Лінійний пошук
Просте послідовне застосування заданої метрики (наприклад, метрики Левенштейна) до слів із вхідного тексту. При використанні метрики з обмеженням, цей метод дозволяє досягти оптимальної швидкості роботи. Але при цьому чим більше k, тим більше збільшується час роботи. Асимптотична оцінка часу - O(kn).Bitap (також відомий як Shift-Or або Baeza-Yates-Gonnet, та його модифікація від Wu-Manber)
Алгоритм Bitapта різні його модифікації найчастіше використовуються для нечіткого пошуку без індексації. Його варіація використовується, наприклад, в unix-утиліті agrep , виконує функції аналогічно стандартному grep , але із підтримкою помилок у пошуковому запиті і навіть надаючи обмежені можливості застосування регулярних висловів.Вперше ідею цього алгоритму запропонували громадяни Ricardo Baeza-Yatesі Gaston Gonnet, Опублікувавши відповідну статтю в 1992 році.
Оригінальна версія алгоритму має справу лише із замінами символів, і, фактично, обчислює відстань Хеммінга. Але трішки пізніше Sun Wuі Udi Manberзапропонували модифікацію цього алгоритму для обчислення відстані Левенштейна, тобто. привнесли підтримку вставок та видалень, та розробили на його основі першу версію утиліти agrep.

Результуюче значення
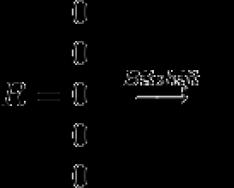
Де k- кількість помилок, j- Індекс символу, s x - маска символу (у масці поодинокі біти розташовуються на позиціях, що відповідають позиціям даного символу у запиті).
Збіг або розбіжність запиту визначається останнім бітом результуючого вектора R.
Висока швидкість роботи цього алгоритму забезпечується за рахунок бітового паралелізму обчислень - за одну операцію можна провести обчислення над 32 і більше бітами одночасно.
У цьому тривіальна реалізація підтримує пошук слів довжиною трохи більше 32. Це обмеження обумовлюється шириною стандартного типу int(На 32-бітних архітектурах). Можна використовувати і типи великих розмірностей, але це може уповільнити роботу алгоритму.
Незважаючи на те, що асимптотичний час роботи цього алгоритму O(kn)збігається з таким у лінійного методу, він значно швидше при довгих запитах та кількості помилок kпонад 2.
Тестування
Тестування здійснювалося на тексті 3.2 млн. слів, середня довжина слова - 10.Точний пошук
Час пошуку: 3562 мсПошук з використанням метрики Левенштейна
Час пошуку при k=2: 5728 мсЧас пошуку при k=5: 8385 мс
Пошук з використанням алгоритму Bitap з модифікаціями Wu-Manber
Час пошуку при k=2: 5499 мсЧас пошуку при k=5: 5928 мс
Очевидно, що простий перебір з використанням метрики, на відміну від алгоритму Bitap, залежить від кількості помилок. k.
Тим не менш, якщо мова заходить про пошук у незмінних текстах великого обсягу, то час пошуку можна значно скоротити, зробивши попередню обробку такого тексту, також звану індексацією.
Алгоритми нечіткого пошуку з індексацією (Оффлайн)
Особливістю всіх алгоритмів нечіткого пошуку з індексацією є те, що індекс будується за словником, складеним за вихідним текстом або списком записів у будь-якій базі даних.Ці алгоритми використовують різні підходи до вирішення проблеми - одні використовують зведення до точного пошуку, інші використовують властивості метрики для побудови різних просторових структур і так далі.
Насамперед, першому кроці за вихідним текстом будується словник, що містить слова та його позиції у тексті. Також можна підраховувати частоти слів та словосполучень для покращення якості результатів пошуку.
Передбачається, що індекс, як і словник, цілком завантажено на згадку.
Тактико-технічні характеристики словника
- Вихідний текст – 8.2 гігабайта матеріалів бібліотеки Мошкова (lib.ru), 680 млн слів;
- Розмір словника – 65 мегабайт;
- Кількість слів – 3.2 млн;
- Середня довжина слова – 9.5 символів;
- Середня квадратична довжина слова (може бути корисною при оцінці деяких алгоритмів) - 10.0 символів;
- Алфавіт - великі літери А-Я, без Е (для спрощення деяких операцій). Слова, що містять символи не з алфавіту, не включені до словника.

Алгоритм розширення вибірки
Цей алгоритм часто застосовується в системах перевірки орфографії (тобто в spell-checker"ах), там, де розмір словника невеликий, або де швидкість роботи не є основним критерієм.Він заснований на зведенні задачі про нечіткий пошук до задачі про точний пошук.
З вихідного запиту будується безліч помилкових слів, для кожного з яких потім проводиться точний пошук у словнику.

Час його роботи залежить від числа k помилок і зажадав від розміру алфавіту A, й у разі використання бінарного пошуку за словником становить:
Наприклад, при k = 1і слова довжини 7 (наприклад, «Крокодил») у російському алфавіті безліч помилкових слів буде розміром близько 450, тобто необхідно зробити 450 запитів до словника, що цілком прийнятно.
Але вже за k = 2розмір такої множини становитиме понад 115 тисяч варіантів, що відповідає повному перебору невеликого словника, або ж 1/27 у нашому випадку, і, отже, час роботи буде досить великим. При цьому не потрібно забувати ще й про те, що для кожного з таких слів необхідно здійснити пошук на точний збіг у словнику.
особливості:
Алгоритм може бути легко модифікований для генерації помилкових варіантів за довільними правилами, і, до того ж, не вимагає ніякої попередньої обробки словника, і, відповідно, додаткової пам'яті.Можливі покращення:
Можна генерувати не все безліч «помилкових» слів, а лише ті з них, які найімовірніше можуть зустрітися в реальній ситуації, наприклад, слова з урахуванням поширених орфографічних помилок чи наборів.Цей метод був придуманий досить давно, і є найбільш широко використовуваним, тому що його реалізація вкрай проста, і забезпечує досить хорошу продуктивність. Алгоритм ґрунтується на принципі:
"Якщо слово А збігається зі словом Б з урахуванням кількох помилок, то з великою часткою ймовірності у них буде хоча б один загальний підряд довжини N".
Ці підрядки довжини N і називаються N-грамами.
Під час індексації слово розбивається на такі N-грами, а потім слово потрапляє до списків для кожної з цих N-грам. Під час пошуку запит також розбивається на N-грами, і кожної з них проводиться послідовний перебір списку слів, які містять таку підрядок.

Найбільш часто використовуваними на практиці є триграми - підрядки довжини 3. Вибір більшого значення N веде до обмеження на мінімальну довжину слова, коли вже можливе виявлення помилок.
особливості:
Алгоритм N-грам знаходить в повному обсязі можливі слова з помилками. Якщо взяти, наприклад, слово ВОТКА, і розкласти його на триграми: ВО ТКА → ВО ТПро ТДо ТКА - можна помітити, що вони всі містять помилку Т. Таким чином, слово «ГОРОДКА» знайдено не буде, оскільки воно не містить жодної з цих триграм, і не потрапить у відповідні їм списки. Таким чином, чим менше довжина слова і чим більше в ньому помилок, тим вищий шанс того, що воно не потрапить до відповідних N-грам запиту списки, і не буде в результаті.Тим часом метод N-грам залишає повний простір для використання власних метрик з довільними властивостями і складністю, але за це доводиться платити - при його використанні залишається необхідність у послідовному переборі близько 15% словника, що досить багато для словників великого обсягу.
Можливі покращення:
Можна розбивати хеш-таблиці N-грам за довжиною слів і позиції N-грами в слові (модифікація 1). Як довжина шуканого слова та запиту не можуть відрізнятися більш ніж на k, і позиції N-грами в слові можуть відрізнятися лише на k. Отже, потрібно буде перевірити лише таблицю, відповідну позиції цієї N-грами у слові, і навіть k таблиць зліва і k таблиць праворуч, тобто. всього 2k+1сусідні таблиці.
Можна ще трохи зменшити розмір необхідної для перегляду множини, розбивши таблиці по довжині слова, і аналогічним чином переглядаючи тільки сусідні 2k+1таблиці (модифікація 2).
Цей алгоритм описано у статті Бойцова Л.М. "Хешування з сигнатури". Він базується на досить очевидному поданні «структури» слова у вигляді бітових розрядів, що використовується як хеш (сигнатура) в хеш-таблиці.
При індексації такі хеші обчислюються кожному за слів, й у таблицю заноситься відповідність списку словникових слів цього хешу. Потім, під час пошуку, для запиту обчислюється хеш і перебираються всі сусідні хеші, що відрізняються від вихідного не більше ніж в k бітах. Для кожного з таких хешей проводиться перебір списку відповідних слів.
Процес обчислення хешу - кожному біту хеша зіставляється група символів із алфавіту. Біт 1 на позиції iу хеші означає, що у вихідному слові є символ з i-ийгрупи алфавіту. Порядок букв у слові абсолютно не має значення.

Видалення одного символу або не змінить значення хешу (якщо в слові ще залишилися символи з тієї ж групи алфавіту), або відповідний цій групі біт зміниться в 0. При вставці, аналогічно або один біт встане в 1, або ніяких змін не буде. При заміні символів все трохи складніше - хеш може або залишитися незмінним, або ж зміниться в 1 або 2 позиціях. При перестановках жодних змін взагалі не відбувається, тому що порядок символів при побудові хеша, як і було помічено раніше, не враховується. Таким чином, для повного покриття k помилок потрібно змінювати щонайменше 2kбіт у хеші.

Час роботи, в середньому, при k «неповних» (вставки, видалення та транспозиції, а також мала частина замін) помилках: 
особливості:
З того, що при заміні одного символу можуть змінюватися відразу два біти, алгоритм, що реалізує, наприклад, спотворення не більше 2 бітів одночасно насправді не видаватиме повного обсягу результатів через відсутність значної (залежить від відношення розміру хешу до алфавіту) частини слів з двома замінами (і чим більший розмір хешу, тим частіше заміна символу призводитиме до спотворення відразу двох біт, і тим менш повним буде результат). До того ж цей алгоритм не дозволяє проводити префіксний пошук.BK-дерева
Дерева Burkhard-Kellerє метричними деревами, алгоритми побудови таких дерев ґрунтуються на властивості метрики відповідати нерівності трикутника:Ця властивість дозволяє метрикам утворювати метричні простори довільної розмірності. Такі метричні простори не обов'язково є евклідовими, так, наприклад, метрики Левенштейнаі Дамерау-Левенштейнаутворюють неевклідовіпростору. На підставі цих властивостей можна побудувати структуру даних, що здійснює пошук у такому метричному просторі, якою є дерева Баркхарда-Келлера.

Поліпшення:
Можна використовувати можливість деяких метрик обчислювати відстань з обмеженням, встановлюючи верхню межу, що дорівнює сумі максимальної відстані до нащадків вершини та результуючої відстані, що дозволить трохи прискорити процес:Тестування
Тестування здійснювалося на ноутбуці із Intel Core Duo T2500 (2GHz/667MHz FSB/2MB), 2Gb ОЗУ, ОС – Ubuntu 10.10 Desktop i686, JRE – OpenJDK 6 Update 20.
Тестування здійснювалося з використанням відстані Дамерау-Левенштейна та кількістю помилок k = 2. Розмір індексу вказаний разом із словником (65 Мб).
Розмір індексу: 65 Мб
Час пошуку: 320 мс / 330 мс
Повнота результатів: 100%
N-грам (оригінальний)
Розмір індексу: 170 МбЧас створення індексу: 32 с
Час пошуку: 71 мс / 110 мс
Повнота результатів: 65%
N-грам (модифікація 1)
Розмір індексу: 170 МбЧас створення індексу: 32 с
Час пошуку: 39 мс / 46 мс
Повнота результатів: 63%
N-грам (модифікація 2)
Розмір індексу: 170 МбЧас створення індексу: 32 с
Час пошуку: 37 мс / 45 мс
Повнота результатів: 62%
Розмір індексу: 85 Мб
Час створення індексу: 0.6 с
Час пошуку: 55 мс
Повнота результатів: 56.5%
BK-дерева
Розмір індексу: 150 МбЧас створення індексу: 120 с
Час пошуку: 540 мс
Повнота результатів: 63%
Разом
Більшість алгоритмів нечіткого пошуку з індексацією не є істинно сублінійними (тобто мають асимптотичний час роботи) O(log n)або нижче), та їх швидкість роботи зазвичай безпосередньо залежить від N. Тим не менш, множинні поліпшення та доопрацювання дозволяють досягти достатнього малого часу роботи навіть за дуже великих обсягів словників.Існує також безліч різноманітних і неефективних методів, заснованих, крім усього іншого, на адаптації різних, вже де-небудь застосовуваних технік і прийомів до даної предметної області. Серед таких методів - адаптація префіксних дерев (Trie) до завдань нечіткого пошуку, яку я залишив поза увагою через її малу ефективність. Але є й алгоритми, що базуються на оригінальних підходах, наприклад, алгоритм Маасса-Новака, який хоч і має сублінійний асимптотичний час роботи, але є вкрай неефективним через величезні константи, що ховаються за такою тимчасовою оцінкою, які проявляються у вигляді величезного розміру індексу.
Практичне використання алгоритмів нечіткого пошуку в реальних пошукових системах тісно пов'язане з фонетичними алгоритмами, алгоритмами лексичного стеммінгу - виділення базової частини у різних словоформ одного і того ж слова (наприклад, таку функціональність надають Snowball та Яндекс mystem), а також з ранжуванням на основі статистичної інформації , або з використанням складних витончених метрик.
- Відстань Левенштейна (з відсіканням та префіксним варіантом);
- Відстань Дамерау-Левенштейна (з відсіканням та префіксним варіантом);
- Алгоритм Bitap (Shift-OR/Shift-AND з модифікаціями Wu-Manber);
- Алгоритм розширення вибірки;
- Метод N-грам (оригінальний та з модифікаціями);
- Метод хешування за сигнатурою;
- BK дерева.
Варто зауважити, що в процесі вивчення цієї теми у мене з'явилися деякі власні напрацювання, що дозволяють на порядок скоротити час пошуку за рахунок помірного збільшення розміру індексу та деякого обмеження у свободі вибору метрик. Але це вже зовсім інша історія.
Семантичне ядро
Щоб успішно розвиватися та збільшувати видимість сайту у сучасних реаліях, необхідно постійно розширювати семантичне ядро. Одним із найкращих способів розширення є збір ключових слів конкурентів.
Сьогодні отримати семантику конкурентів нескладно, т.к. Існує безліч сервісів, як платних, і безкоштовних.
Список безкоштовних:
- megaindex.ru - інструмент "Видимість сайту"
- xtool.ru - всім відомий сервіс, який також показує ключові слова, за якими сайт ранжується
Список платних:
- spywords.ru - підходить для Яндекс та Google
- semrush.ru - орієнтований тільки під Google
- prodvigator.ua - український аналог spywords.ru
На додаток до сервісів можна використовувати і ручний метод, заснований на розбиття title та description на n-грами, внаслідок чого на виході виходить додатковий список фраз.
N-грама - послідовність з n елементів. Насправді частіше зустрічається N-грама як низку слів. Послідовність із двох послідовних елементів часто називають біграма, послідовність з трьох елементів називається триграма. Не менше чотирьох і вище елементів позначаються як N-грама, що N замінюється на кількість послідовних елементів.
Розглянемо цю методику за кроками:
- Вивантажуємо title (description) конкурентів. Можна зробити за допомогою програми Screaming Frog SEO.
— У текстовому редакторі чистимо список, що вийшов, від службових частин мови, розділових знаків та іншого сміття. Я використовую в текстовому редакторі sublime text функцію «пошук та заміна» (гаряча клавіша ctrl+H), застосовуючи регулярні вирази:
— Вибираємо потрібну n-граму та ставимо частоту не менше одного. Найоптимальніший варіант - це триграми та 4-грами:

- Отримуємо наступний результат:

Стовпецьcountпоказує кількість повтореньn-грам, стовпецьfrequency -Частотуn-грами.
Після того, як ми отримали список фраз, потрібно його проаналізувати та вибрати відповідні ключові слова для розширення семантичного ядра. Докладніше можна дізнатися у відповідному розділі нашого блогу.
Угруповання запитів
Дуже важливо розуміти, як групується семантичне ядро конкурентів, т.к. Це допомагає правильно розподілити ключові фрази на сторінках сайту.
Для цього після того, як ми сформували повний список запитів, нам необхідно отримати релевантні сторінки та позиції конкурентів (можна за допомогою seolib.ru), а потім порівняти зі своїм угрупуванням. Якщо видно, що конкурент займає хороші позиції і при цьому його угруповання відрізняється від нашого (наприклад, у конкурента запити розподілені на різні сторінки, а у нас такі ж запити сидять на одній), потрібно звернути на це увагу та переглянути посадкові сторінки на своєму сайті .
Розглянемо невеликий приклад порівняння угруповання умовного сайту та його конкурента.
Як видно з таблиці, на сайті site.ru обрано одну посадкову сторінку для всіх ключових слів. У конкурента за цими ж запитами ранжуються різні сторінки та займають ТОПові або близькі до ТОПу позиції. Виходячи з цього, можна дійти невтішного висновку, що угруповання на site.ru необхідно переглядати, зокрема необхідно створити окрему сторінку для ключових фраз зі словом «фасад».
Якість текстів
Перше та найважливіше, на що слід звертати увагу при аналізі текстів конкурентів, це не на кількісну складову (кількість входжень, обсяг тексту тощо), а на якісну чи смислову – наскільки корисна інформація, що пропонує конкурент і як він це робить.
Розглянемо кілька прикладів.
Допустимо, ви займаєтеся доставкою квітів і на головній сторінці в тексті ви гарантуєте їхню свіжість. Наприклад, так:
Служба доставки квітівsite. ruгарантує збереження букетів навіть у холодну пору року.
А ось приклад у одного із конкурентів:
Замовляти ароматні композиції вигідно саме у нас, тому що ми гарантуємо 100% повернення грошей, якщо свіжість квітів викликає сумнів.
У конкурента гарантія підкріплена грошима, що суттєвіше, ніж абстрактна гарантія.
Розглянемо ще один приклад – текст на сторінці категорії «керамічна плитка» інтернет-магазину:

Цей текст не несе жодного корисного смислового навантаження, суцільна вода. Швидше за все, людина, яка прийшла на сайт і приймає рішення про купівлю, хоче дізнатися про переваги товару та можливі комплектації, натомість вона отримує безглуздий набір символів.
Тепер подивимося на текст у конкурента:

Цей текст корисніший, т.к. лаконічно повідомляє про відмінності плитки та допомагає зрозуміти, як її правильно вибрати.
Таким чином, порівнюючи тексти конкурентів зі своїми, ви можете отримати багато корисної інформації, яка допоможе при складанні ТЗ копірайтерам.
Релевантність текстів
Продовжуючи тему якості текстів, не можна не торкнутися їхньої релевантності. Сьогодні для того, щоб текст був релевантним, недостатньо лише входження ключових слів. Щоб збільшити релевантність сторінки і не зробити текст спамним, потрібно використовувати слова, пов'язані з тематикою.
Оцінюючи релевантності тексту запиту пошукова система аналізує як наявність ключових слів, а й додаткові слова, визначаючи в такий спосіб зміст тексту. Наприклад, якщо ми пишемо текст про слона, то зв'язаними словами можна вважати «хобот», «бивні», «природа», «зоопарк». Якщо текст про шахову фігуру слон, то такими словами будуть: фігура, шах, ферзь і т.д.
Отримати найбільш підходящий список слів під ваші запити можна у текстах конкурентів. Для цього потрібно зробити наступні кроки:
— Копіюємо всі тексти з ТОП-10 за потрібним ВЧ запитом до різних текстових файлів.
— З текстів видаляємо службові частини мови, знаки пунктуації та цифри (розглядали раніше).
— Вибудовуємо слова в рядок — використовуємо функцію «пошук та заміна» із регулярними виразами. Замінюємо пробіл на \n.
- Далі необхідно привести всі словоформи до нормальної словникової форми (лемі). Для цього можна скористатися сервісом https://tools.k50project.ru/lemma/. У полі треба внести список слів з кожного файлу окремо та натиснути кнопку «леметизувати та вивести у вигляді csv‑таблиці». У результаті має вийти 10 файлів із леметизованими словами.
— У кожному файлі видаляємо дублікати слів.
— Об'єднуємо слова із файлів в один список.
- Тепер потрібно створити частотний словник. Для цього отриманий список додаємо до сервісу https://tools.k50project.ru/lemma/ і натискаємо «побудувати частотний словник у вигляді CSV».
— Наш список слів готовий:

Якщо частота 10, значить, дане слово використовувалося на всіх 10 сайтах, якщо 8, то тільки у 8-ми і т.д. Рекомендуємо використовувати найбільш частотні слова, однак і серед слів, що рідко зустрічаються, можна знайти цікаві рішення.
Ось у такий простий спосіб ви можете отримати список тематичних слів для складання ТЗ копірайтерам.
Як видно, конкуренти є дуже важливим джерелом інформації, яка допоможе краще оптимізувати ваші сайти. У цій статті я охопив далеко не всі аспекти, і в майбутньому продовжуватиму писати про те, що корисного і як можна отримати у ваших конкурентів.
Підписатися на розсилку,
Розглянуто N-грами як фіксації мовної реальності як і модельний конструкт. Розібрано зв'язок модельних N-грам та формальних граматик. Звернено увагу на недоліки та протиріччя, пов'язані з використанням імовірнісних моделей.
Вступ
Почнемо з формального визначення. Нехай заданий певний кінцевий алфавіт VT={wi), де wi-Особливий символ. Безліч ланцюжків (рядків) кінцевої довжини, що складаються із символів алфавіту VT, називається мовою на алфавіті VTі позначається L(VT). Окремий ланцюжок з мови L(VT)називатимемо висловлюванням цією мовою. В свою чергу, N-грамою на абетці VTназивається ланцюжок довжиною N. N-грама може збігатися з якимось висловлюванням, бути його підрядком або взагалі не входити до L(VT).
Наведемо кілька прикладів N-грам.
3. , N-грами російської. // Справжній збірник.
4. Гланц.Медико-біологічна статистика Пров. з англ. за ред. в. М., 1999.
5. Дескриптивна лінгвістика. Передмова до книги Г. Глісона "Введення в дескриптивну лінгвістику". М., 1959.
6. Теоретична та прикладна лінгвістика. М., 1968.
8. , Паузування при автоматичному синтезі мови. // Теорія та практика мовних досліджень. М. 1999.
9. Мінський М.Дотепність та логіка когнітивного несвідомого. // Нове у зарубіжній лінгвістиці. Вип. XXIII. М., 1988.
10. Слобін Д., Грін Дж.Психолінгвістика. М., 1976
11. Теорія імовірності. М., 1972.
12. Фу До.Структурні методи розпізнавання образів. М., 1977.
13. Харріс Т.Теорія випадкових процесів, що гілкуються. М., 1966.
14. Brill E. та ін. Beyond N-grams: Can lingustic sophistication improve language modeling?
15. Booth T. Probability Representation of Formal Languages. // IEEE Annual Symp. Switching and Automata Theory. 1969.
16. Jelinek F. Self-Organized Language Modeling для Speech Recognition. // Readings in Speech Recognition. 1989.
17. Jelinek F., Lafferty J. Computation of probability of initial substring generation by stochastic context-free grammar. //Computational Linguistics, vol.
18. Harris Z. S.Метод в Structural Linguistics. Chicago, 1951.
19. Lashley K.Проблема серійного ордеру в behavior. // Psycholinguistics: A book of readings, N. Y. 1961.
20. Schlesinger E. Sentence Structure and the Reading Process. Mouton. 1968.
21. Shieber S. Evidence доконтакту-freeness of natural language. // Linguistics and Philosophy, vol.
22. Sola Pool I. Trends in Content Analysis Today. // Psycholinguistics: A book of readings, N. Y. 1961
23. Stolcke A., Segal J.Вирішення n-gram probabilities from stochastic context-free grammars. // Proceedings of the 32th Annual Meeting of ACL. 1994.
Використання N-грам
Загальне використання N-грам
- витяг даних для кластеризації серії супутникових знімків Землі з космосу, щоб потім вирішити, які конкретні частини Землі на зображенні,
- пошук генетичних послідовностей,
- в галузі генетики використовуються для визначення того, з яких конкретних видів тварин зібрані зразки ДНК
- в комп'ютерному стиску
- з використанням N-грам, зазвичай індексовані дані, пов'язані зі звуком.
Також N-грами широко застосовують у обробці природної мови.
Використання N-грам для потреб обробки природної мови
В області обробки природної мови, N-грами використовується в основному для передбачення на основі моделей імовірнісних. N-грамова модель розраховує можливість останнього слова N-грама якщо відомі всі попередні. При використанні цього підходу для моделювання мови передбачається, що поява кожного слова залежить лише від попередніх слів.
Інше застосування N-грамів є виявлення плагіату. Якщо розділити текст на кілька невеликих фрагментів, представлених n-грамами, їх легко порівняти один з одним і таким чином отримати ступінь схожості контрольованих документів. N-грам, часто успішно використовується для категоризації тексту та мови. Крім того, їх можна використовувати для створення функцій, які дають змогу отримувати знання з текстових даних. Використовуючи N-грам, можна ефективно знайти кандидатів, щоб замінити слова з помилками правопису.
Науково-дослідні проекти Google
Дослідницькі центри Google використовували N-грамові моделі для широкого кола досліджень та розробок. До них відносяться такі проекти, як статистичний переклад з однієї мови на іншу, розпізнавання мови, виправлення орфографічних помилок, вилучення інформації та багато іншого. Для цілей цих проектів були використані тексти корпусів, що містять кілька трильйонів слів.
Google вирішила створити свій навчальний корпус. Проект називається Google teracorpus і містить 1 024 908 267 229 слів, зібраних із загальнодоступних веб-сайтів.
Методи для вилучення n-грамів
У зв'язку з частим використанням N-грамів на вирішення різних завдань, необхідний надійний і швидкий алгоритм вилучення їх із тексту. Придатний інструмент для вилучення n-грамів повинен мати можливість працювати з необмеженим розміром тексту, працювати швидко і ефективно використовувати наявні ресурси. Є кілька методів вилучення N-грамів із тексту. Ці методи ґрунтуються на різних принципах:
Примітки
Див. також
Wikimedia Foundation. 2010 .
- n-tv
- N-кадгерін
Дивитись що таке "N-грам" в інших словниках:
Грам- (Фр. Gramme, від грец. Gramma риса). Одиниця франц. ваги = вагою 1 кубічного сантиметра дистильованої води = 22,5 рос. часткам. Словник іншомовних слів, що увійшли до складу російської мови. Чудінов А.Н., 1910. ГРАМ одиниця міри ваги у Франції … Словник іноземних слів російської мови
грам- грам, рід. мн. грамів і допустимо (в усній промові після чисельних) грам. Сто г (грам). На захист нової форми рід. відмінка мн. Число грам виступив знавець російської мови письменник К. Чуковський. Ось що він писав у книзі «Живий як життя»: … Словник труднощів вимови та наголоси в сучасній російській мові
Грам- ГРАМ, грама, чоловік. (Від грец. gramma знак, літера). Основна одиниця ваги в метричній системі заходів, що дорівнює вазі 1 кубічного сантиметра води. Грам важить близько 1/400 фунтів. ❖ Грам атом (фіз.) число грамів речовини, що дорівнює його атомній вазі. Тлумачний словник Ушакова
грам-рентген- грам рентге/н, грам рентге/на, рід. мн. грам рентген та грам рентгенів … Добре. Окремо. Через дефіс.
грам- Грам, це просте слово можна було б і не наводити у словнику помилок, якби не дві обставини; по перше, якщо хочете блиснути абсолютно правильною мовою, то, прийшовши в магазин, приголомшіть продавця правильним: Зважте мені двісті грамів (не… … Словник помилок російської мови
ГРАМ-ATOM- ГРАМ ATOM, кількість елемента, маса якого, в грамах, дорівнює його АТОМНІЙ МАСЕ. Його замінила одиниця системи СІ моль. Наприклад, один грам атом водню (Н, атомна маса = 1) дорівнює одному граму. b>ГРАМ ЕКВІВАЛЕНТ, вага у грамах того… … Науково-технічний енциклопедичний словник
Грам- ГРАМ, а, рід. мн. грам та грамів, чоловік. Одиниця маси у десятковій системі заходів, одна тисячна частка кілограма. Ні грама (ні) чого (розг.) анітрохи, немає зовсім. У цієї людини (ні) ні грама совісті. | дод. грамовий, а, ое. Тлумачний… … Тлумачний словник Ожегова
грам- а; мн. рід. грамів та грам; м. [франц. gramme] Одиниця маси у метричній системі заходів, одна тисячна частка кілограма. ◊ Жодного грама немає. Анітрохи, немає зовсім. У кому л. ні грама фальші. Немає ні грама совісті у когось л. * * * грам (франц … Енциклопедичний словник
Грам Зеноб Теофіль- (Gramme) (1826-1901), електротехнік. Народився у Бельгії, працював у Франції. Отримав патент на практично придатний електричний генератор з кільцевим якорем (1869). Заснував промислове виробництво електричних машин. * * * ГРАМ Зеноб… … Енциклопедичний словник
грам-атом- кількість речовини в грамах, чисельно рівну її атомній масі. Термін не рекомендується вживати. У СІ кількість речовини виражають у молях. * * * ГРАМ АТОМ ГРАМ АТОМ, кількість речовини в грамах, чисельно дорівнює його атомній масі (див. … Енциклопедичний словник
грам-молекула- кількість речовини в грамах, чисельно рівну її молекулярній масі. Термін не рекомендується вживати. У СІ кількість речовини виражають у молях. * * * ГРАМ МОЛЕКУЛА ГРАМ МОЛЕКУЛА, кількість речовини в грамах, чисельно рівну його… Енциклопедичний словник