб доменне ім'я сайту не містило www, слід не вказувати його у Хості.
Багато веб-майстрів використовують кириличні домени як додаткові дзеркала для своїх сайтів. Однак у директиві Host кирилиця не підтримується. Для цього необхідно дублювати слова на латиниці, за умови, що їх можна буде легко дізнатися, скопіювавши адресу сайту з адресного рядка.
Хост у файлі Роботс
Головне призначення цієї директиви полягає у вирішенні проблем із дублюючими сторінками. Використовувати Host необхідно у разі, якщо робота веб-ресурсу орієнтована на російськомовну аудиторію та, відповідно, сортування сайту має відбуватися у системі Яндекса.
Не всі пошукові системи підтримують роботу директиви Хост. Функція доступна лише в Яндексі. При цьому навіть тут немає гарантій, що домен буде призначений як головне дзеркало, але, як запевняє сам Яндекс, пріоритет завжди залишається за ім'ям, яке вказано в хості.
Щоб пошукові машини правильно зчитували інформацію під час обробки файлу robots.txt, необхідно прописувати директиву Host у відповідну групу, що починається після слів User-Agent. Однак, роботи зможуть використовувати Host незалежно від того, чи буде директива прописана за правилами чи ні, оскільки вона є міжсекційною.
Ми випустили нову книгу «Контент-маркетинг у соціальних мережах: Як засісти в голову передплатників та закохати їх у свій бренд».

Robots.txt - це текстовий файл, який містить відомості для пошукових роботів, які допомагають проіндексувати сторінки порталу.
Більше відео на нашому каналі - вивчайте інтернет-маркетинг із SEMANTICA
![]()
Уявіть, що ви поїхали за скарбами на острів. Ви маєте карту. Там вказано маршрут: “Підійти до великого пня. Від нього зробити 10 кроків на схід, потім дійти до урвища. Повернути праворуч, знайти печеру”.
Це – вказівки. Наслідуючи їх, ви йдете маршрутом і знаходите скарб. Приблизно працює і пошуковий бот, коли починає індексувати сайт або сторінку. Він знаходить файл robots.txt. У ньому зчитує, які сторінки потрібно проіндексувати, а які – ні. І, дотримуючись цих команд, він обходить портал і додає його сторінки в індекс.
Для чого потрібний robots.txt
Починають ходити сайтами і індексувати сторінки після того, як сайт завантажений на хостинг і прописані dns. Вони роблять свою роботу незалежно від того, є у вас якісь технічні файли чи ні. Роботс вказує пошукачам, що при обході веб-сайту потрібно враховувати параметри, які в ньому знаходиться.
Відсутність файлу robots.txt може спричинити проблеми зі швидкістю обходу сайту та присутності сміття в індексі. Некоректне налаштування файлу загрожує виключенням з індексу важливих частин ресурсу та присутністю у видачі непотрібних сторінок.
Усе це, як наслідок, веде до проблем із просуванням.
Розглянемо докладніше, які вказівки містяться в цьому файлі, як вони впливають на поведінку робота у вас на веб-сайті.
Як зробити robots.txt
Спочатку перевірте, чи є у вас цей файл.
Введіть в адресному рядку браузера адресу сайту та через слеш ім'я файлу, наприклад https://www.xxxxx.ru/robots.txt
Якщо файл присутній, на екрані з'явиться список параметрів.

Якщо файлу немає:
- Файл створюється у звичайному текстовому редакторі нібито блокнота чи Notepad++.
- Потрібно встановити ім'я robots, розширення.txt. Внести дані з урахуванням прийнятих стандартів оформлення.
- Можна перевірити на предмет помилок за допомогою сервісів типу вебмайстра Яндекса. Там потрібно вибрати пункт «Аналіз robots.txt» у розділі «Інструменти» та дотримуватися підказок.
- Коли файл готовий, залийте його до кореневого каталогу сайту.
Правила налаштування
У пошукачів не один робот. Деякі роботи індексують тільки текстовий контент, деякі - тільки графічний. Та й у самих пошукових систем схема роботи краулерів може бути різною. При складанні файлу це потрібно враховувати.
Деякі з них можуть ігнорувати частину правил, наприклад GoogleBot не реагує на інформацію про те, яке дзеркало сайту вважати головним. Але в цілому вони сприймають і керуються файлом.
Синтаксис файлу
Параметри документа: ім'я робота (бота) «User-agent», директиви: роздільна здатність «Allow» і забороняюча «Disallow».
Зараз є дві ключові пошукові системи: Яндекс і Google, відповідно, важливо при складанні сайту враховувати вимоги обох.
Формат створення записів виглядає так, зверніть увагу на обов'язкові прогалини та порожні рядки.

Директива User-agent
Робот шукає записи, які починаються з User-agent, там мають бути вказівки на назву пошукового робота. Якщо воно не вказано, вважається, що доступ роботів необмежений.
Директиви Disallow та Allow
Якщо потрібно заборонити індексацію у robots.txt, використовують Disallow. З її допомогою обмежують доступ робота до сайту або деяких розділів.
Якщо роботс.тхт не містить жодної директиви «Disallow», що забороняє, вважається, що дозволена індексація всього сайту. Зазвичай заборони прописуються після кожного робота окремо.
Вся інформація, яка вказана після значка #, є коментарями та не зчитується машиною.
Allow застосовують, щоб дозволити доступ.
Символ зірочка служить вказівкою на те, що стосується всіх: User-agent: *.
Такий варіант, навпаки, означає повну заборону індексації всім.
Заборона перегляду вмісту певної папки-каталогу
Для блокування одного файлу потрібно вказати його абсолютний шлях
Директиви Sitemap, Host
Для Яндекса прийнято вказувати, яке дзеркало ви хочете призначити головним. А Google, як ми пам'ятаємо, його ігнорує. Якщо немає дзеркал, просто зафіксуйте, як вважаєте коректним писати ім'я вашого веб-сайту з www або без.
Директива Clean-param
Її можна застосовувати, якщо URL сторінок веб-сайту містять параметри, що змінюються, не впливають на їх вміст (це можуть бути id користувачів, реферерів).
Наприклад, адресою сторінок «ref» визначає джерело трафіку, тобто. свідчить про те, звідки на сайт прийшов відвідувач. Для всіх користувачів сторінка буде однакова.
Роботу можна вказати на це, і він не завантажуватиме повторювану інформацію. Це знизить завантаженість сервера.
Директива Crawl-delay
За допомогою можна визначити, з якою частотою бот завантажуватиме сторінки для аналізу. Ця команда застосовується, коли сервер перевантажений і вказує на те, що процес обходу потрібно прискорити.
Помилки robots.txt
- Файл не знаходиться у кореневому каталозі. Глибоший робот його шукати не буде і не врахує.
- Літери у назві мають бути маленькі латинські.
Помилка у назві, іноді втрачають букву S на кінці та пишуть robot. - Не можна використовувати кирилиці у файлі robots.txt. Якщо потрібно вказати домен російською мовою, використовуйте формат у спеціальному кодуванні Punycode.
- Це метод перетворення доменних імен на послідовність ASCII-символів. Для цього можна скористатися спеціальними конвертерами.
Виглядає таке кодування так:
сайт.рф = xn--80aswg.xn--p1ai
Додаткову інформацію, що закривати в robots txt та за налаштуваннями відповідно до вимог пошуковиків Google та Яндекс можна знайти у довідкових документах. Для різних cms можуть бути свої особливості, це слід врахувати.
коментарів немаєФайл robots.txt створюється спеціально для пошукових роботів, щоб вони знали куди йти та індексувати, а куди вхід заборонено. Якщо неправильно налаштувати його, ви можете взагалі не потрапити в пошук або потрапити тільки в деяких.
Щоб не було проблем із просуванням та індексацією статей, вам потрібно знати, як створити robots txt для всіх пошукових систем. Це займає мало часу, але після цього ви будете спокійні.
Деякі вебмайстри взагалі обходяться без нього (в основному, звичайно, через незнання). З одного боку, це розумно для новачків – так ви точно не закриєте від пошукових роботів потрібну інформацію. Але з іншого боку, цей невеликий файл захищає особисті дані та не дає спам-ботам переглядати інформацію на сайті.
Початківцям блогерам я рекомендую використовувати шаблони. Наприклад, шаблон robots txt для WordPress. Завантажте і виправте ваш сайт.

Розшифрування значень:
- User-agent: * - Ви звертаєтеся відразу до всіх пошукових систем, Yandex - тільки до Яндексу.
- Disallow: перелічені папки та файли, які заборонені для індексації
- Host – пропишіть назву вашого сайту без www.
- Sitemap: посилання на XML-картку сайту.
Файл помістіть до кореневої директорії сайту за допомогою Filezilla або через сайт хостера. Скидайте до головної директорії, щоб він був доступний за посиланням: ваш_сайт.ру/robots.txt
Він підійде лише тим, хто має ЧПУ (посилання прописані словами, а чи не як p=333). Достатньо зайти в Налаштування – Постійні посилання, вибрати нижній варіант та в полі прописати /%postname%
Деякі вважають за краще створювати цей файл самостійно:
Для початку створіть блокнот на комп'ютері та назвіть його robots (не використовуйте верхній регістр). Наприкінці налаштувань його розмір не повинен перевищувати 500 кб.
User-agent- Назва пошукової системи (Yandex, Googlebot, StackRambler). Якщо ви хочете звернутися відразу до всіх, поставте зірочку *

А потім вкажіть сторінки або папки, які не можна індексувати цю роботу за допомогою Disallow:

Спочатку перераховані три директорії, та був конкретний файл.
Щоб дозволити індексувати все та всім, потрібно прописати:
User-agent: *
Disallow:
Налаштування robots.txt для Яндекс та Google
Для Яндексаобов'язково потрібно додати директиву host, щоб не з'являлося дублі сторінок. Це слово розуміє тільки бот від Яндекса, тому прописуйте вказівки для нього окремо.

Для Googleнемає жодних доповнень. Єдине, треба знати, як до нього звертатися. У розділі User-agent потрібно писати:
- Googlebot;
- Googlebot-Image – якщо обмежуєте індексацію зображень;
- Googlebot-Mobile – для мобільної версії сайту.
Як перевірити працездатність файлу robots.txt
Це можна зробити в розділі «Інструменти для веб-майстрів» від пошукової системи Google або на сайті Яндекс.Вебмайстер у розділі Перевірити robots.txt.
Якщо будуть помилки, виправте їх та перевірте ще раз. Досягніть хорошого результату, потім не забудьте скопіювати правильний код в robots.txt і залити його на сайт.
Тепер ви маєте уявлення, як створити robots.txt для всіх пошукових систем. Початківцям рекомендую використовувати готовий файл, підставивши назву свого сайту.
Поломки