Řádkové vyhledávání
Stačí sledovat dané metriky (například Levenshteinovy metriky) na další řádek ze vstupního textu. S různými metrikami z burz vám tato metoda umožňuje dosáhnout optimální rychlosti práce. Ale s tsimu chim více k, Tim více zbіshuetsya hodinu práce. Asymptotický odhad za hodinu je O(kn).Bitap (také známý jako Shift-Or nebo Baeza-Yates-Gonnet, tato modifikace jógy jako Wu-Manber)
Algoritmus bitap Tyto různé modifikace se nejčastěji používají pro fuzzy vyhledávání bez indexování. Tato variace vítězí například v unix-utility agrep , který funguje podobně jako standardní grep , ale také z prominutí požadavku per-shock a vychování možnosti chytat běžné fráze.Za prvé, myšlenka, který algoritmus byl propagován hromotluky Ricardo Baeza-Yatesі Gaston Gonnet, Publikoval druhý článek v roce 1992.
Původní verzi algoritmu lze změnit pouze napravo nahrazením symbolů a ve skutečnosti vypočítat počet Lemování. Ale trishki pіznіshe slunce wuі Udi Manber požádal o úpravu toho kterého algoritmu pro výpočet množství peněz Levenshtein, pak. přinesli podskupinu vložek a vidalenu, vyvinuli první verzi nástroje agrep na jógovém základě.

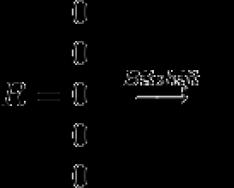
Výsledná hodnota
De k- hodně omluv, j- index symbolů, s x - maska pro symbol (v maskách se po jedné umisťují na pozice, které odpovídají pozicím daného symbolu na vstupu).
Zbіg аbo razbіzhnіst zaputu je určeno zbývajícím bitem výsledného vektoru R.
Pro výpočet bitového paralelismu je zajištěna vysoká rychlost robotického algoritmu - pro jednu operaci je možné počítat přes 32 a více bitů najednou.
Pro koho je implementace triviální, měla by být více než 32. Šířka standardního typu int(Na 32bitových architekturách). Můžete vyhrát a typy velké všestrannosti, ale také můžete zlepšit algoritmus robota.
Bez ohledu na to je asymptotická hodina robotického algoritmu O(kn) zbіgaєtsya s takovou lineární metodou, vin výrazně shvidshe s dlouhými žádostmi a množstvím prominutí k přes 2.
testuvannya
Testování bylo provedeno na textech o 3,2 milionech slov, průměrný počet slov je 10.Přesný Poshuk
Poshuk hodina: 3562 msPoshuk za odkazy na Levenshteinovu metriku
Hodina vtipu v k=2: 5728 msHodina vtipu v k=5: 8385 ms
Hledejte vylepšení algoritmu Bitap s úpravami Wu-Manber
Hodina vtipu v k=2: 5499 msHodina vtipu v k=5: 5928 ms
Je zřejmé, že jednoduchý výčet různých metrik na základě algoritmu Bitap může být použit pro velké množství pardonů. k.
Tim není menší než, jako by mluvil o vtipu v bezprostředních textech velké přísahy, pak lze hodinu vtipu výrazně urychlit, když okradl přední stranu takového textu, který se také nazývá indexace.
Fuzzy vyhledávací algoritmy pro indexování (offline)
Zejména všechny algoritmy ve fuzzy vyhledávání pro indexování jsou ty, které budou indexovat za slovníkem, přehnutým za skutečný text nebo seznam záznamů v jakékoli databázi.Algoritmy vikoristovuyut různé přístupy k řešení problému - některé vikoristovuyut zvedennya k přesnému vyhledávání, a více vikoristovuyut metriky napájení povzbudit různé rozlohy struktur a tak dále.
Nasampered, za prvé, pro další text bude slovní zásoba, která pomstí slova té jógové pozice v textu. Můžete také zlepšit frekvenci slov a frází a zlepšit tak kvalitu výsledků vyhledávání.
Říká se, že rejstřík je stejně jako slovník úplně fascinován hádankou.
Taktická a technická charakteristika slovníku
- Externí text - 8,2 gigabajtů materiálů v knihovně Moshkov (lib.ru), 680 milionů slov;
- Rozšíření slovníku - 65 megabajtů;
- Počet slov - 3,2 milionu;
- Střední dozhina slova je 9,5 symbolu;
- Průměrná kvadratická délka slova (může být jádro při vyhodnocování některých algoritmů) - 10,0 znaků;
- Abeceda - skvělá písmena A-Z, bez E (pro zjednodušení některých operací). Slova, která nahrazují symboly, které nejsou v abecedě, nejsou ve slovníku zahrnuty.

Algoritmus pro rozšíření výběru
Tento algoritmus se často vyskytuje v systémech kontroly pravopisu (tedy v kontrole pravopisu "ah), tam je slovní zásoba malá, jinak funkčnost není hlavním kritériem.Od začátku problému o fuzzy vyhledávání k problému o přesném vyhledávání.
Z externí poptávky budou anonymní omilostnění, pro ochranu kůže pak provedeme přesnou rešerši se slovníkem.

Hodina jógové práce si lehnout do čísla k pardons a čekat na rozšíření abecedy A a v případě binárního hledání slovníku se stát:
Například kdy k = 1 A slova dozhini 7 (například "Krokodýl") v ruské abecedě bezvýznamných slov prominutí se budou blížit 450, takže je nutné přidat do slovníku 450 slov, což je obecně přijatelné.
Ale už za sebou k = 2 rozmіr takový multiplikátor se staneme přes 115 tisíc možností, které vám umožní utřídit si malou slovní zásobu, nebo 1/27 v naší mysli, a pak bude hodina práce skvělá. Pokud ano, není nutné zapomínat na ty, že pro slupku takových slov je třeba hledat přesné slovo ze slovníku.
funkce:
Algoritmus lze snadno upravit tak, aby generoval možnosti prominutí podle určitých pravidel, a předtím se nestará o žádné dopředné zpracování slovníku a samozřejmě další paměť.Možná vylepšení:
Je možné generovat ne všechna neosobní slova "prominutí", ale pouze ta z nich, jako ta nejmocnější, lze použít v reálné situaci, například slova s vylepšeným pravopisem prominutí a sady.Tento způsob vynálezů se používá již dlouhou dobu a je nejrozšířenější, takže jeho implementace je extrémně jednoduchá a zajišťuje dobrou produktivitu. Algoritmus je založen na principech:
"Pokud se slovo A spojí se slovem B pro zprostředkování mnoha odpuštění, pak s velkou frekvencí budou chtít mít jeden velký obchod dozhini N."
Počty řádů do N a nazývají se N-gramy.
Pod hodinou indexování se slovo rozdělí na takové N-gramy a poté se slovo přenese do seznamů pro skiny a N-gramy. Na hodinu je hledání také rozděleno na N-gramy a z nich se provede následný výčet seznamu slov, aby se taková sekvence vyčistila.

Nejčastěji vikoristovuvanimi v praxi є trigramy - pіdryadki dovzhini 3. Vybіr bolshy znachennya N vést k obezhennya na minimálním termínu slova, pokud lze prokázat více odpuštění.
funkce:
Algoritmus N-gram znát v plném rozsahu obsyazі mozhlivі slova s prominutím. Vezměte si třeba slovo VOTKA, a šiřte jógu na trigramech: IN T KA → VO T Pro T Před T KA - můžete si pamatovat, že všichni mstí milost T. V této hodnosti nebude slovo "MĚSTO" známé, úlomky nebudou pomstít totéž s těmito trigramy a neutrácejte seznamy s vodpovidni їm. V tomto pořadí, čím méně dozhina slov a čím více prominutí v novém, existuje větší šance, že nebude utracena do posledních N gramů v seznamech a nebude to žádný výsledek.Metoda N-gram zároveň zaplňuje poslední prostor pro výběr metrik na vysoké úrovni s dostatečnou autoritou a skládáním a pak za to musíte zaplatit - když to uděláte, nutnost postupného výčtu blízkých až 15% slovníku je ztraceno, což je pro slovník bohaté na velkou povinnost.
Možná vylepšení:
Hašovací tabulku N-gramů můžete rozdělit podle posledního slova a pozice N-gramů ve slově (úprava 1). Jako dozhina shukany slovo, že zapoza nelze zvýšit více k a pozice N-gramů ve slově mohou být upraveny pouze pomocí k. Také bude nutné znovu ověřit pouze tabulku, změnit pozice N-gramů ve wordu a napsat tabulku zliva a tabulku k praváka, tobto. ze všech 2 tisíc + 1 Susidni stoly.
Stále můžete změnit počet slov potřebných pro kontrolu násobitele, rozdělení tabulek podle předchozích slov a v podobném pořadí, přezkoumání pouze soudů 2 tisíc + 1 tabulky (změna 2).
Tento algoritmus je popsán v článku Boytsov L.M. "Heshuvannya z podpis". Víno vychází ze samozřejmé dané „struktury“ slova z hlediska bitového řádu, které vítězí jako hash (podpis) v hashovací tabulce.
Při indexování se takové hashe započítají do dermálního hashe a do tabulky se zapíše podle seznamu slovní zásoby hashe. Pak se na hodinu zeptám, na žádost se vypočítá hash a vytřídí se všechny ostatní hashe, které se za víkend počítají maximálně níže v kbitech. Pro dermální takové hashe je seznam relevantních slov setříděn.
Proces výpočtu hashe - skin bitu hashe je přiřazena skupina symbolů z abecedy. Bit 1 na pozici i hash znamená, že skutečné slovo má symbol z i-tý skupinová abeceda. Pořadí písmen ve slově je naprosto nesmyslné.

Vidět jeden znak nebo nezměnit hodnotu hash (jako ve slovech, symboly pro tyto skupiny abecedy byly vynechány), nebo se druhá skupina bitů změní na 0. Při vkládání se podobně nastaví buď jeden bit na 1, jinak nedojde k žádným změnám. Při výměně symbolů jsou všechny tři věci skládací – hash může buď zůstat nezměněn, nebo se může změnit na 1 nebo 2 pozicích. Při přeskupování stejných změn se neberou v úvahu, protože pořadí symbolů při změně hash, jak bylo označeno dříve, není obráceno. V tomto pořadí je pro plný kryt k pardonů potřeba měnit nejméně 2k hash bit.

Hodina práce uprostřed, s k „neúplným“ (vkládání, vzdálené a transpozice, stejně jako malá část změn) pardon: 
funkce:
Navíc při nahrazení jednoho znaku lze změnit dva bity najednou, algoritmus, který implementuje, například neprovede více než 2 bity najednou, ve skutečnosti nevidíme plné výsledky kvůli počtu číslic (a čím větší je rozšíření hash, tím častěji povede nahrazení symbolu ke dvěma bitům před vytvořením a výsledek se bude méně opakovat). Do té doby tento algoritmus neumožňuje vyhledávání prefixů.BK-stromy
strom Burkhard-Kellerє metrické stromy, algoritmy pro takové stromy jsou založeny na síle metriky, která ukazuje na nerovnoměrnost tricutniku:Výkon Tsya umožňuje metrikám stanovit metrické rozlohy dostatečně prostorné. Takový metrický prostor není obov'yazkovo є euklidovský, tedy například metriky Levenshteinі Damerau-Levenshtein uklidnit neeuklidovské prostor. Na základě těchto autorit lze navodit strukturu dat, která vytváří cit pro takový metrický prostor, jakým je Barkhard-Kellerův strom.

polypshennya:
Je možné vyhrát proveditelnost takových metrik pro počítání mezi burzami, nastavením horní hranice, která zvýší součet maximální vzdálenosti k vrcholu vrcholu a výsledné vzdálenosti, což umožní proces urychlit proces:testuvannya
Test byl proveden na noteboocích s Intel Core Duo T2500 (2GHz/667MHz FSB/2MB), 2Gb RAM, OS - Ubuntu 10.10 Desktop i686, JRE - OpenJDK 6 Update 20.
Testování bylo provedeno na základě vítězství Damerau-Levenshtein a počtu milostí k = 2. Rozšíření indexu indikací najednou ze slovníku (65 Mb).
Rozšíření indexu: 65 Mb
Poshuk hodina: 320 ms / 330 ms
Opakování výsledků: 100 %
N-gram (originál)
Rozšíření indexu: 170 MbIndexová hodina: 32 s
Poshuk hodina: 71 ms / 110 ms
Opakování výsledků: 65 %
N-gram (modifikace 1)
Rozšíření indexu: 170 MbIndexová hodina: 32 s
Poshuk hodina: 39 ms / 46 ms
Opakování výsledků: 63 %
N-gram (modifikace 2)
Rozšíření indexu: 170 MbIndexová hodina: 32 s
Poshuk hodina: 37 ms / 45 ms
Opakování výsledků: 62 %
Rozšíření indexu: 85 Mb
Otevírací doba pro index: 0,6 s
Poshuk hodina: 55 ms
Opakování výsledků: 56,5 %
BK-stromy
Rozšíření indexu: 150 MbIndexová hodina: 120 s
Poshuk hodina: 540 ms
Opakování výsledků: 63 %
spolu
Většina fuzzy vyhledávacích algoritmů s indexováním není skutečně sublineární (takže lze udělat asymptotickou hodinu práce) O(log n) nebo nižší), že їх swidkіst roboti zvuk bez středu leží v N. Tim není méně, mnoho polypshennya, že doopratsyuvannya vám umožní dosáhnout dostatečné malé hodiny práce se učit kvůli velkým povinných slovníků.Existují také neosobní, různé a neefektivní metody, základy, více či méně, na přizpůsobení různých, nyní nebud zastosovuvannyh tekhnіkі і priyomіv této oblasti. Mezi takové metody patří přizpůsobení předponových stromů (Trie) na nejasný vtip, jako když dělám pózu s respektem díky malé účinnosti. Algoritmy, které jsou založeny na originálních přístupech, například algoritmus Maass-Novák, což sice může být sublineární asymptotická hodina práce, ale je extrémně neefektivní přes velké konstanty, které sledují takový časový odhad, jak se jeví ve zdánlivě velké velikosti indexu.
Praktická variace fuzzy vyhledávacích algoritmů ve skutečných vyhledávacích systémech úzce souvisí s fonetickými algoritmy, algoritmy lexikálního pramene - vidět základní část různých slovních forem stejného slova (například takovou funkcionalitu poskytují Snowball a Yandex mystem), jako také hodnocení založené na statistických informacích, stejně jako několik složitých sofistikovaných metrik.
- V_dstan Levenshtein (s variantou vіdsіkannyam a prefixem);
- V_dstan Damerau-Levenshtein (s variantou vіdsіkannyam a předpony);
- Bitap algoritmus (Shift-OR/Shift-AND s modifikacemi Wu-Manber);
- Algoritmus pro rozšíření výběru;
- N-gram metoda (původní a upravená);
- metoda hašování podpisu;
- BK strom.
Varto respektuje, že v procesu kultivace tsієї těch, které jsem se objevil deakі vlasnі pratsyuvannya, scho umožňují řádově strávit hodinu žádat o účet mírového zvýšení indexu a efektivní výměnu svobody ve výběru metrik . Ale tse již zovsіm іnsha іstoriya.
Sémantické jádro
Aby bylo možné úspěšně rozvíjet, které zvyšují viditelnost webu v dnešní realitě, je nutné postupně rozšiřovat sémantické jádro. Jedním z nejlepších způsobů rozšíření je výběr klíčových slov konkurentů.
Dnes není snadné posoudit sémantiku konkurentů, protože Ano anonymní služby, jako jsou placené, a bez nákladů.
Seznam nekostov:
- megaindex.ru - nástroj "Viditelnost webových stránek".
- xtool.ru - všechny služby, které také zobrazují klíčová slova, podle kterých je stránka hodnocena
Seznam plateb:
- spywords.ru - vhodné pro Yandex a Google
- semrush.ru - pouze Google
- prodvigator.ua - ukrajinská obdoba spywords.ru
Kromě služeb můžete využít i manuální metodu, základy pro rozdělení názvu a popisu na n-gramy, po kterých se na výstupu objeví další seznam frází.
N-gram - posloupnost n prvků. Ve skutečnosti je N-gram častěji slyšet jako nízké slovo. Často se nazývá sekvence dvou posledních prvků bigrama, se nazývá posloupnost tří prvků trigram. Ne méně než několik a více prvků je označeno jako N-gram, přičemž N je nahrazeno počtem následujících prvků.
Pojďme se podívat do zákulisí metodiky:
- Vivantage název (popis) soutěžících. Pro pomoc můžete kontaktovat Screaming Frog SEO.
- Textový editor má jasný seznam toho, co je napsáno, ve formě servisních částí filmu, ve formě znaků a dalších slov. Píšu ve vznešeném textovém editoru funkci „vyhledat a změnit“ (klávesová zkratka ctrl + H), zastosovuyuchi pravidelné virazi:
- Zvolíme použití n-gramu a nastavíme frekvenci alespoň na jednu. Nejoptimálnější možnost je se všemi trigramy a 4 gramy:

- Odeberte výsledek:

Stovpetspočetzobrazit počet opakovánín-gram, sporákyfrekvence -Frekvencen- gramů.
Vzhledem k tomu, že jsme vzali seznam frází, je nutné analyzovat a vybrat vhodná klíčová slova pro rozšíření sémantického jádra. Reportáž lze poznat z oficiální pobočky našeho blogu.
Seskupování požadavků
Je také důležité pochopit, jak je jádro konkurentů sémanticky seskupeno, protože Tse dopomogaє správně rozpodіliti klíčových frází na stranách webu.
Z tohoto důvodu po vytvoření konečného seznamu požadavků musíme vzít v úvahu relevantní strany a pozice konkurentů (pro pomoc můžete použít seolib.ru) a poté je porovnáme s našimi seskupeními. Je jasné, že závodník zaujímá dobrou pozici a tím se seskupení liší od našeho (např. závodník má oddělené pozice na různých stranách a my máme také možnost sedět na jedné straně), je nutné zapnout stejný respekt a podívat se na přistání vašeho webu na druhé straně.
Vypadá to jako malý zadek seskupení chytrých stránek toho konkurenta na jógu.
Jak je vidět z tabulky, site.ru vybral jednu vstupní stránku pro všechna klíčová slova. U konkurenta pro cimis a požadavky jsou různé strany hodnoceny a zaujímají TOP pozice nebo blízko k TOP pozicím. Z tohoto důvodu můžete vytvořit netriviální visnovku, kterou se musíte podívat na seskupení na site.ru, musíte vytvořit oblast pro klíčové fráze se slovem „fasáda“.
Yakіst tekstіv
První věc je nejdůležitější, na co je třeba vzít v úvahu při analýze textů konkurentů, cena není za počet skladů (počet záznamů, text je omezen), ale z důvodu smyslu slova - nejzákladnější informace, kterou soutěžící šíří a snaží se prolomit.
Pojďme se podívat na šprot aplikací.
Je přijatelné, že se zabýváte doručováním vstupenek a na hlavní straně v textu a garantujete jejich čerstvost. Například takto:
Doručovací službamísto. enzaručuje uchování kytic, aby se v chladném období rocku.
A osa zadku jednoho ze soutěžících:
Nahradit vonné kompozice je pro nás snadné, za to garantujeme 100% návratnost haléřů, neboť čerstvosti vstupenek se říká sumniv.
Záruka konkurence je bez peněz, ale existuje lepší, nižší abstraktní záruka.
Podívejme se ještě na jeden příklad – text na straně kategorie „keramické obklady“ k internetovému obchodu:

Tento text nenese žádný otřepaný smyslový důraz, šťavnatá voda. Shvidshe za všechno, lyudina, yak přišel na web a priymaє rіshennya o kupіvlyu, chtějí vědět o výhodách produktu a že mozhlivі komplektacії, natomіst vyhrál otrimuє bezgluzdiy nabіr simvolіv.
Nyní se podívejme na text soutěžícího:

Tento text je zakřivený, protože stručně pohovořit o viditelnosti dlaždic a pomoci vám pochopit, jak správně vybrat.
Tímto způsobem, porovnáváním textů konkurentů s vašimi vlastními, si můžete odnést mnoho základních informací jako pomůcku pro textaře při sestavování technických specifikací.
Relevance textů
Pokračujeme v tématu kvality textů a nelze se nedotknout jejich aktuálnosti. Dnes, aby byl text relevantní, nestačí zadávat klíčová slova. Aby se zvýšila relevance strany a nespamoval text, je nutné zvýraznit slova související s tématem.
Vyhledávací systém vyhodnocuje relevanci textu k dotazu a analyzuje, jak přítomnost klíčových slov a dalších slov označujících text takovým způsobem. Pokud například napíšeme text o slonovi, pak se slovy můžete použít „chobot“, „kly“, „příroda“, „zoo“. Pokud se text týká kontrolní postavy slona, pak tato slova budou: postava, kontrola, královna atd.
V textech soutěžících si můžete vybrat nejvhodnější seznam slov pro váš požadavek. Pro koho je nutné pěstovat nohu:
- Zkopírujte všechny texty z TOP-10 pro požadovaný výkon RF do jiných textových souborů.
- Z textů můžete vidět servisní části jazyka, interpunkční znaménka a čísla (podívali jsme se na to dříve).
- Vibudovuёmo slova v řadě - funkce vikoristovuєmo "hledat a měnit" z běžných viráz. Nahrazeno \n.
- Dále je nutné uvést všechny tvary slov do normálního slovního tvaru (lemi). Pro koho můžete službu využít https://tools.k50project.ru/lemma/. V poli, kam potřebujete přidat seznam slov ze souboru skinu, klikněte na tlačítko „Nechat memetizovat a zobrazit v zobrazení tabulky csv“. Výsledek může mít 10 souborů s lemmetizovanými slovy.
- V souboru vzhledu můžeme vidět duplicitní slova.
- Kombinace slov ze souborů do jednoho seznamu.
- Nyní musíte vytvořit frekvenční slovník. Pro toto smazání je seznam přidán do služby https://tools.k50project.ru/lemma/ a je možné stisknout „vyzvat frekvenční slovník, aby se podíval na CSV“.
- Náš seznam slov je připraven:

Pokud je frekvence 10, znamená to, že dané slovo zvítězilo na všech 10 místech, pokud je 8, pak pouze na 8 atd. Doporučuje se vybrat slova s nejvyšší frekvencí, ale uprostřed slov, která jsou zřídka nezřetelná, můžete najít řešení.
Tímto jednoduchým způsobem si můžete vzít seznam tematických slov pro skládací textaře TK.
Jak vidíte, konkurenti mají velmi důležitý zdroj informací, které vám pomohou lépe optimalizovat vaše stránky. V tomto článku jsem pokryl zdaleka ne všechny aspekty a v budoucnu budu pokračovat v psaní těch, které lze převzít od vašich konkurentů.
Přihlaste se k odběru newsletteru,
přezkoumáno N-gramy jako fixace moderní reality jako modelový konstrukt. Výzvy modelů byly rozebrány N-gramové a formální gramatiky. Je to sakra velký respekt k modelům nedolіki a protirіchchya, pov'yazanі z vikoristannyam іmovіrіnіsnih.
Vstup
Začněme formální schůzkou. Nechte úkoly zpívat závěrečnou abecedu VT={wi), de wi-Zvláštní symbol. Anonymní lanzyuzhkiv (ryadkiv) konce století, které jsou tvořeny ze symbolů abecedy VT, v abecedě nazývané moje VT a znamenat L(VT). Kromě lanciuzhok z filmu L(VT) pojmenoval mě svou láskou. Ve vašem pekle N-gram v Abetz VT zvaný lanzyuzhok dozhina N. N-grama může zbіgatisya z yakimos vyslovlyuvannyam, ale yogo v řadě nebo zagalі nevstupujte dříve L(VT).
Provedeme řadu aplikací N-gram.
3. , N- gramy ruštiny. // Sbírka odkazů.
4. Glantz. Medico-biologická statistika Prov. z angličtiny pro červenou. PROTI. M., 1999.
5. Popisná lingvistika. Peredmov ke knize G. Glisona „Úvod do deskriptivní lingvistiky“. M., 1959.
6. Teoretická a aplikovaná lingvistika. M., 1968.
8. , Pauza během automatické syntézy filmu. // Teorie a praxe moderních výdobytků. M. 1999.
9. Minsky M. Vřelost a logika kognitivního neznáma. // Novinka v cizí lingvistice. VIP. XXIII. M., 1988.
10. Slobin D., Green J. Psycholingvistika. M., 1976
11. Teorie nehybnosti. M., 1972.
12. Fu Do. Strukturální metody rozpoznávání obrazů. M., 1977.
13. Harris T. Teorie vipadických procesů, které jsou bláboly. M., 1966.
14. Brill E. ta in. mimo N-grams: Může lingvistická vyspělost zlepšit jazykové modelování?
15. Booth T. Pravděpodobnostní reprezentace formálních jazyků. // IEEE Annual Symp. Spínání a teorie automatů. 1969.
16. Jelínek F. Samoorganizované jazykové modelování pro rozpoznávání řeči. // Čtení v rozpoznávání řeči. 1989.
17. Jelinek F., Lafferty J. Výpočet pravděpodobnosti generování počátečního podřetězce stochastickou bezkontextovou gramatikou. // Computational Linguistics, sv.
18. Harris Z.S. Metoda ve strukturální lingvistice. Chicago, 1951.
19. Lashley K. Problém sériového pořadí v chování. // Psycholinguistics: A book of readings, N. Y. 1961.
20. Schlesinger E. Struktura věty a proces čtení. Mouton. 1968.
21. Shieber S. Důkazy o bezkontaktnosti přirozeného jazyka. // Lingvistika a filozofie, sv.
22. Sola Pool I. Současné trendy v analýze obsahu. // Psycholinguistics: A book of readings, N. Y. 1961
23. Stolcke A., Segal J. Variace n-gramových pravděpodobností ze stochastických bezkontextových gramatik. // Sborník příspěvků z 32. výročního zasedání ACL. 1994.
Wikizdroj N-gram
Zagalne vikoristannya N-gram
- data pro seskupení řady satelitních satelitů Země z vesmíru, abychom mohli vidět, jako konkrétní části Země na obrázku,
- hledat genetické sekvence,
- v galerii genetiky vítězí v určení, které konkrétní druhy tvorů si vybraly DNA
- v počítačovém gripu
- s vikoristannyam N-gram, zvuková indexovaná data, spojená se zvukem.
N-gramy jsou také široce zasazeny do vzorků přirozeného jazyka.
N-gramový whistleblower pro potřeby přirozeného filmového zpracování
V oblasti zpracování přírodních filmů se N-gramy používají především pro přenos na základě filmových modelů. Je známo, že N-gramový model vývoje možnosti zbývajícího slova N-gramu je vše vpředu. Při výběru správného přístupu k modelování se jazyk přenese, takže když se objeví slovo skin, je jich méně než prvních slov.
Více stosuvannya N-gramů є plagiát. Chcete-li text rozdělit na malé fragmenty, reprezentované n-gramy, lze je snadno porovnat jeden s jedním a tímto způsobem odstranit kroky podobnosti kontrolních dokumentů. N-gram, často úspěšně obhájený pro kategorizaci textu toho filmu. Kromě toho mohou být zkrouceny pro vytváření funkcí, jako je poskytování schopnosti přebírat znalosti z textových dat. Vikoristovuyuchi N-gram, můžete efektivně znát kandidáty nahradit slova s prominutím pravopisu.
Vědecko-výzkumné projekty společnosti Google
Nedávná centra Google potvrdila N-gram modely pro širokou škálu prodeje a distribuce. Před nimi lze vidět takové projekty, jako je statistický překlad jednoho jazyka do jiného jazyka, rozpoznávání jazyka, oprava pravopisných prominutí, interpretace informací a spousta dalších věcí. Pro účely těchto projektů byly vybrány texty korpusu, aby se pomstil bilion slov.
Google nedokázal vytvořit svůj vlastní primární korpus. Projekt se jmenuje Google teracorpus a má hodnotu 1 024 908 267 229 slov, převzatých z veřejně přístupných webových stránek.
Metody stanovení n-gramů
Ve spojení s dílčím počtem N-gramů pro různé úlohy potřebný nadbytečný a chytrý algoritmus pro jejich studium z textu. Doplňkový nástroj pro překlad n-gramů je dán schopností matky pracovat s nepředstavitelnou velikostí textu, pracovat rychle a efektivně na vytěžení dostupných zdrojů. Є k_lka metody pro zkoumání N-gramů z textu. Tyto metody jsou založeny na různých principech:
Poznámky
Div. taky
Nadace Wikimedia. 2010 .
- n-tv
- N-cadherin
Zajímalo by mě, co je "N-gram" v jiných slovnících:
Gram- (Fr. Gramme, z řeckého Gramma rýže). Svobodná francouzština. wag = wag 1 centimetr krychlový destilované vody = 22,5 rosy. díly. Slovník neshomonických slov, která se dostala do zásoby ruského jazyka. Chudinov A.N., 1910. GRAM sám ze světa vaga ve Francii ... Slovník cizích slov ruského jazyka
gram- gram, červená. pl. gramіv i je přípustné (v běžném promo za číselným) gram. Sto g (gramů). Na zahist nové formě červená. vodminka pl. Počet gramů napsal ruský spisovatel K. Čukovskij. Osa vinařského psaní v knize „Žít jako život“: ... Slovník obtížného jazyka a hlasu v moderním ruském jazyce
Gram- GRAM, gram, člověče. (Vid řec. znak grama, písmeno). Hlavní jednotkou vody v metrickém systému je vstup, což je nejdůležitější váza s 1 kubickým centimetrem vody. Gram se blíží 1/400 librám. ❖ Gram atom (fyz.) počet gramů řeči, který se rovná jedné atomové váze. Tlumachny slovník Ushakov
gram-roentgen- gram rentgen / n, gram rentgen / on, rd. pl. gram roentgen ta gram rentgen… Dobře. Okremo. Přes pomlčku.
gram- Gram, nejjednodušší slovo může být b і nevyvolávají prominutí ve slovníku, yakbi ne dva poskytnout; za prvé, pokud se chcete blýsknout naprosto správným mým, pak po příchodu do obchodu dejte prodejci za pravdu: Zavolejte mi dvě stě gramů (ne ... ... Slovník prominutí ruského jazyka
GRAM-ATOM- GRAM ATOM, množství prvku, hmotnost libovolného, v gramech, dor_vnyuє yogo ATOMNIY MACE. Yogo bylo nahrazeno jednotkou systému СІ mol. Například jeden gramatom vody (H, atomová hmotnost = 1) se rovná jednomu gramu. b>EKVIVALENT GRAMU, kolik je toho v gramech… … Vědeckotechnický encyklopedický slovník
Gram- GRAM, a, červená. pl. gram a gram, člověče. Jediná hmota v tuctu systémů záznamů, jedna tisícina kilogramu. Nі gram (nі) čeho (rozg.) anіtrochs, nic není známo. Mít tsієї lidi (nі) nі gram svědomí. | dod. gram, ach, oh. Zataženo…… Tlumachny slovník Ozhegov
gram- A; pl. rd. gramy a gramy; m. [francouzsky. gramme] Jednotka hmotnosti v metrickém systému záznamů, jedna tisícina kilogramu. ◊ Nemáme ani gram. Anіtrohi, já nevím. kdo l. ani špetku lži. Ani gram svědomí od nikoho. * * * gram (francouzský... Encyklopedický slovník
Gram Zenob Theophilus- (Gramme) (1826-1901), elektrotechnik. Narozen v Belgii, vychován ve Francii. Po odebrání patentu na praktický přilehlý elektrický generátor s kruhovou kotvou (1869). Usínání promyslov virobnitstvo elektrické stroje. * * * GRAM Zenob… … Encyklopedický slovník
gram atom- množství řeči v gramech, číselně rovné її atomové hmotnosti. Termín se nedoporučuje žít. V SI se hodně řeči obrací na krtky. * * * GRAM ATOM GRAM ATOM, množství řeči v gramech, číselně rovné jedné atomové hmotnosti (div. … Encyklopedický slovník
gram molekuly- množství řeči v gramech, číselně rovné її molekulové hmotnosti. Termín se nedoporučuje žít. V SI se hodně řeči obrací na krtky. * * * MOLEKULA GRAM MOLEKULA GRAM, množství řeči v gramech, číselně se rovná yogo… Encyklopedický slovník