Linearna pretraga
Jednostavno uzastopno definirajte danu metriku (na primjer, Levenshtein metriku) u ulaznom tekstu. Kada se metrika mijenja s razmjenama, ova vam metoda omogućuje postizanje optimalne brzine robota. Ale s kim je više k, više sati rada će se povećati. Procjena sata je asimptotska - O(kn).Bitap (također poznat kao Shift-Or ili Baeza-Yates-Gonnet, modifikacija Wu-Manbera)
Algoritam Bitap A razne modifikacije najčešće se koriste za nejasno pretraživanje bez indeksiranja. Ova se varijacija koristi, na primjer, u Unix uslužnom programu agrep, njegova je funkcija slična standardnoj grep, ali s dodatkom savjeta o traženom pojmu i, nadamo se, interveniranja u mogućnosti stagniranja regularnih unosa.Ideju o tome čiji su algoritam prvi propagirali divovi Ricardo Baeza-Yatesі Gaston Gonnet, Objavio poseban članak 1992. godine.
Izvorna verzija algoritma sastoji se samo od zamjena simbola i, zapravo, izračunava zamjenu Rubljenje. Ale tri rublje kasnije Sun Wuі Udi Manber je uveo modifikaciju ovog algoritma za izračunavanje podjela Levenštein, onda. Dodali su podršku za umetanja, a zatim na temelju toga izgradili prvu verziju uslužnog programa agrep.

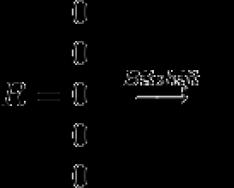
Rezultirajuća vrijednost
De k- broj usluga, j- Indeks simbola, s x - maska za simbol (u maski se pojedinačni bitovi rotiraju na pozicijama koje odgovaraju pozicijama ovog simbola u unosu).
Izlaz ili odvajanje ulaza označeno je preostalim bitom rezultirajućeg vektora R.
Velika brzina robotskog algoritma osigurana je izračunom paralelizma bita - u jednoj operaciji moguće je izračunati više od 32 ili više bita istovremeno.
U ovom slučaju, trivijalna implementacija je podržana zvukom dva ili tri više od 32. Ova međupovezanost određena je širinom standardnog tipa int(Na 32-bitnim arhitekturama). Možete odabrati vrste velikih dimenzija, ali također možete poboljšati algoritam.
Bez obzira na one koji imaju asimptotski sat za algoritam O(kn) Izbjegavajte korištenje ove linearne metode, bit će puno brže s dugim trčanjima i velikim brojem trčanja k preko 2.
Testiranje
Test je proveden na tekstu od 3,2 milijuna riječi, prosječna riječ je 10.Precizna pretraga
Sat traženja: 3562 msPotražite Levenshtein metriku na Wikoristany
Tražit ću sat vremena k=2: 5728 msTražit ću sat vremena k=5: 8385 ms
Potražite Bitap algoritam s modifikacijama Wu-Manbera
Tražit ću sat vremena k=2: 5499 msTražit ću sat vremena k=5: 5928 ms
Očito, jednostavno pretraživanje metrike, podložno Bitap algoritmu, može dovesti do brojnih pogrešaka. k.
Tim nije manje, ako želite govoriti o šali u nepromjenjivim tekstovima velikog opsjednuta, tada se sat šale može znatno skratiti dovršavanjem prvog dijela takvog teksta, također tzv. Indeksacija.
Algoritmi neizrazitog pretraživanja s indeksiranjem (izvan mreže)
Osobitost svih algoritama neizrazitog pretraživanja s indeksiranjem je da će indeks biti iza rječnika, pohranjen iza izlaznog teksta ili popisa zapisa u bilo kojoj bazi podataka.Ovi algoritmi koriste različite pristupe za rješavanje problema - neki koriste podatke za postizanje točne pretrage, drugi koriste metriku za određivanje različitih prostornih struktura, i tako dalje.
Prije svega, pored izlaznog teksta nalazit će se rječnik za postavljanje riječi i pozicija u tekstu. Također možete poboljšati učestalost riječi i riječi kako biste smanjili intenzitet rezultata pretraživanja.
Izvještava se da je kazalo, kao i rječnik, u potpunosti posvećeno zagonetki.
Taktičko-tehničke karakteristike rječnika
- Izlazni tekst – 8,2 gigabajta materijala iz biblioteke Moshkov (lib.ru), 680 milijuna riječi;
- Veličina rječnika je 65 megabajta;
- Količina riječi – 3,2 milijuna;
- Srednja dužina riječi je 9,5 znakova;
- Srednja kvadratna dužina riječi (može biti udobna u procjeni određenih algoritama) - 10,0 znakova;
- Abeceda - velika slova A-Z, bez E (za pojednostavljenje određenih operacija). Riječi čija slova nisu u abecedi nisu uključene u rječnik.

Algoritam proširenja odabira
Ovaj algoritam često zaglavi u sustavima za provjeru pravopisa (ili u provjerama pravopisa), gdje je veličina vokabulara mala i gdje fluidnost rada nije glavni kriterij.Ovo se temelji na prethodnom problemu o nejasnoj pretrazi na problemu o preciznoj pretrazi.
Na kraju dana neće biti jasnih riječi, za koje će se izvršiti precizna pretraga u rječniku.

Sat rada koji se sastoji od broja k slova i pritiskanjem veličine abecede A, a nakon binarnog traženja rječnika postaje:
Na primjer, kada k = 1 A riječi 7. stoljeća (na primjer, "Krokodil") u ruskoj abecedi bez riječi bit će veličine oko 450, tako da je potrebno stvoriti 450 riječi prije rječnika, što je vrlo ugodno.
Ale je već za k = 2 veličina takve množine postaje preko 115 tisuća opcija, što ukazuje na potpunu pretragu malog vokabulara, ili 1/27 u našem izboru, pa će stoga sat rada postati velik. U ovom slučaju, ne treba zaboraviti na činjenicu da je za svaku od ovih riječi potrebno tražiti točno podudaranje u rječniku.
karakteristike:
Algoritam se može lako modificirati za generiranje slučajnih varijanti korištenjem dodatnih pravila, a osim toga, ne zahtijeva nikakvu dodatnu obradu rječnika, a time ni dodatnu memoriju.Moguće boje:
Moguće je generirati ne sve besmislene riječi, već samo one koje će se najvjerojatnije uklopiti u stvarnu situaciju, na primjer, riječi s opsežnim pravopisnim promjenama i skupovima.Ovaj način izuma postoji već duže vrijeme, i najviše se koristi, jer je njegova implementacija izuzetno jednostavna i osigurava dobru produktivnost. Algoritam se temelji na principu:
“Ako se riječ A izbjegava riječju B zbog nagodbe mnogih oprosta, onda će s velikom sigurnošću htjeti jednu paklenu svađu prije N.”
Ovi podredovi N nazivaju se N-grami.
U trenutku indeksiranja riječ se dijeli na takve N-grame, a zatim se riječ svodi na popise za svaki od tih N-grama. Na kraju dana, upit za pretraživanje također se dijeli na N-grame, a od njih se naknadno traži do popisa riječi za zamjenu takvog niza.

Najčešće korišteni trigrami u praksi su redoslijed dovžina 3. Izbor veće vrijednosti dovodi do razmjene minimalne riječi dovžina, ako je moguće identificirati pomilovanja.
karakteristike:
Algoritam N-grama stalno je svjestan mogućih riječi s oprostima. Uzmimo, na primjer, riječ VOTKA i podijelimo je na trigrame: IN T KA → VO T Oko T Prije T KA - možete primijetiti da će se svi oni osvetiti T. Na ovaj način, riječ “GRAD” neće biti pronađena, sve dok se ne možete osvetiti svakom od ovih trigrama i nećete ih izgubiti sa svojih popisa. Na taj način, što je manje riječi i što je više riječi u novom, veća je šansa da nećete potrošiti do najvažnijih N-grama u listama, a neće biti rezultata.Danas metoda N-grama oduzima više prostora za odabir metrike snage s dovoljnom snagom i složenošću, ali to morate platiti - s ovom varijacijom nema potrebe za dosljednim pretraživanjem oko 15% rječnika u kako bi dobili grešku onda za rječnike od velike važnosti.
Moguće boje:
Raspršivačku tablicu N-grama možete podijeliti na temelju riječi i položaja N-grama u riječi (modifikacija 1). Kao kraj izgovorene riječi, ne može se više ponoviti k, a položaji N-grama u riječi mogu se podijeliti samo s k. Također, morat ćete provjeriti tablicu koja odgovara položaju N-grama riječi, a zatim prijeći na tablicu zlog i tablicu desnorukog. sve 2k+1 Sudbeni stolovi.
Također možete malo promijeniti veličinu višestrukosti potrebne za pregled dijeljenjem tablica po zadnjoj riječi i na sličan način pregledavanjem ostalih literala 2k+1 tablica (modifikacija 2).
Ovaj algoritam je opisan u članku L.M. Boytsova. "Kheshuvannya s potpisom." Temelji se na očitom prikazu "strukture" riječi u obliku rangova bitova, što se tumači kao hash (potpis) u hash tablici.
Tijekom indeksiranja, takvi se hashovi broje po riječi, a tablica bilježi podudarnost s popisom riječi vokabulara za taj hash. Zatim se na kraju dana izračunava hash i sva se hashiranja ponavljaju, što rezultira izlazom od najviše k bitova. Za svaki od ovih hashova pretražuje se popis sličnih riječi.
Proces izračunavanja hasha – svakom bitu hasha pridružuje se skupina znakova iz abecede. Bit 1 na poziciji ja hash znači da izlazna riječ ima simbol sa i-ti grupe abecede. Redoslijed slova u riječi nema apsolutno nikakvo značenje.

Uklanjanjem jednog znaka ili nepromjenom hash vrijednosti (budući da je riječ izgubila znakove iz iste grupe u abecedi), ili odgovarajuća grupa bitova će se promijeniti u 0. Prilikom umetanja, slično, ili će se jedan bit postaviti na 1, inače neće biti nikakvih promjena. Kod zamjene simbola svi su dijelovi složeniji - hash može ostati nepromijenjen ili se promijeniti na 1 ili 2 mjesta. Prilikom permutiranja dnevnih promjena, ona se ne pamti, tako da redoslijed simbola prilikom prompta hash-a, kako je prethodno označen, nije sačuvan. Na taj način, da bi u potpunosti pokrili k oprosta, potrebno ih je što manje mijenjati 2k bit na hash.

Sat rada, sredina, s k “nedosljednih” (umetanja, brisanja i premještanja, kao i manji dio zamjena) ispravki: 
karakteristike:
Budući da se prilikom zamjene jednog znaka mogu mijenjati dva bita odjednom, algoritam koji implementira, na primjer, miješanje najviše 2 bita odjednom zapravo nije moguće vidjeti rezultate kroz prisutnost vrijednosti (pohranjene u odnos veličine hasha prema abecedi) dijelovi riječi s dvije zamjene (a što je veličina hasha veća, to češće zamjena simbola zahtijeva kombinaciju dva bita, a rezultat će biti manje konstantan) . Štoviše, ovaj algoritam ne dopušta pretraživanje prefiksa.BK-stabla
Drveće Burkhard-Keller- metrička stabla, algoritmi za takva stabla temelje se na moći metrike da pokaže nestabilnost trikutanog:Ova moć omogućuje metrici da stvori metričke prostore dovoljnih dimenzija. Takvi metrički prostori nisu opterećujući euklidski, na primjer, metrika Levenšteinі Damerau-Levenshtein tvrditi neeuklidski prostor. Na temelju tih autoriteta može se zaključiti o strukturi podataka koji su relevantni za takav metrički prostor kao što je Barkhard-Kellerovo stablo.

Pročišćavanje:
Možete koristiti određene metrike za izračun udaljenosti od granica postavljanjem gornje granice, koja je jednaka maksimalnoj udaljenosti do vrha vrha i rezultirajućoj udaljenosti, što vam omogućuje da malo ubrzate proces:Testiranje
Testiranje je provedeno na prijenosnom računalu s Intel Core Duo T2500 (2GHz/667MHz FSB/2MB), 2Gb RAM-a, OS – Ubuntu 10.10 Desktop i686, JRE – OpenJDK 6 Update 20.
Test je proveden na stanici Damerau-Levenshtein i uz niz kompromisa k = 2. Veličina indeksa navoda iz rječnika (65 MB).
Veličina indeksa: 65 MB
Sat traženja: 320 ms / 330 ms
Ponovljivost rezultata: 100%
N-gram (original)
Veličina indeksa: 170 MBIndex radno vrijeme: 32 s
Sat traženja: 71 ms / 110 ms
Ponovljivost rezultata: 65%
N-gram (modifikacija 1)
Veličina indeksa: 170 MBIndex radno vrijeme: 32 s
Sat traženja: 39 ms / 46 ms
Ponovljivost rezultata: 63%
N-gram (modifikacija 2)
Veličina indeksa: 170 MBIndex radno vrijeme: 32 s
Sat traženja: 37 ms / 45 ms
Ponovljivost rezultata: 62%
Veličina indeksa: 85 MB
Sat otvaranja indeksa: 0,6 s
Sat traženja: 55 ms
Ponovljivost rezultata: 56,5%
BK-stabla
Veličina indeksa: 150 MBVrijeme izrade indeksa: 120 s
Sat traženja: 540 ms
Ponovljivost rezultata: 63%
Zajedno
Većina neizrazitih algoritama pretraživanja s indeksiranjem nije doista sublinearna (tako da može postojati asimptotski sat rada) O(log n) ili niže), a njihova fluidnost zahtijeva da leže u sredini N. Vrijeme nije manje, brojna poboljšanja i dodatna istraživanja omogućuju nam da postignemo dovoljno kratko vrijeme rada čak i za velike zadatke rječnika.Nedostaju i raznolike i neučinkovite metode, te podloge, između ostalog, za prilagodbu raznih, već stagnirajućih, tehnika i pristupa određenom predmetnom području. Među takvim metodama je prilagodba stabala prefiksa (Trie) stvaranju nejasne ideje, koja bi svojom niskom učinkovitošću lišila poziciju poštovanja. Postoje i algoritmi koji se temelje na originalnim pristupima, npr. algoritam Maassa-Nowak, što može biti sublinearni asimptotski sat rada, ali je izuzetno neučinkovito zbog velikih konstanti koje stoje iza takve satnice, a koje se pojavljuju u obliku velike veličine indeksa.
Praktična upotreba algoritama neizrazitog pretraživanja u stvarnim sustavima pretraživanja usko je povezana s fonetskim algoritmima, algoritmima leksičkog porijekla - viđenje osnovnog dijela različitih oblika riječi iste riječi (na primjer, takvu funkcionalnost pružaju Snowball i Yandex mystem), kao kao i rangiranja temeljena na statističkim informacijama ili s nizom složenih, sofisticiranih metrika.
- Levenshteinov pogled (s drugom verzijom i prefiksom);
- Vidstan Damerau-Levenshtein (s drugom verzijom i prefiksom);
- Bitap algoritam (Shift-OR/Shift-AND s Wu-Manber modifikacijama);
- Algoritam proširenja uzorkovanja;
- N-gramska metoda (izvorna i s izmjenama);
- Metoda raspršivanja potpisom;
- BK drvo.
Važno je napomenuti da sam u procesu proučavanja ovog procesa razvio ovlasti koje mi omogućuju da brzo ubrzam potragu za razumnim povećanjem veličine indeksa i bilo kakvu razmjenu slobode odabira metrike. Ali to je sasvim druga priča.
Semantička jezgra
Kako bi se uspješno razvila i povećala vidljivost stranice u današnjim okolnostima, potrebno je postupno proširivati semantičku jezgru. Jedan od najboljih načina za širenje je prikupljanje ključnih riječi od konkurenata.
Danas je teško razlučiti semantiku konkurenata jer... Postoji niz usluga, plaćenih i besplatnih.
Popis onih bez mačaka:
- megaindex.ru - alat "Vidljivost stranice".
- xtool.ru - univerzalna usluga koja također prikazuje ključne riječi za koje je stranica rangirana
Popis plaćenih:
- spywords.ru - pogodan za Yandex i Google
- semrush.ru - orijentacije samo pod Googleom
- prodvigator.ua - ukrajinski analog spywords.ru
Osim usluga, možete koristiti ručnu metodu, temeljenu na distribuciji naslova i opisa na n-gramima, što rezultira dodatnim popisom fraza.
N-gram - niz od n elemenata. Zapravo, N-gram se češće izoštrava na nižim razinama. Niz od dva uzastopna elementa često se naziva bigrama, naziva se niz od tri elementa trigram. Ne manje od četiri ili više elemenata označeno je kao N-grami, što znači da je N zamijenjen nizom sljedećih elemenata.
Pogledajmo tehniku korak po korak:
- Vivantizirati naslov (opis) natjecatelja. Dodatnu pomoć možete dobiti uz SEO program Screaming Frog.
- Uređivač teksta ima čistu listu najnovijih, kao što su službeni dijelovi jezika, znakovi odjeljenja i drugo. Koristim funkciju "pretraži i zamijeni" u uređivaču teksta sublime (tipka prečaca ctrl+H), s regularnim izrazima:
— Odaberemo željeni n-gram i postavimo frekvenciju na najmanje jedan. Najbolja opcija su i trigrami i 4 grama:

- Možemo odbiti trenutni rezultat:

Stovpetsračunatiprikazuje broj ponavljanjan-gram, stovpetsfrekvencija -Frekvencijan-grami.
Nakon što smo odabrali popis fraza, moramo ga analizirati i odabrati relevantne ključne riječi za proširenje semantičke jezgre. Izvješće se može pronaći u posebnom odjeljku našeg bloga.
Grupiranje upita
Vrlo je važno razumjeti kako je grupirana semantička jezgra konkurenata, jer To pomaže pravilnoj distribuciji ključnih fraza na stranicama web mjesta.
U tu svrhu, nakon što smo formirali novi popis upita, moramo odabrati relevantne stranice i pozicije konkurenata (možete koristiti seolib.ru), a zatim ih usporediti s našim grupama. Jasno je da konkurent zauzima dobru poziciju i u kojem slučaju se grupiranje razlikuje od našeg (npr. konkurent ima divizije na različitim stranama, a i mi moramo sjediti na jednoj), potrebno je povećati tržišni udio Molimo pogledajte odredišne stranice na vašoj web stranici.
Pogledajmo malu stražnjicu grupiranja mentalnog mjesta tog natjecatelja.
Kao što se može vidjeti iz tablice, web stranica site.ru ima jednu odredišnu stranicu za sve ključne riječi. Natjecatelj rangira različite stranice za ove upite i zauzima TOP ili pozicije blizu TOP-a. Polazeći od ovoga, možete doći do zaključka da grupiranje na site.ru treba pogledati, dok trebate napraviti bočnu stranicu za ključne fraze s riječju "fasada".
Sjaj teksta
Prije svega, važno je obratiti pozornost na analizu tekstova konkurenata, ali ne na veliki dio skladišta (također na broj inputa uključenih u tekst), već na jasan i smislen – koliko je vrijedan informacije koje trebam prenijeti ê konkurentu i kako raditi.
Pogledajmo hrpu guzica.
Moguće je da ste angažirani u isporuci karata na glavnu stranicu u tekstu i jamčenju njihove svježine. Na primjer, ovako:
Dostavamjesto. rujamči spremanje buketa tijekom hladne sezone.
I stražnja osovina jednog od natjecatelja:
Izrada mirisnih kompozicija s nama je jednostavna, jer jamčimo 100% povrat novčića, budući da je svježina ulaznica nesumnjiva.
Konkurentsko jamstvo potkrijepljeno je bagatelom, što je značajnije od apstraktnog jamstva.
Pogledajmo još jedan primjer - tekst na stranici kategorije "keramičke pločice" za online trgovinu:

Ovaj tekst ne nosi nikakvo korisno semantičko značenje, sutílna voda. Pa za sve, osoba koja dođe na stranicu i donese odluku o kupnji, želi se informirati o prednostima proizvoda i mogućim konfiguracijama, onda slijedi besprijekorno tipkanje znakova.
Čudimo se sada tekstu natjecatelja:

Ovaj tekst je smećkast, jer... jezgrovito informira o svestranosti pločica i pomaže vam razumjeti kako odabrati pravu.
Na taj način, uspoređujući tekstove svojih konkurenata sa svojima, možete izvući mnogo korisnih informacija koje će autorima tekstova pomoći pri sastavljanju tehničkih specifikacija.
Relevantnost tekstova
Nastavljajući temu tekstualnosti, ne može se ne ukazati na njihovu relevantnost. Danas, da bi tekst bio relevantan, nije dovoljno unijeti ključne riječi. Kako biste povećali relevantnost stranice i ne učinili tekst spamom, morate odabrati riječi povezane s temom.
Procjenjujući relevantnost traženog teksta za tekst, sustav pretraživanja analizira prisutnost ključnih riječi i dodatnih riječi koje se koriste za zamjenu teksta. Na primjer, ako pišemo tekst o slonu, onda uz povezane riječi možemo koristiti “surla”, “kljove”, “priroda”, “zoološki vrt”. Ako se tekst odnosi na lovca šah, onda će sljedeće riječi biti: figura, šah, dama itd.
Možete pronaći najprikladniji popis podudaranja za svoje upite iz tekstova vaših konkurenata. Zašto trebate izvršiti sljedeće korake:
— Sve tekstove iz TOP-10 nakon potrebnog HF unosa kopiramo u razne tekstualne datoteke.
— Iz tekstova se vide službeni dijelovi jezika, interpunkcijski znakovi i brojevi (pregledano).
— Stavljanje riječi u red — korištenje funkcije "pretraži i zamijeni" s regularnim izrazima. Zamijenite razmak s \n.
- Dalje, potrebno je sve oblike riječi dovesti u normalan oblik riječi (lemi). Za to možete brzo koristiti uslugu https://tools.k50project.ru/lemma/. U polje u koje trebate unijeti popis podataka iz svake datoteke, pritisnite tipku “Lemetiziraj i prikaži u CSV tablici”. Rezultat može biti 10 datoteka od lemetiziranih riječi.
— U datoteci kože vidljivi su duplikati riječi.
— Kombiniranje riječi iz datoteka u jedan popis.
- Sada morate izraditi frekvencijski rječnik. U tu svrhu, popis se dodaje na uslugu https://tools.k50project.ru/lemma/ i klikne se na "preuzmi rječnik frekvencija u CSV prikazu."
— Naš popis proizvoda gotovih za jelo:

Ako je učestalost 10, znači da je riječ vikorizirana na svih 10 stranica, ako ih ima 8, onda samo na 8 itd. Preporuča se odabir riječi s najvećom učestalošću, no usred riječi koje se rijetko preklapaju možete pronaći korisna rješenja.
Na ovaj jednostavan način možete odabrati popis tematskih riječi za sastavljanje tehničkih specifikacija za copywritere.
Čini se da su konkurenti vrlo važan izvor informacija koji vam mogu pomoći da bolje optimizirate svoje stranice. Nisam pokrio sve aspekte ovog članka, au bliskoj budućnosti ću pisati o dobrim stvarima koje možete oduzeti svojim konkurentima.
Pretplatite se na newsletter,
Pogledati na N-grami kao fiksacija moderne stvarnosti kao model konstrukta. Veze modela su odabrane N-gram i formalna gramatika. Respekt je vraćen na kratko vrijeme i trljanje, povezano s zlobnošću međunarodnih modela.
Unesi
Završimo s formalnostima. Radimo zadatke raspjevane abecede VT={wi), de wi- Poseban simbol. Bez faseta (redova) krajnjeg dovegina, koji se formiraju od simbola abecede VT, po abecedi zove moj VT i naznačeno je L(VT). Okremiy lanciuzhok z film L(VT) Zovemo to moja ljubav. U tvome srcu, N-gramu u Abetsiju VT zove se lanzyuzhok dovzhina N. N-Grama može izbjeći bilo kakve obveze, ako ste u redu ili nećete ući do L(VT).
Naciljajmo hrpu kundaka N-gram.
3. , N- Ruski grama. // Referentna zbirka.
4. Glanz. Medicinska i biološka statistika Prov. s engleskog po izd. V. M., 1999. (monografija).
5. Deskriptivna lingvistika. Peredmova na knjigu G. Gleasona "Uvod u deskriptivnu lingvistiku". M., 1959.
6. Lingvistika je teorijska i primijenjena. M., 1968.
8. , Pauza tijekom automatske sinteze filma. // Teorija i praksa znanstvenog istraživanja. M. 1999.
9. Minsky M. Prisutnost i logika spoznajne nepoznanice. // Novo u stranoj lingvistici. VIP. XXIII. M., 1988.
10. Slobin D., Green J. Psiholingvistika. M., 1976
11. Teorija viralnosti. M., 1972.
12. Fu Do. Strukturne metode prepoznavanja slika. M., 1977.
13. Harris T. Teorija epizodnih procesa, zbog čega je vruća. M., 1966.
14. Brill E. i u. Iznad N-grami: Može li lingvistička sofisticiranost poboljšati jezično modeliranje?
15. Booth T. Vjerojatnost reprezentacije formalnih jezika. // IEEE Annual Symp. Teorija sklopki i automata. 1969. godine.
16. Jelinek F. Samoorganizirano jezično modeliranje za prepoznavanje govora. // Čitanja u prepoznavanju govora. 1989. godine.
17. Jelinek F., Lafferty J. Izračunavanje vjerojatnosti početnog generiranja podniza pomoću stohastičke kontekstno-slobodne gramatike. //Computational Linguistics, sv.
18. Haris Z. S. Metoda u strukturalnoj lingvistici. Chicago, 1951.
19. Lashley K. Problem sa serijskim redoslijedom u ponašanju. // Psycholinguistics: A book of readings, N. Y. 1961.
20. Schlesinger E. Struktura rečenice i proces čitanja. Mouton. 1968. godine.
21. Shieber S. Dokazi o beskontaktnosti prirodnog jezika. // Lingvistika i filozofija, knj.
22. Sola bazen I. Trendovi u analizi sadržaja danas. // Psycholinguistics: A book of readings, N. Y. 1961
23. Stolcke A., Segal J. Virishenya vjerojatnosti n-grama iz stohastičkih gramatika bez konteksta. // Proceedings of the 32nd Annual Meeting of ACL. 1994. godine.
Korištenje N-grama
Zagalne upotrebe N-grama
- koristeći podatke za grupiranje niza satelitskih slika Zemlje iz svemira, kako bi se zatim odredilo koji su specifični dijelovi Zemlje na slici,
- traženje genetskih sekvenci,
- U području genetike provode se istraživanja kako bi se utvrdilo od kojih vrsta životinja prikupljaju uzorke DNK.
- u kompjuterskom stisku
- Iz odgovarajućih N-grama pozovite indeksirane podatke povezane sa zvukom.
N-grami se također široko koriste u uzorcima prirodnog jezika.
Vikoristannya N-gram za potrebe obrade prirodnog jezika
U području obrade prirodnog jezika N-grami se uglavnom koriste za prevođenje na temelju međunarodnih modela. Model N-grama određuje mogućnost preostale riječi N-gram jer sve znamo unaprijed. Kada se koristi ovaj pristup za modeliranje, jezik se prenosi tako da se izgled kožne riječi nalazi točno iznad prednjih linija.
U suprotnom, korištenje N-grama je znak plagijata. Dijeljenjem teksta na niz malih fragmenata, predstavljenih n-gramima, oni se mogu lako međusobno usporediti i na taj način ukloniti razinu sličnosti kontroliranih dokumenata. N-gram se često uspješno koristi za kategorizaciju teksta i jezika. Osim toga, mogu se koristiti za kreativne funkcije koje vam omogućuju izvlačenje znanja iz tekstualnih podataka. Pomoću N-grama možete učinkovito pronaći kandidate za zamjenu riječi s pravopisnim ustupcima.
Googleovi najnoviji istraživački projekti
Prethodni Googleovi istraživački centri razvili su modele N-grama za širok raspon istraživanja i razvoja. To uključuje projekte kao što je statističko prevođenje s jednog jezika na drugi, prepoznavanje jezika, ispravak pravopisa, prikupljanje informacija i još mnogo toga. Za potrebe ovih projekata korišteni su tekstovi korpusa koji sadrže trilijune riječi.
Google je odlučio izgraditi svoje sjedište. Projekt se zove Google teracorpus i sadrži 1.024.908.267.229 riječi prikupljenih s ilegalno dostupnih web stranica.
Metode dobivanja n-grama
U vezi s djelomičnom zamjenom N-grama za različite zadatke, potreban je pouzdan i fleksibilan algoritam za njihovo izdvajanje iz teksta. Dodatni alat za izdvajanje n-grama je zbog mogućnosti rada s tekstom nevezane veličine, obrade podataka i učinkovitog korištenja dostupnih resursa. Postoji niz metoda za izdvajanje N-grama iz teksta. Ove se metode temelje na različitim načelima:
Bilješke
div. također
Zaklada Wikimedia. 2010.
- n-tv
- N-kadherin
Pitam se što je "N-gram" u drugim rječnicima:
Gram- (francuski Gramme, grčki Gramma riža). Odinica francuski. vago = vago 1 kubni centimetar destilirane vode = 22,5 rosa. dijelovi. Rječnik stranih riječi koje su stigle u skladište ruskog jezika. Chudinov A.N., 1910. GRAM jedinica mira u Francuskoj... Rječnik stranih riječi ruskog jezika
gram- gram, ur. pl. grama i prihvatljivih (u uobičajenim promo nakon brojčanih) grama. Sto g (grama). Kako biste zaštitili novi obrazac, pročitajte. edmínka mn. Broj grama uveo je poznati pisac ruskog jezika K. Čukovski. Što je napisao u knjizi “Živjeti kao život”: ... Rječnik teških riječi i riječi u današnjem ruskom jeziku
Gram- GRAM, grama, čovječe. (U grčkom znak gramate, slovo). Glavna jedinica vode u metričkom sustavu jednaka je 1 kubnom centimetru vode. Gram je blizu 1/400 funti. ❖ Gram atom (fizički) broj grama govora koji je stariji od atomske vaze. Tlumačni rječnik Ušakova
gram rendgenski snimak- gram roentgen/n, gram roentgen/na, ed. pl. gram rendgen i gram rendgen... Dobro. Okremo. Kroz crticu.
gram- Gram, ova jednostavna riječ mogla bi se koristiti bez opravdanja za rječnik, kao da ne postoje dva uvjeta; Prije svega, ako se želite pohvaliti svojim apsolutno ispravnim jezikom, onda kada dođete u trgovinu pitajte prodavača ispravan: Pozdravite me dvjesta grama (ne... ... Rječnik oprosta na ruskom jeziku
GRAM-ATOM- GRAM ATOM, količina elementa, njegova masa, u gramima, jednaka je ATOMSKOJ MASI. Zamijenjena je jedinicom sustava SÍ mol. Na primjer, jedan gram atoma vode (H, atomska masa = 1) je ekvivalentan jednom gramu. b>GRAMSKI EKVIVALENT, vaga u gramima toga... ... Znanstveni i tehnički enciklopedijski rječnik
Gram- GRAM, ah, ur. pl. gram i gram, čovječe. Jedna masa u desetinom sustavu unosa, jedna tisućinka kilograma. Ni gram (ni)čega (neskladnog) nitroha, nimalo. Ti ljudi nemaju savjesti. | dodati. gram, oh, oh. Tlumačni... ... Tlumačni rječnik Ožegova
gram- A; pl. izd. grami i grami; m. [francuski] gramme] Jedinica mase u metričkom sustavu, tisućinka kilograma. ◊ Nema grama željeza. Anitrohi, nimalo dovoljno. Tko ima L. Ni gram neistine. Ni kod koga nema ni gram savjesti. * * * gram (francuski ... Enciklopedijski rječnik
Gram Zenob Théophile- (Gramme) (1826.-1901.), inženjer elektrotehnike. Rođen u Belgiji, porijeklom iz Francuske. Patentirajući praktični električni generator s prstenastom armaturom (1869). Zaspavši u industrijskoj proizvodnji električnih strojeva. * * * GRAM Zenob... ... Enciklopedijski rječnik
gram-atom- količina govora u gramima, brojčano jednaka atomskoj masi. Termin se ne preporuča koristiti. Imamo puno govora u noćnim leptirima. * * * GRAM ATOM GRAM ATOM, količina govora u gramima, brojčano je stariji od svoje atomske mase (div. ... Enciklopedijski rječnik
gram molekule- količina govora u gramima, brojčano jednaka njegovoj molekularnoj težini. Termin se ne preporuča koristiti. Imamo puno govora u noćnim leptirima. * * * GRAM MOLEKULA GRAM MOLEKULA, količina govora u gramima, brojčano je jednaka yo... Enciklopedijski rječnik