Блогът за кожата дава своето доказателство за това желание. Ето защо новодошлите в pokey индустрията често се губят, така че нещата изглеждат така:
Какъв вид роботизиран бивш?
Файл robots.txtили друго Индекс файл— първичният текстов документ, кодиран в UTF-8, е подходящ за протоколите http, https и FTP. Файлът се предоставя на роботите за търсене в името на: кои страници/файлове се сканират.Ако файлът съдържа знаци не в UTF-8, а в друго кодиране, роботите за търсене може да ги обработят неправилно. Правилата, изброени във файла robots.txt, са валидни в зависимост от хоста, протокола и номера на порта, където се намира файлът.
Файлът трябва да бъде инсталиран в главната директория под формата на първичен текстов документ и е достъпен на адрес: https://site.com.ua/robots.txt.
В други файлове е обичайно да се поставя иконата BOM (Byte Order Mark). Това е Unicode символ, който се използва за указване на последователността в байтове при четене на информация. Кодовият символ е U+FEFF. Маркировката за последователност от байтове във файла robots.txt се игнорира.
Google е поставил ограничения за размера на файла robots.txt – не сте длъжни да въвеждате повече от 500 KB.
Garazd, тъй като имате нужда от някои технически подробности, файлът robots.txt е описан във формуляра на Beckus-Naur (BNF). В този случай се преразглеждат правилата на RFC 822.
Когато анализират правилата от файла robots.txt, роботите за търсене ще изведат една от трите инструкции:
- частен достъп: не е налично сканиране на други елементи от сайта;
- универсален достъп: всичко може да се сканира;
- пълна ограда: роботът не може да сканира нищо.
Когато сканират файла robots.txt, роботите ще открият следните типове отговори:
- 2xx -сканирането е успешно;
- 3xxЗвуковият робот следва пренасочването на данните, но не отхвърля други входове. Най-често има пет теста за робота, за да улови сигнала, като извади от линията 3xx, след което се регистрира грешка 404;
- 4xx -Роботът за търсене оценява, че можете да сканирате целия сайт;
- 5xx -се оценява като навременни повреди на сървъра, сканирането е напълно блокирано. Роботът ще продължи да превърта през файла, докато отхвърли друго въвеждане. Роботът за търсене на Google може да определи дали изходът на различни страници в сайта е коригиран правилно или неправилно, така че вместо 404 отговора страницата да изведе версия 5xx, в който случай страницата ще бъде Обадете се с кода на реда 404.
Все още не е известно как се генерира файлът robots.txt, който е недостъпен поради проблеми със сървъра с достъп до интернет.
И накрая, необходимия файл robots.txt
Например, понякога роботите не са добри в доставянето на:
- страници със специална информация за клиенти на сайта;
- страници с различни форми на споделяне на информация;
- огледала за уебсайтове;
- страници с резултати от търсенето.
Важно: тъй като страницата се намира във файла robots.txt, е ясно, че тя ще се появи, ако на сайта или на външен ресурс е намерено съобщение на нея.
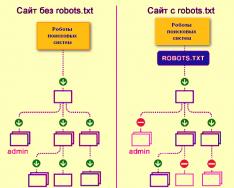
Ето как роботите на търсачките обхождат уебсайт със или без файла robots.txt:

Без robots.txt информацията, която е заснета от трети страни, може да бъде изгубена от изглед и от това вие и сайтът ще пострадате.
Ето как роботът на системите за търсене изтегля файла robots.txt:

Google идентифицира файла robots.txt на сайта и знае правилата зад обхождането на страниците на сайта
Как да създадете файл robots.txt
Използвайте Notepad, Notepad, Sublime или друг текстов редактор.
User-agent - визитка за роботи
Потребителски агент - правило за онези роботи, които трябва да следват инструкциите, описани във файла robots.txt. В момента се виждат 302 робота за търсене
Нека да поговорим за тези, които задаваме на robots.txt правила за всички роботи за търсене.
За Google основният робот е Googlebot. Ако искаме да защитим нещо друго, записът във файла ще бъде така:
В този случай всички други роботи ще обхождат съдържание въз основа на техните директиви за обработка на празния файл robots.txt.
За Yandex основният робот е... Yandex:
Други специални роботи:
- Mediapartners-Google- за услугата AdSense;
- AdsBot-Google- Проверка на рамката от цялата страна;
- YandexImages- Индексатор на Yandex.Images;
- Изображение на Googlebot- За снимки;
- YandexMetrika- робот Yandex.Metrica;
- YandexMedia- Робот, който индексира мултимедийни данни;
- YaDirectFetcher- Yandex.Direct робот;
- Googlebot-видео- За видео;
- Googlebot-Mobile- за мобилна версия;
- YandexDirectDyn- Роботизирано генериране на динамични банери;
- YandexBlogs- Роботът търси блогове, които индексират публикации и коментари;
- YandexMarket- робот Yandex.Market;
- YandexNews- робот Yandex.Novin;
- YandexDirect— събира информация за съдържанието на партньорските сайтове на Рекламната медия с цел изясняване на техните теми за избор на подходяща реклама;
- YandexPagechecker- валидатор за микромаркиране;
- YandexCalendar- Yandex.Calendar робот.
Disallow - задаване на цел
Внимаваме за това, защото сайтът е в процес на финализиране и не искате той да бъде изложен по никакъв начин.
Важно е да знаете това правило, ако сайтът е готов, преди да бъде развален от потребителите. За съжаление, много уеб администратори забравят за това.
дупето. Как да напишем правило за забрана, така че роботите да не гледат датата на препоръката вместо папката /папка/:


Този ред блокира индексирането на всички файлове с extensions.gif
Разрешаване - насочване на роботи
Allow ви позволява да сканирате всеки файл/директива/страна. Възможно е, но е необходимо роботите да виждат само страници, които са започнали без /catalog, и да затварят съдържанието. За кой тип е предписана следната комбинация:

Правилата за разрешаване и забрана са сортирани по URL префикс (от най-малкия към най-големия) и подредени последователно. Ако една страница е подходяща за дузина правила, роботът избира оставащото правило от сортирания списък.
Хост - изберете огледален сайт
Хостът е едно от задължителните правила за robots.txt, той информира робота Yandex, че огледалният сайт трябва да се използва за индексиране.
Огледало на сайта - точно или точно копие на сайта, достъпно на различни адреси.
Роботът няма да се лута, ако има огледала на сайта и е ясно, че огледалото е посочено във файла robots.txt. Адресите на сайтовете трябва да се въвеждат без префикса http://; в противен случай, ако сайтът работи на HTTPS, трябва да се посочи префиксът https://.
Как да запиша това правило:

Пример за файла robots.txt, тъй като сайтът работи на HTTPS протокол:

Sitemap - медицинска карта на сайта
Sitemap информира роботите, че всички URL адреси на сайт, които изискват индексиране, се намират на http://site.ua/sitemap.xml. По време на обхождане на кожата, роботът ще разбере какви промени са направени в този файл и бързо ще актуализира информацията за сайта в базите данни на системата за търсене.

Crawl-delay - хронометър за слаби сървъри
Забавяне при обхождане е параметър, който ви позволява да посочите периода, през който страниците на сайта ще бъдат обхождани. Това правило е по-подходящо, ако имате слаб сървър. В този случай може да има големи проблеми с внедряването на роботи за търсене от страна на сайта. Този параметър се променя за секунди.

Clean-param - грижа за съдържание, което се дублира.
Clean-param помага да се справят с get-parameters, за да се предотврати дублиране на съдържание, което може да е достъпно на различни динамични адреси (от канали). Такива адреси се появяват, защото сайтът има различно сортиране, идентификатори на сесии и т.н.
Възможно е страницата да е достъпна на следните адреси:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В този случай файлът robots.txt изглежда така:

Тук рефпоказва, че известието е изпратено, пише го на самата страница и след това се посочва адреса.
Преди да отидете на референтния файл, трябва да сте наясно с определени знаци, които ще се прилагат, когато пишете файла robots.txt.
Символи в robots.txt
Основните знаци за файла са "/, *, $, #".
За допълнителна помощ наклонена черта "/"Показваме какво искаме да покрием с роботи. Например, ако правилото Disallow има една наклонена черта, това предотвратява обхождането на целия сайт. Използвайки две наклонени черти, можете да блокирате сканирането на всяка друга директория, например: /каталог/.
Такъв запис би означавал, че ще сканираме цялото нещо в директорията на каталога и ако напишем /catalog, ще блокираме всички публикации в сайта, които започват с /catalog.
Зирочка "*"означава каквато и да е последователност от знаци във файла. Трябва да се постави след правилото за кожата.
Този запис предполага, че не всички роботи са виновни за индексирането на файлове с разширение .gif в папката /каталог/
знак за долар «$» заобиколен от звезден знак. Ако трябва да защитите цялата папка на каталога, в противен случай не можете да защитите URL адреси като /catalog, записът в индексния файл ще бъде така:
Тип "#" Vikorist за коментари, че уебмастърът се лишава от други уебмастъри. Роботът не носи отговорност за сканирането на сайта.
Например:
Как изглежда идеалният robots.txt

Файлът се качва на сайта за индексиране, хостът се регистрира и се предоставя карта на сайта, която позволява на търсачките да извличат адреси, които могат да бъдат индексирани. Правилата за Yandex са ясно посочени, защото не всички роботи разбират инструкциите на хоста.
Просто не бързайте да копирате файла в себе си - всеки сайт може да има уникални правила, в зависимост от типа на сайта и CMS. Ето защо трябва да запомните всички правила, когато попълвате файла robots.txt.
Как да проверите файла robots.txt
Ако искате да сте сигурни, че сте попълнили файла robots.txt правилно, проверете го в Инструменти за уеб администратори Googleи Yandex. Просто въведете изходния код във файла robots.txt във формуляра за изпращане и посочете сайта, който се проверява.
Как да запазите файла robots.txt
Често при попълване на индексния файл се допускат секрети и това се дължи на крайно неуважение или прибързаност. Няколко пъти по-ниска от таблицата за помилвания, която научих на практика.


2. Записване на множество папки/директории в една инструкция за забрана:

Такъв запис може да обърка звуковите роботи, те може да не осъзнаят, че самите те не трябва да бъдат индексирани: независимо дали стартирам папката или я оставям, трябва внимателно да напиша правило за кожата.

3. Самият файл може да бъде извикан само robots.txt,а не Robots.txt, ROBOTS.TXT или по друг начин.
4. Не е възможно да се анулира правилото User-agent - необходимо е да се каже кой робот е отговорен за промяната на правилата, записани във файла.
5. Обезопасяване на маркировки от файла (наклонени черти, звезди).
6. Добавяне към файла на страници, които не е задължително да присъстват в индекса.
Нестандартни robots.txt
В допълнение към преките си функции, индексният файл може да се превърне в източник на креативност и начин за намиране на нови доброволци.
Това е сайт, където robots.txt е малък сайт с работещи елементи и рекламен блок.




Като майданчик за търсене на фалшификати, файлът се използва предимно от SEO агенции. Кой друг може да разбере за вашата мечта? :)

И Google съхранява специален файл хора.txtЗа да не допускате мисли за дискриминация на фахивците заради кожата и месото им.

Visnovki
С помощта на Robots.txt можете да давате инструкции за търсене на роботи, да рекламирате себе си, вашата марка и специалисти по шеги. Това е чудесно поле за експерименти. Головни, не забравяйте за правилното попълване на файлове и стандартното почистване.
Правила, миришат на директиви, миришат на инструкции към файла robots.txt:
- User-agent е правило за онези роботи, които трябва да следват инструкциите, описани в robots.txt.
- Disallow представлява препоръка, че самата информация не може да бъде сканирана.
- Sitemap информира роботите, че всички URL адреси към сайт, които изискват индексиране, се намират на http://site.ua/sitemap.xml.
- Домакинът информира робота Yandex, че огледалният сайт трябва да бъде нает за индексиране.
- Allow ви позволява да сканирате всеки файл/директива/страна.
Знаци при сгъване на robots.txt:
- Знакът за долар "$" е заобиколен от знак със звезда.
- След наклонената черта "/" показваме това, което искаме да скрием от откриване от роботи.
- Звездата "*" означава каквато и да е последователност от знаци във файла. Трябва да се постави след правилото за кожата.
- Хешът „#“ се използва за маркиране на коментари, които даден уеб администратор пише за себе си или за други уеб администратори.
Използвайте разумно индексния файл - и сайтът ще бъде видим в бъдеще.
Час за четене: 7 hwilin(s)
Почти всеки проект, който идва при нас за одит или проверка, съдържа неправилен файл robots.txt и често в целия ден. Така изглежда, че когато се създава файл, всеки се ръководи от въображението си, а не от правилата. Нека да разберем как правилно да сгънем този файл, така че роботите за търсене да могат да работят с него ефективно.
Има ли нужда от подобряване на robots.txt?
Robots.txt- този файл се намира на сайта на root catalosis, който се съобщава от робота на търсачката, до кои секции и страници на сайта може да им бъде отказан достъп, но до кои няма достъп.
Коригирането на robots.txt е важна част от системите на търсачките; правилното настройване на роботите също така повишава производителността на сайта. Наличието на Robots.txt не позволява на търсачките да обхождат и индексират сайта, в противен случай, ако нямате този файл, може да срещнете два проблема:
Роботът за търсене чете целия сайт, така че „помита“ бюджета за обхождане. Бюджетът за обхождане е толкова много сайтове, колкото един робот за търсене може да навигира само за един час.
Без robots файл, търсачката отказва достъп до черно-бели страници, до стотици страници, които се използват за администриране на CMS. Той ги индексира и ако отидете на правилните страници вдясно, на които се представят най-важните за издателите съдържание, бюджетът за обхождане ще приключи.
Индексът може да използва страницата за влизане в сайта и други администраторски ресурси, така че нападателят може лесно да получи достъп до тях и да извърши DDoS атака или злонамерен софтуер на сайта.
Как да търсите роботи за изтегляне на сайт с помощта на robots.txt и без него:

Синтаксис на robots.txt
Първо започнете да разбирате синтаксиса и персонализирайте robots.txt в зависимост от това как изглежда „идеалният файл“:

Ale ne varto razu z yogo zastosovuvati. За всеки сайт най-често се налага да има свои корекции, защото всички имаме различна структура на сайта, различен CMS. Нека да разгледаме директивата за кожата по ред.
Потребителски агент
Потребителски агент - означава робот за търсене, който трябва да следва инструкциите, описани във файла. Ако трябва да се върнете към всички наведнъж, ще се появи иконата *. Можете също така да ескалирате до пеещ звуков робот. Например Yandex и Google:

За допълнителната цел на директивата, роботът разбира кои файлове и папки за индексиране са блокирани. Ако искате целият ви сайт да бъде отворен за индексиране, оставете стойността Disallow празна. За да приемете цялото съдържание на сайта след Disallow, поставете “/”.
Можем да блокираме достъпа до папка с песни, файл или файлово разширение. Нашето приложение затваря всички търсачки, блокира достъпа до папките bitrix, search и pdf.

Позволява
Allow Primus се отваря за индексиране на страници и секции от сайта. В приложението преминаваме към роботи за търсене на Google, блокирайки достъпа до папката bitrix, разширението за търсене и pdf. В папката Bitrix отваряме 3 папки за индексиране: компоненти, js, инструменти.

Хост - огледален сайт
Огледален сайт е дубликат на основния сайт. Огледалата се използват за различни цели: промяна на адреса, сигурност, намаляване на трафика на сървъра и др.
Домакинът е едно от най-важните правила. Ако това правило е написано, тогава роботът ще разбере, че от огледалата на сайта ще бъде приет за индексиране. Тази директива е необходима за роботите Yandex и Mail.ru. Други роботи обикновено се игнорират. Хостът трябва да бъде регистриран само веднъж!
За протоколите "https://" и "http://" синтаксисът на файла robots.txt ще бъде различен.
Sitemap - карта на сайта
Картата на сайта е форма на навигация на сайта, която се използва за информиране на търсачките за нови страници. Следвайки допълнителната директива за карта на сайта, ние „принудително“ показваме на робота, че картата е премахната.

Символи в robots.txt
Знаците, които се появяват във файл, са: “/, *, $, #”.

Проверка на ефективността на процеса след коригиране на robots.txt
След като поставите Robots.txt на уебсайта си, трябва да го добавите и потвърдите с уеб администратора на Yandex и Google.
Проверка на Yandex:
- Следвайте инструкциите.
- Изберете: Коригирано индексиране – Анализ на robots.txt.
Google проверка:
- Следвайте инструкциите.
- Изберете: Сканиране - инструмент за проверка на файла robots.txt.
По този начин можете да проверите вашия robots.txt за промени и да направите необходимите корекции, ако е необходимо.
- Вместо файла е необходимо да се пише с големи букви.
- Директивата Disallow изисква указване на поне един файл или директория.
- Не е необходимо редът „Потребителски агент“ да е празен.
- Потребителският агент може винаги да е преди Disallow.
- Не забравяйте да включите наклонената черта, ако трябва да защитите директорията от индексиране.
- Преди да качите файл на сървъра, трябва да го проверите за синтактични и правописни грешки.
Късмет!
Видео преглед на 3 метода за създаване и настройка на файла Robots.txt
Публикувахме нова книга „Маркетинг на съдържание в социалните медии: Как да влезете в главите на предплащащите и да ги объркате с вашата марка.“

Директивата Host е команда или правило, което информира търсачката за тези (с или без www), които са важни. Изглежда, че директивата Host на файла е присвоена изключително на Yandex.
Често има нужда да се гарантира, че търсачката не индексира страниците на вашия огледален сайт. Например ресурсът се намира на един сървър, но в Интернет е идентичен с името на домейна, което отговаря за индексирането и показването на резултатите от търсенето.
Роботите за търсене на Yandex заобикалят страните на уебсайтовете и добавят събраната информация към базата данни зад текущия график. По време на процеса на индексиране проблемите възникват сами, коя страна трябва да се обработи. Например, роботите трябва да избягват различни форуми, търсачки, каталози и други ресурси, де индексират без объркване. Същата воня може да се намери в основния сайт и огледалото. Първите насърчават индексирането, другите не. Процесът често страда от проблеми. В центъра можете да използвате директивата Host във файла Robots.txt.
Ето необходимия файл Robots.txt
Robots е типичен текстов файл. Можете да го създадете с помощта на Notepad; можете да работите с него (отваряне и редактиране на информация) с помощта на текстовия редактор Notepad++. Необходимостта от файл при оптимизиране на уеб ресурси се определя от няколко фактора:
- Ако файлът Robots.txt бъде публикуван, уебсайтът ще бъде постоянно посещаван отново чрез роботите на звуковите машини.
- Ясно е, че всички страници и огледални сайтове ще бъдат индексирани.
Индексирането ще бъде много по-бързо и ако настройките са инсталирани неправилно, може да се загубите в резултатите от търсенето от Google и Yandex.
Как да форматирате директивата Host във файла Robots.txt
Файлът Robots включва директивата Host - инструкции за търсачката както за основния сайт, така и за огледалото.
Директивата е написана в следната форма: Хост: [неезиков пропуск] [значение] [неезиков пропуск]. Правилата за писане на директиви изискват следните стъпки:
- Директивата Host към HTTPS протокола поддържа криптиране. Това трябва да се коригира, защото достъпът до огледалото е ограничен от откраднат канал.
- Името на домейна, което не е IP адрес, както и номера на порта на уеб ресурса.
Правилно е съставена директивата, позволяваща на уебмастъра да означава за звуковите машини de smut dzerkalo. Други ще бъдат уважавани от други и следователно няма да бъдат индексирани. По правило огледалата могат да бъдат разграничени от наличието или отсъствието на съкращението www. Тъй като кореспондентът дори не отразяваше уеб ресурса зад помощта на Host, системата за търсене Yandex беше най-добрият източник на информация от Webmaster. Същото известие ще бъде изпратено, ако файлът Robots има свръхчувствителна директива Host.
Значение, сайтът de golovne dzerkalo е възможен чрез системата за търсене. Трябва да въведете адреса на ресурса в реда за търсене и да погледнете резултатите: сайт с www пред домейна в адресния ред и главния домейн.
Ако ресурсът не се показва от страната на изгледа, потребителите могат самостоятелно да го разпознаят като главно огледало, като се преместят във вторичната секция в Yandex.Webmaster. Тъй като уеб администраторът трябва да се увери, че името на домейна на сайта не е неправилно поставено www, то не трябва да се посочва от Хоста.
Много уебмастъри използват домейни на кирилица като допълнителни огледала за своите сайтове. Директивата Host обаче не поддържа кирилица. За целта е необходимо думите да се дублират на латиница, за да могат лесно да се разпознават чрез копиране на адреса на сайта от адресния ред.
Хост във файлови роботи
Основната цел на тази директива се крие в повечето проблеми от дублирани страни. Необходимо е да се класира Host, тъй като уеб ресурсът е насочен към руска аудитория и, очевидно, сортирането на сайта може да се извърши от системата Yandex.
Не всички звукови системи поддържат директивата Host. Функцията е достъпна само в Yandex. Въпреки това, няма гаранция, че домейнът ще бъде присвоен като огледален образ, но, както казва самият Yandex, приоритетът винаги ще бъде загубен за имената, посочени в хоста.
За да могат търсачките да четат правилно информацията при обработката на файла robots.txt, е необходимо да добавите директивата Host към съответната група, която започва след User-Agent. Въпреки това, роботите могат да използват хоста, независимо от факта, че директивата е написана според правилата на страната, стига да е напречно сечение.
Публикувахме нова книга „Маркетинг на съдържание в социалните медии: Как да влезете в главите на предплащащите и да ги объркате с вашата марка.“

Robots.txt е текстов файл, който съдържа изгледи за роботи за търсене, което помага за индексиране на страници на портала.
Още видеоклипове в нашия канал - научете интернет маркетинг от SEMANTICA
![]()
Разкрийте, че сте отишли на острова, за да вземете вещите си. Начертавате карта. Там е указан маршрутът: „Отидете до големия пън. Започнете, като спечелите 10 крони на изхода, след което отидете на нивото. Обърни се надясно, ще намериш печерата.”
Tse - vkazivki. Следвайки ги, вие следвате маршрута и намирате съкровища. Приблизително търсещият бот работи, когато започне да индексира сайта или страницата. Трябва да знаете файла robots.txt. Всеки знае кои страници трябва да бъдат индексирани и кои не. Следвайки тези команди, вие заобикаляте портала и добавяте страниците му към индекса.
Защо се нуждаете от robots.txt?
Те започват да посещават сайтове и индексират страници, след като сайтът поиска хостинг и регистрира DNS. Важно е да спрете да работите върху работата си, дори ако нямате технически файлове. Роботите инструктират майтапчиите, че когато обхождат уебсайт, трябва да запазят параметрите, които имат в него.
Наличието на файла robots.txt може да причини проблеми със скоростта на обхождане на сайта и присъствието на сайта в индекса. Неправилното конфигуриране на файла може да доведе до включването на важни части от ресурса от индекса и наличието на ненужни страници.
Всичко това в резултат води до проблеми с изтичането.
Нека да разгледаме отчета, за да видим какви вмъквания се намират в този файл и как влияят върху поведението на робота на вашия уебсайт.
Yak zrobiti robots.txt
Първо проверете кой файл имате.
Въведете адреса на уебсайта в адресната лента на браузъра и името на файла чрез наклонена черта, например https://www.xxxxx.ru/robots.txt
Ако файлът присъства, на екрана ще се появи списък с параметри.

Файлът не съдържа:
- Файлът се създава с помощта на основен текстов редактор като Notepad или Notepad++.
- Трябва да инсталирате името на роботите, extension.txt. Въведете данни в съответствие с приетите стандарти за проектиране.
- Можете да проверите за предимства за допълнителни услуги като Yandex webmaster. Там трябва да изберете елемента „Анализиране на robots.txt“ в секцията „Инструменти“ и да изпълните подканите.
- Когато файлът е готов, качете го в основната директория на сайта.
Правила за настройка
Жокерите имат повече от един робот. Някои роботи индексират само текстово съдържание, докато роботите индексират само графично съдържание. Дори в самите звукови системи дизайнът на роботите за пълзящи роботи може да е различен. При сгъване на файла е необходимо да го закрепите.
Техните оператори могат да пренебрегнат някои от правилата, например GoogleBot не отговаря на информация за тези, които отразяват сайта в главата. Общо взето вонята се хваща и съхранява с пила.
Синтаксис на файла
Параметри на документа: име на робота „User-agent“, директиви: отделно свойство „Allow“ и сигурност „Disallow“.
Има две ключови системи за търсене: Yandex и Google. Очевидно е важно да се възползвате и от двете, когато създавате уебсайт.
Форматът на създаване на записи изглежда така, за да покаже уважение в полетата и празните редове.

Директива потребителски агент
Роботът търси записи, които започват с User-agent, и има записи за името на робота за търсене. Въпреки че това не е посочено, важно е достъпът на робота да не е ограничен.
Директиви Disallow и Allow
Ако трябва да блокирате индексирането от robots.txt, използвайте Disallow. Това ще помогне за ограничаване на достъпа на робота до сайта или различни секции.
Тъй като robots.txt не отговаря на същата директива „Disallow“, която защитава, важно е индексирането на целия сайт да е разрешено. Zazvichiy zaboroni се предписват след кожата робот okremo.
Цялата информация, въведена след иконата #, не се счита за коментар от машината.
Разрешете да блокирате, за да позволите достъп.
Символът на звездата служи като стенограма за тези, за които всички се притесняват: Потребителски агент: *.
Тази опция обаче означава пълна забрана за индексиране за всички.
Ще гледам оградата вместо пеещата папка-каталог
За да блокирате един файл, трябва да въведете този абсолютен път
Карта на сайта, директиви за хост
За Yandex е обичайно да се казва, като огледало, искате да го разпознаете като мръсотия. А Google, както си спомняме, го игнорира. Тъй като няма огледала, просто имайте предвид колко е важно да напишете правилно името на вашия уебсайт с или без www.
Директива за чисти параметри
Те могат да бъдат замразени, ако URL адресът на страниците на уебсайта трябва да замени параметрите, които се променят, но не и да се слее в тях (това може да включва идентификаторите на участниците, референтите).
Например адресът на страниците „ref“ показва дестинацията на трафика, тогава. Моля, обърнете внимание, че на уебсайта на най-продаваните има табели. За всички клиенти страницата ще бъде една и съща.
Работата може да бъде изпратена онлайн, като информацията няма да се повтаря. Това ще намали натоварването на сървъра.
Директива за забавяне на обхождане
Освен това можете да определите с каква честота ботът привлича страници за анализ. Тази команда ще спре, ако сървърът на revantage посочи, че процесът на байпас трябва да се ускори.
Robots.txt заявки
- Файлът не е достъпен в основната директория. Най-великият робот няма да се шегува и няма да лъже.
- Буквите в името може да са малки латински.
Има бележка в името, понякога добавяте буквата S в края и пишете робот. - Не е възможно да се променят знаците на кирилица във файла robots.txt. Ако трябва да въведете домейна на руски език, използвайте специалния формат Punycode, за да посочите формата.
- Това е метод за преобразуване на имена на домейни в последователност от ASCII знаци. За това можете бързо да използвате специални конвертори.
Кодът изглежда така:
site.rf = xn--80aswg.xn--p1ai
Допълнителна информация, която трябва да бъде скрита в robots txt и персонализирана според търсачките Google и Yandex, можете да намерите в допълнителните документи. За различни cms те могат да имат свои собствени характеристики, но те ще бъдат различни.
без коментариФайлът robots.txt е създаден специално за роботите за търсене, така че те да знаят къде да отидат и индексират и къде въвеждането е блокирано. Ако го настроите неправилно, може да не прекарвате много време в търсене или в крайна сметка да не правите нищо в действие.
За да избегнете проблеми с индексирането и индексирането на статии, трябва да знаете как да създавате роботи txt за всички търсачки. Отнема само малко час, но след това ще бъдете спокойни.
Уеб майсторите се опитаха да се справят без него (най-вече, първоначално, поради невежество). От една страна, това е разумно за начинаещи - по този начин определено няма да блокирате необходимата информация от роботите за търсене. От друга страна, този малък файл защитава данните и не позволява на спамботовете да преглеждат информацията в сайта.
Препоръчвам на новите блогъри да използват шаблоните. Например txt шаблон на robots за WordPress. Подобрете и подобрете вашия уебсайт.

Некриптирана стойност:
- Потребителски агент: * - Вие сте свързани директно към всички търсачки, Yandex - само към Yandex.
- Disallow: изброява папки и файлове, които са блокирани за индексиране
- Хост – въведете името на вашия сайт без www.
- Карта на сайта: качете в XML карта на сайта.
Поставете файла в главната директория на сайта с помощта на Filezilla или чрез уебсайта на хостера. Изпратете до главната директория, така че да е достъпна за доставка: your_site.ru/robots.txt
Това е особено вярно за тези, които използват CNC (инструкциите са изписани с думи, но не p=333). Всичко, което трябва да направите, е да отидете в Settings – Postname, да изберете долната опция и да въведете /%postname% в полето.
Актьорите се насърчават да създадат този файл сами възможно най-бързо:
За да започнете, създайте бележник на компютъра си и го наименувайте роботи (не променяйте главните букви). Например, коригирането на вашия размер не е необходимо да надвишава 500 kb.
Потребителски агент- Име на системата за търсене (Yandex, Googlebot, StackRambler). Ако искате да се сърдите на всички наведнъж, сложете звезда *

И след това посочете страници или папки, които не могат да бъдат индексирани в тази работа за помощ Забрани:

Първоначално бяха реорганизирани три директории, включително конкретен файл.
За да позволите всичко да бъде индексирано, трябва да напишете:
Потребителски агент: *
Забрана:
Настройка на robots.txt за Yandex и Google
За YandexЗадължително е да добавите директива за хост, за да няма дублирани страници. Тази дума се разбира само от бот на Yandex, така че напишете думите за ново значение.

За GoogleВече няма жадни. Първо, благородството трябва да бъде жестоко докрай. В секцията User-agent трябва да напишете:
- Googlebot;
- Googlebot-Image – как ограждате индексирането на изображението;
- Googlebot-Mobile – за мобилната версия на сайта.
Как да проверите валидността на файла robots.txt
Можете да работите в раздела „Инструменти за уеб администратори“ на търсачката на Google или на уебсайта Yandex.Webmaster в раздела Проверка на robots.txt.
Ако има грешки, коригирайте ги и ги обърнете отново. За да постигнете добър резултат, тогава не забравяйте да копирате правилния код в robots.txt и да го качите на сайта.
Сега можете да видите как да създадете robots.txt за всички търсачки. Препоръчвам на начинаещите да използват готовия файл, като изпратят името на вашия сайт.
Разбивки